神经机器翻译技术、Attention与Seq2Seq、Transformer
主要特点:输出是单词序列而不是单个单词,并且可能输出序列的长度与输入序列的长度不同
机器翻译的实现过程 1. 数据预处理乱码处理
我们通常所用的空格是 \x20 ,是在标准ASCII可见字符 0x20~0x7e 范围内。 而 \xa0 属于 latin1 (ISO/IEC_8859-1)中的扩展字符集字符,代表不间断空白符nbsp(non-breaking space),超出gbk编码范围,是需要去除的特殊字符。
大小写转换
分词把字符串转换成单词组成的列表list
建立词典把单词组成的列表,转换成单词id组成的列表,还有词频
源语言和目标语言都需要建立词典
字符是无法直接输入到模型的,所以我们通常需要把数据转换成vector,转换的方法有很多,这里不做详细描述。
这里有个pad函数,是要限制输入的长度,因为我们需要输入的长度都必须一致,所以写了这个函数:
def pad(line, max_len, padding_token):
if len(line) > max_len:
return line[:max_len]
return line + [padding_token] * (max_len - len(line))
pad(src_vocab[source[0]], 10, src_vocab.pad)
如果超出了max_len,我们就截取到最大值,如果小于max_len,那么在多余的位置补上padding_token,通常设为0
Encoder-Decoderencoder:输入到隐藏状态
decoder:隐藏状态到输出

还记得上面提到的输入输出长度不一的问题吗? Encoder-Decoder模型框架就可以应对这个问题,Encoder中进行训练,得到隐藏状态,然后再把隐藏状态作为Decoder输入,在Decoder中输出结果.
Seq2Seq模型是按照 Encoder-Decoder框架设计的,目的就是输入一个序列,输出另一个序列
模型:训练

预测


上面的三张图片很好的解释了Seq2Seq模型的运作方式,我们把英语按序列顺序,输入到Encoder的RNN中,最后计算出一个hidden state,作为Decoder的隐藏状态输入,然后用法语数据作为输入X,训练出模型。
在预测中,输入英语句子,得到hidden state,用BOS作为Decoder的输入X,hidden state作为隐藏状态输入,一直计算知道遇见EOS,计算的时候,一个神经元的单词输出作为下一个神经元的输入X。Dense层是最后的翻译的输出层
def SequenceMask(X, X_len,value=0):
maxlen = X.size(1)
mask = torch.arange(maxlen)[None, :].to(X_len.device) < X_len[:, None]
X[~mask]=value
return X
SequenceMask函数是为了处理之前padding出来的多余的0,因为计算这些0的损失是没有意义的,所以使用函数去除它.
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
# pred shape: (batch_size, seq_len, vocab_size)
# label shape: (batch_size, seq_len)
# valid_length shape: (batch_size, )
def forward(self, pred, label, valid_length):
# the sample weights shape should be (batch_size, seq_len)
weights = torch.ones_like(label)
weights = SequenceMask(weights, valid_length).float()
self.reduction='none'
output=super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label)
return (output*weights).mean(dim=1)
MaskedSoftmaxCELoss是这里用的损失函数
Beam Search集束搜索
在生成每个时间步的单词,使用的是
贪心搜索算法:每一步都把得分最高的单词作为输出,可是有个缺点,就是只会得到当前的最优解,没有考虑前后语义是否连贯,没有考虑全局最优解。
维特比算法:把所有的单词都试一遍,然后找到整体得分最高的句子,但是搜索空间太大,计算难

所以提出集束搜索方法,结合了贪心搜索和维特比算法,ABCDE代表单词表里的单词,找到得分最高的两个,对于A和C的下一个词,从10个中又找两个,以此类推,
最后得到最好的两个候选句子。
这个2是因为我们把beam设成2
在Seq2Seq模型中,Decoder从Encoder中接受的唯一信息是最后一个隐藏状态,类似于输入序列总结的向量表示。 当输入较长的序列,一个向量非常难表达全部信息,会导致灾难性遗忘。 所以如果不是给decoder一个向量,而是给Decoder提供Encoder每个时间步的向量表示,是否会得到更好地结果呢?
注意力机制的简述注意力机制有两种类型:全局注意力、局部注意力
全局:使用所有编码器隐藏状态的注意力类型
局部:仅使用编码器隐藏状态的子集
seq2seq 原理:翻译器从头到尾读取德语文本。读取完成后,开始逐词将文本译成英文。如果句子非常长,它可能已经忘记了前文的内容
seq2seq+attention 原理:翻译器从头到尾读取德语文本并记录关键词,之后将文本译成英文。在翻译每个德语单词时,翻译器会使用记录的关键词。
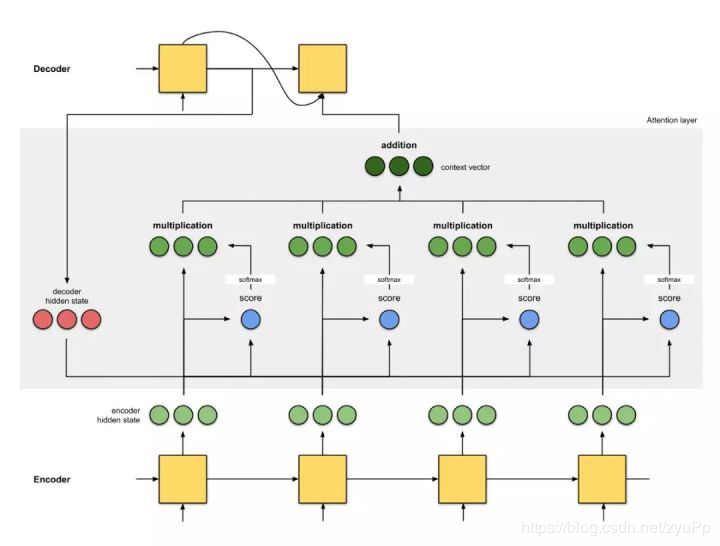
通过为每个单词分配分值,注意力为不同单词分配不同的注意力。然后利用 softmax 对编码器隐藏状态进行加权求和,得到上下文向量(context vector)。注意力层的实现可以分为 4 个步骤。
注意力是编码器和解码器之间的接口,它为解码器提供每个编码器隐藏状态的信息。这个做法有助于模型有选择性地侧重输入序列的有用部分,从而学习它们之间的 alignment,即原始文本片段匹配与其对应的译文片段,这样可以有效处理输入的长句子。
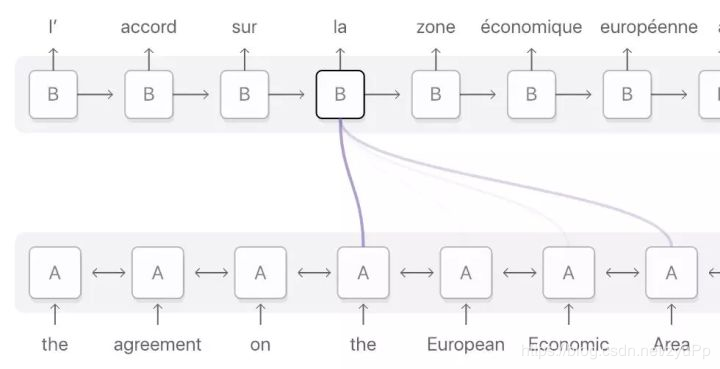
法语单词「la」的 alignment 分布在输入序列中,但主要分布在这四个词上:『the』、『European』、『Economic』 和 『Area』。深紫色表示注意力得分更高。
实现步骤准备隐藏状态
第一个Decoder单元的隐藏状态(query), 所有可用的Encoder隐藏状态(key)
获取每个Encoder的隐藏状态分数
有一个评分函数(alignment评分函数),这里使用Encoder和Decoder的隐藏状态之间的点积
通过softmax层运行所有分数
将得分放到softmax层,softmax得分和为1,softmax得分分布代表注意力分布
把得分与每个编码器隐藏状态(value)相乘,获得alignment向量
将 alignment 向量相加(加权求和),生成上下文向量 。上下文向量是前一步 alignment 向量的集合信息
将上下文向量输入解码器(结束)
计算query和key转置的乘积来计算attention score,通常还会除去d\sqrt{d}d减少计算出来的score对维度