深度学习入门-4(机器翻译,注意力机制和Seq2seq模型,Transformer)
机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同(主要困难)。
2、数据的处理预处理
将数据集清洗、转化为神经网络的输入minbatch
在数据预处理的过程中,我们首先需要对数据进行清洗,即去除特殊字符(乱码)。
分词
单词(字符串)组成的列表
建立词典
单词组成的列表—单词id组成的列表
载入数据集
3、机器翻译组成模块 (1)Encoder-Decoder框架(编码器-解码器)Encoder-Decoder 即 编码器-解码器,可以理解是一个设计范式,常应用在Sequence to Sequence模型中。
Encoder和Decoder部分可以是任意的文字,语音,图像,视频数据,模型可以采用CNN、RNN、LSTM、GRU、BLSTM等等。所以基于Encoder-Decoder,我们可以设计出各种各样的应用算法。
作用:用来解决输入、输出不等长的问题,常用在机器翻译、对话系统和生成式任务中。
encoder:输入到隐藏状态 decoder:隐藏状态到输出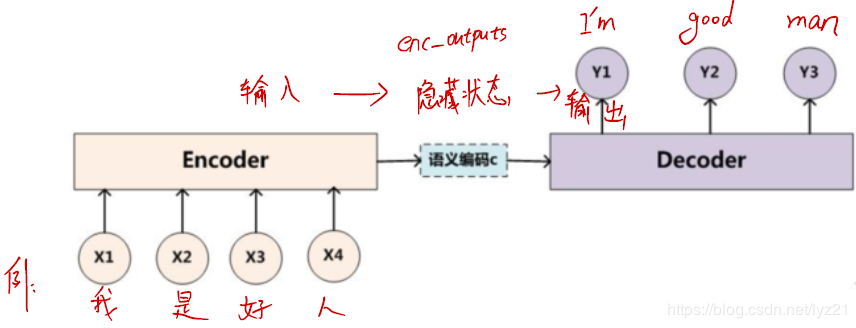 (2)Sequence to Sequence模型
(2)Sequence to Sequence模型
sequence to sequence模型是一类End-to-End的算法框架,也就是从序列到序列的转换模型框架,是输出的长度不确定时采用的模型。
Seq2Seq一般是通过Encoder-Decoder(编码-解码)框架实现。
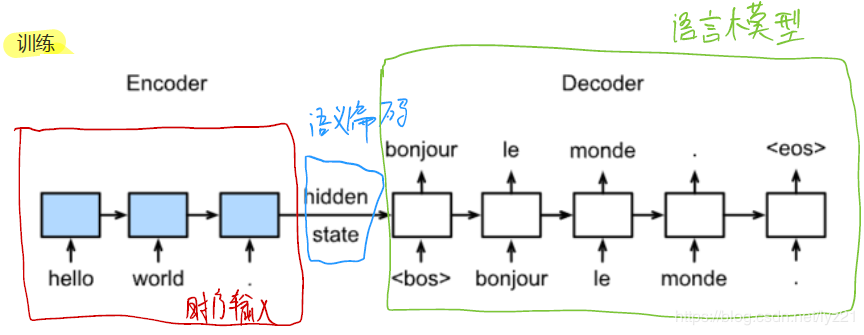
训练时的模型:
预测时的模型:
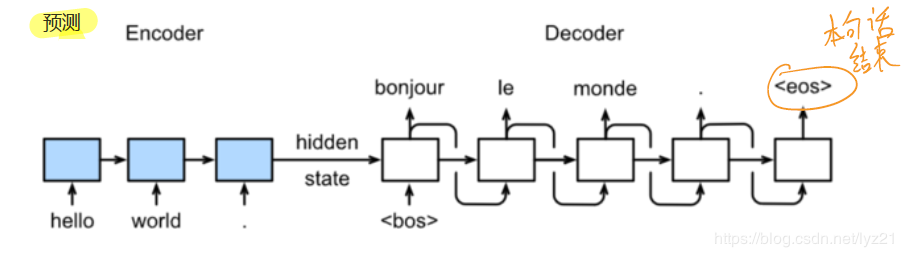
其中Encoder和Decoder都是循环神经网络。
具体结构:
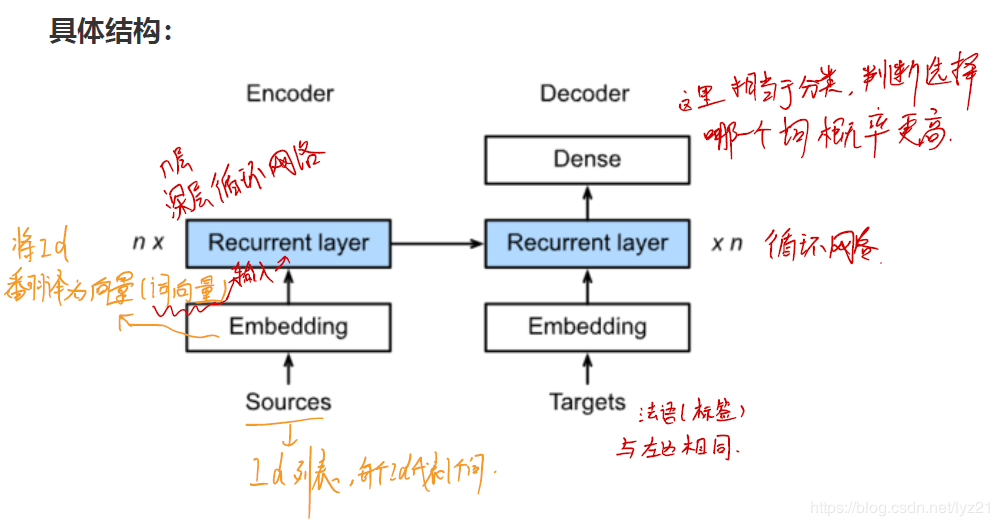
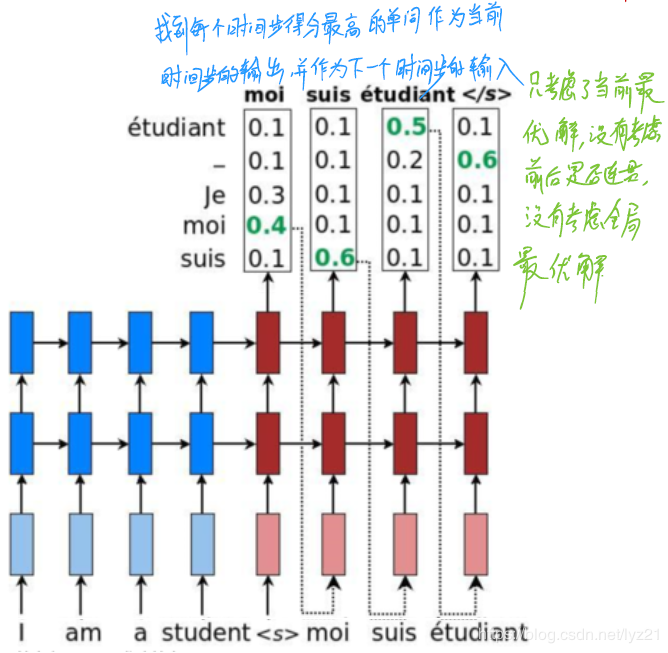
作用:生成每个时间步的单词。(上图解释了每个单词的生成都相当于做了分类)
(ⅰ)简单贪心搜索(greedy search)贪心算法找到的是局部最优解而非全局最优解
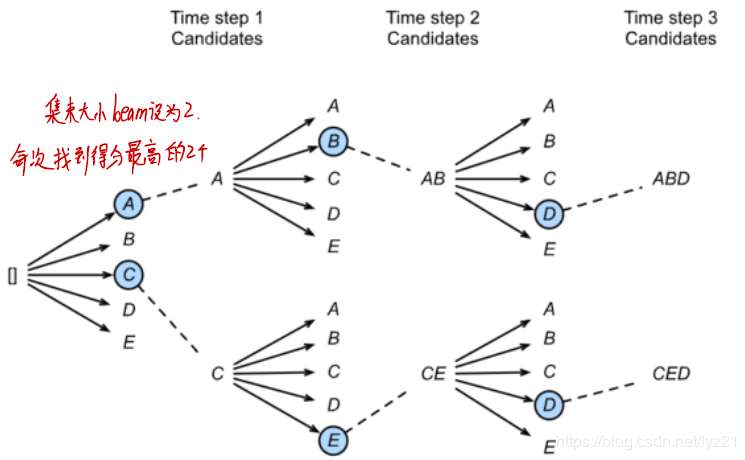
将所有单词都试一遍,选择整体分数最高的句子,即全局最优解。
缺点:搜索空间太大
(ⅲ)维特比算法贪心算法与维特比算法的结合体,是维特比搜索的贪心形式,属于贪心算法,也就是说不能完全得到全局最优解。
以较少的代价在相对受限的搜索空间中找出其最优解,得出的解接近于整个搜索空间中的最优解。
编码器—解码器(seq2seq)的不足:
随着所需翻译句子的长度的增加,这种结构的效果会显著下降 在seq2seq模型中,解码器只能隐式地从编码器的最终状态中选择相应的信息 2、注意力机制框架目的:解决以seq2seq的不足,将选择过程显示建模。
Attention 是一种通用的带权池化方法.
输入由两部分构成:询问(query)和键值对(key-value pairs)。
对于一个query来说,attention layer 会与每一个key计算注意力分数并进行权重的归一化,输出的向量o则是value的加权求和,而每个key计算的权重与value一一对应。
Attention步骤:
计算注意力分数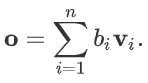
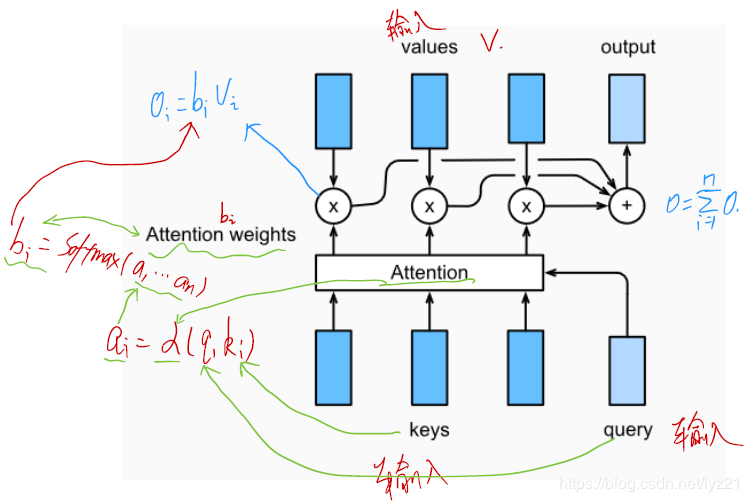
不同的注意力计算分数是不同的注意力层的主要区别。
(1)点积注意力(The dot product )The dot product 假设query和keys有相同的维度,通过计算query和key转置的乘积来计算attention score,通常还会除去维度d的平方根减少计算出来的score对维度