【人工智能学习】【十二】机器翻译及相关技术
机器翻译(MT)是将一种语言转换成另一种语言,语言之间表达一个含义用的词汇量是不同的,之前讲到的RNN、LSTM、GRU【人工智能学习】【十一】循环神经网络进阶里的输出要么是多对多、要么多对一。参考【人工智能学习】【六】循环神经网络里的图。比如翻译“我我是中国人”——>“I am Chinese”,就会把5个字符翻译成3个词,这种前后不等长的问题是机器翻译要解决的问题。下面介绍Encoder-Decoder模型,在NLP中是一个非常基础的模型。
Encoder-Decoder模型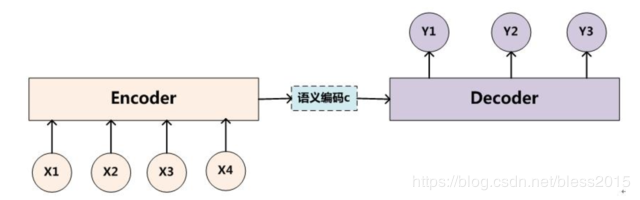
“Any problem in computer science can be solved by anther layer of indirection.”
“既然RNN那种神经网络模型无法解决这类问题,那就加一层。”
这个模型分为三部分,左侧是Encoder,从名字上看是一个编码作用,编码成中间的语义编码c,作为输入输入到右侧的Decoder中。
这个模型是一个框架思想,Encoder和Decoder可以用CNN、RNN来实现,比如【人工智能学习】【十】卷积神经网络进阶中的AlexNet、VGG、NiN、GoogLeNet,再比如【人工智能学习】【十一】循环神经网络进阶中的LSTM,GRU,Bi-LSTM,深度循环神经网络来做。所以Encoder-Decoder模型更像一种思想。
输入的序列XtX_tXt经过Encoder后,最终输出一个隐含层状态,这个状态我们可以在经过一个权重矩阵WWW来进行一个线性变换,得到语义语义编码ccc(context vector)。
c=f(H1,H2,H3……Ht,)c=f(H_1,H_2,H_3……H_t,)c=f(H1,H2,H3……Ht,)
也可以直接使用
C=f(Ht,)C=f(H_t,)C=f(Ht,)
学习机器学习要有抽象能力,模型产生的数据都看看哪些可以当做信息,可以拿来用一些就用。
decoder过程是使用encoder计算出来的隐藏状态HtH_tHt,经过一个WWW矩阵变换出来的序列ccc作为输出,来预测当前的输出符号yty_tyt,这里的yty_tyt和decoder里隐藏状态yhty_{ht}yht都与ccc和前一个输出有关。
y1=f(C)y_1=f(C)y1=f(C)
y2=f(C,Hy−1,y1)y_2=f(C,H_{y-1},y_1)y2=f(C,Hy−1,y1)
y3=f(C,Hy−1,y2)y_3=f(C,H_{y-1},y_2)y3=f(C,Hy−1,y2)
………………
当遇到终止字符时<EOS>就认为输出结束了。
这里有几种模式,请参考NLP(3)——seq to seq
总结:
定义Encoder
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
定义Decoder
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
# decoder的state初始值是encoder的最后一个神经元的state
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
定义模型
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
Sequence to Sequence模型
在机器翻译中,用的是基于Encoder-Decoder模型思想的Sequence to Sequence模型模型。
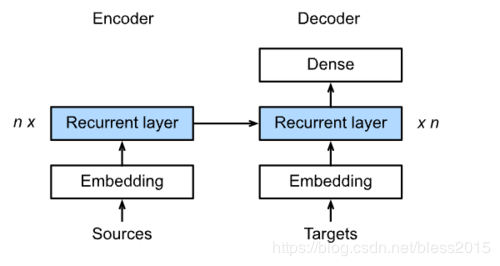
首先来看
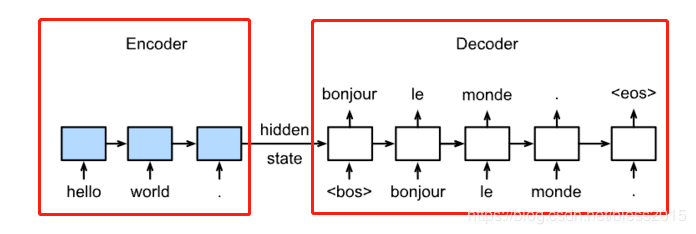
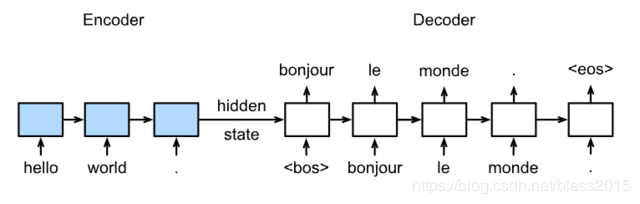
模型分Encoder和Decoder两部分,Encoder模型的初始化state为0,Decoder初始化state为Encoder的hidden state。Encoder顺序输入待翻译序列hello world,Decoder里它的法语翻译作为标签。
Decoder的第一个输入是<bos>,代表句子的开始字符,输出一个翻译结果bonjour,然后bonjour输入,得到下一个字符le(这个就类似之前【人工智能学习】【六】循环神经网络)的那个例子。直到网络遇到了<eos>,翻译结束。
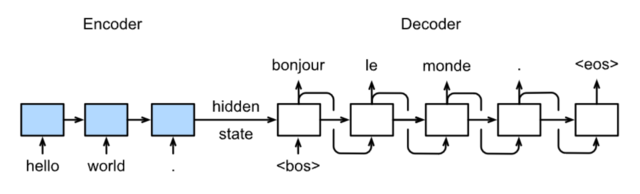
区别在于Decoder部分
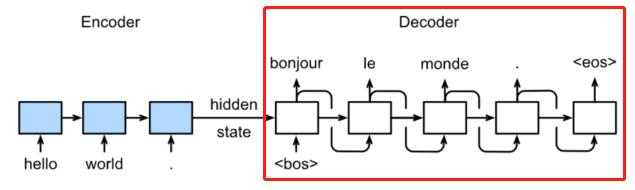
在预测时,Decoder的输入变成上一个神经元的输出。
Encoder用LSTM实现的
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.num_hiddens=num_hiddens
self.num_layers=num_layers
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
def begin_state(self, batch_size, device):
return [torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device),
torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)]
def forward(self, X, *args):
X = self.embedding(X) # X shape: (batch_size, seq_len, embed_size)
X = X.transpose(0, 1) # RNN needs first axes to be time
# state = self.begin_state(X.shape[1], device=X.device)
out, state = self.rnn(X)
# The shape of out is (seq_len, batch_size, num_hiddens).
# state contains the hidden state and the memory cell
# of the last time step, the shape is (num_layers, batch_size, num_hiddens)
return out, state
做一个输出
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8,num_hiddens=16, num_layers=2)
X = torch.zeros((4, 7),dtype=torch.long)
output, state = encoder(X)
output.shape, len(state), state[0].shape, state[1].shape
(torch.Size([7, 4, 16]), 2, torch.Size([2, 4, 16]), torch.Size([2, 4, 16]))
\
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
# 输出层
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
X = self.embedding(X).transpose(0, 1)
out, state = self.rnn(X, state)
# Make the batch to be the first dimension to simplify loss computation.
out = self.dense(out).transpose(0, 1)
return out, state
输出测试
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8,num_hiddens=16, num_layers=2)
state = decoder.init_state(encoder(X))
out, state = decoder(X, state)
out.shape, len(state), state[0].shape, state[1].shape
(torch.Size([4, 7, 10]), 2, torch.Size([2, 4, 16]), torch.Size([2, 4, 16]))
损失函数def SequenceMask(X, X_len,value=0):
maxlen = X.size(1)
mask = torch.arange(maxlen)[None, :].to(X_len.device) < X_len[:, None]
X[~mask]=value
return X
X = torch.tensor([[1,2,3], [4,5,6]])
SequenceMask(X,torch.tensor([1,2]))
tensor([[1, 0, 0],
[4, 5, 0]])
因为句子向量输入到RNN中,要保证是长度一致,所以短的句子要做padding,这时候padding的0是无效的损失,这部分损失不需要计算,所以需要SequenceMask函数来指定哪些向量的梯度是有效的。
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
# pred shape: (batch_size, seq_len, vocab_size)
# label shape: (batch_size, seq_len)
# valid_length shape: (batch_size, )
def forward(self, pred, label, valid_length):
# the sample weights shape should be (batch_size, seq_len)
weights = torch.ones_like(label)
weights = SequenceMask(weights, valid_length).float()
self.reduction='none'
output=super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label)
return (output*weights).mean(dim=1)
训练
def train_ch7(model, data_iter, lr, num_epochs, device): # Saved in d2l
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
tic = time.time()
for epoch in range(1, num_epochs+1):
l_sum, num_tokens_sum = 0.0, 0.0
for batch in data_iter:
optimizer.zero_grad()
X, X_vlen, Y, Y_vlen = [x.to(device) for x in batch]
Y_input, Y_label, Y_vlen = Y[:,:-1], Y[:,1:], Y_vlen-1
Y_hat, _ = model(X, Y_input, X_vlen, Y_vlen)
l = loss(Y_hat, Y_label, Y_vlen).sum()
l.backward()
with torch.no_grad():
d2l.grad_clipping_nn(model, 5, device)
num_tokens = Y_vlen.sum().item()
optimizer.step()
l_sum += l.sum().item()
num_tokens_sum += num_tokens
if epoch % 50 == 0:
print("epoch {0:4d},loss {1:.3f}, time {2:.1f} sec".format(
epoch, (l_sum/num_tokens_sum), time.time()-tic))
tic = time.time()
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.0
batch_size, num_examples, max_len = 64, 1e3, 10
lr, num_epochs, ctx = 0.005, 300, d2l.try_gpu()
src_vocab, tgt_vocab, train_iter = d2l.load_data_nmt(
batch_size, max_len,num_examples)
encoder = Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
model = d2l.EncoderDecoder(encoder, decoder)
train_ch7(model, train_iter, lr, num_epochs, ctx)
测试
def translate_ch7(model, src_sentence, src_vocab, tgt_vocab, max_len, device):
src_tokens = src_vocab[src_sentence.lower().split(' ')]
src_len = len(src_tokens)
if src_len < max_len:
src_tokens += [src_vocab.pad] * (max_len - src_len)
enc_X = torch.tensor(src_tokens, device=device)
enc_valid_length = torch.tensor([src_len], device=device)
# use expand_dim to add the batch_size dimension.
enc_outputs = model.encoder(enc_X.unsqueeze(dim=0), enc_valid_length)
dec_state = model.decoder.init_state(enc_outputs, enc_valid_length)
dec_X = torch.tensor([tgt_vocab.bos], device=device).unsqueeze(dim=0)
predict_tokens = []
for _ in range(max_len):
Y, dec_state = model.decoder(dec_X, dec_state)
# The token with highest score is used as the next time step input.
dec_X = Y.argmax(dim=2)
py = dec_X.squeeze(dim=0).int().item()
if py == tgt_vocab.eos:
break
predict_tokens.append(py)
return ' '.join(tgt_vocab.to_tokens(predict_tokens))
Beam Search(集束搜索)
在测试中,Decoder输出的是所有词的词向量的概率向量,我们如何知道该把哪个词输入到下一个呢?直观上一定是概率最大的那个。这样是一个贪心算法原理。
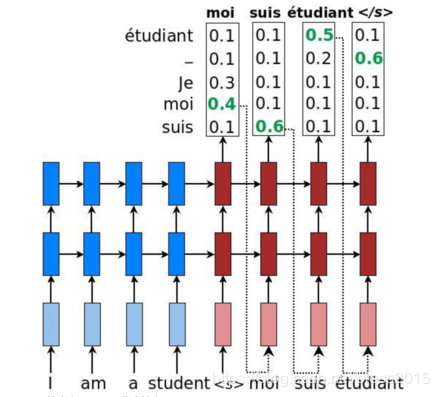
但是这样只考虑一个局部最优了,并没有考虑上下文之间是否最优,句子是否通顺。Beam Search(集束搜索)可以来缓解这个问题。Beam Search有一个超参数阈值nnn。在第一步的时候,我们通过模型计算得到yty_tyt的分布概率,选择前nnn个作为候选结果,将这nnn个候选结果在输入到Decoder中,会继续得到单词的分布概率,取最好的,然后将第一次和第二次的词组合起来再输入到Decoder中,重复操作。
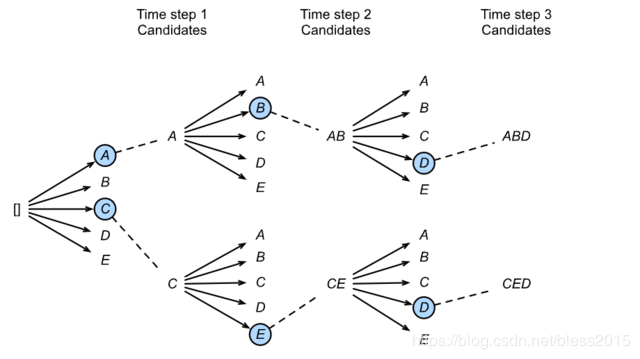
本质是一个条件概率。
作者:番茄发烧了