Flume学习笔记
Flume的运行机制
讲述的为Flume运行原理(但是没有注上源码讲解)
Flume--大数据环境中的搬运工,是非常重要的一环,对它的深入研究可以更加的优化我们的项目,
首先从flume的官网中我得到了一张图
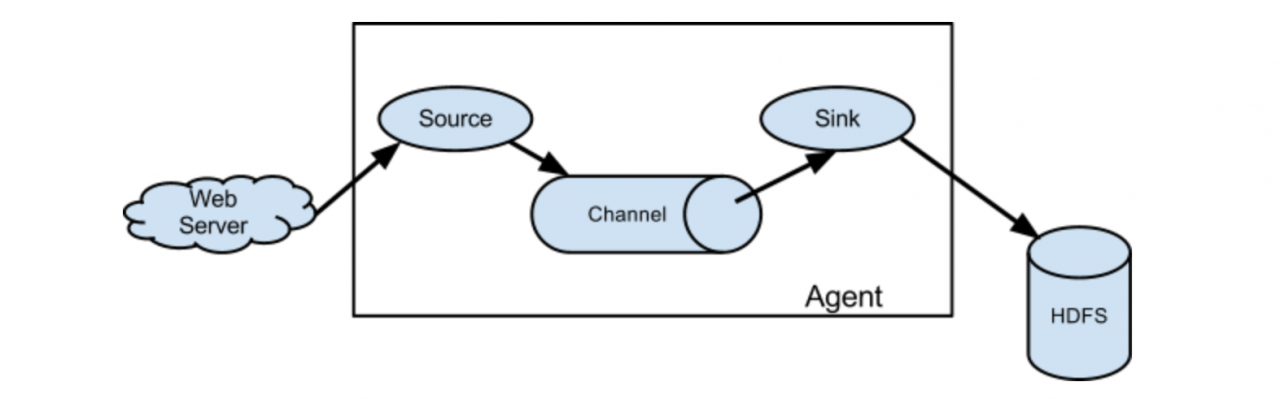
从官方给的这张图来看,flume的基本组件为Source-Channel-Sink,首先我先从纯字面上理解,他们三是干什么的,Source(从哪里获得),Channel(通道),Sink(沉槽)
其实他们的字面意思与他们的功能是大体相致的。
Flume的数据单位是event
Source:读取数据的组件,数据收集的作用 Channel:管道,数据流通道 Sink:数据发送好的了,闲话少说,我们直接上图
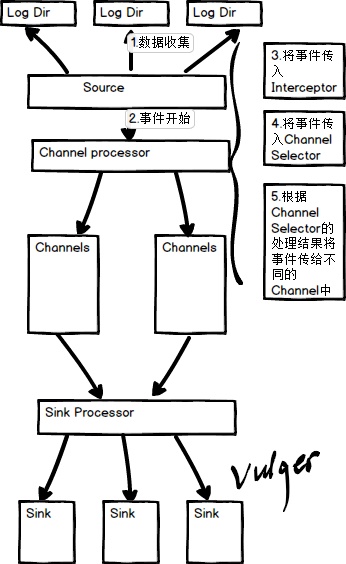
我对上图的理解就是三个基本,一拦,一选,一处理
三个基本没什么好说的就是source,channel,sink
一拦:就是拦截器,拦截器是很重要的,在实际开发中
我们利用拦截器做一些简单的ETL处理(但不宜做复杂的,毕竟做传输用的) 我们可以在拦截器中根据event(事件)的Body不同的特点添加入不同的header,便让下一级的选择器将event根据我们在此所添加的header分入不同的channel中一选:就是选择器,选择器厂家为我们提供了两种选择器
默认的选择器,event发给各个channel Multiplexing Channel Selector,多路选择器(重要),根据conf文件中的配置,将相对应的header分给不同的channel一处理:即Sink processor,厂家提供了三种
默认的Sink Processor 原则上就是传给一个Sink LoadBalancingSink Processor 负载均衡将event发给一个sink组(附:如果当sink组中的sink挂掉了,将如何处理呢?loadBalancing退避原则:如响应时间超过设定的时间,那么将此sink列入失败队列,这里有意思的就是:它的判定失败的时间将呈指数型增长) Failover 处理器,高可用,在一个sink组,只有一个sink工作,其余的都是standby,当工作的action挂掉以后,启动一个standby继续工作 Flume事务看图直观;
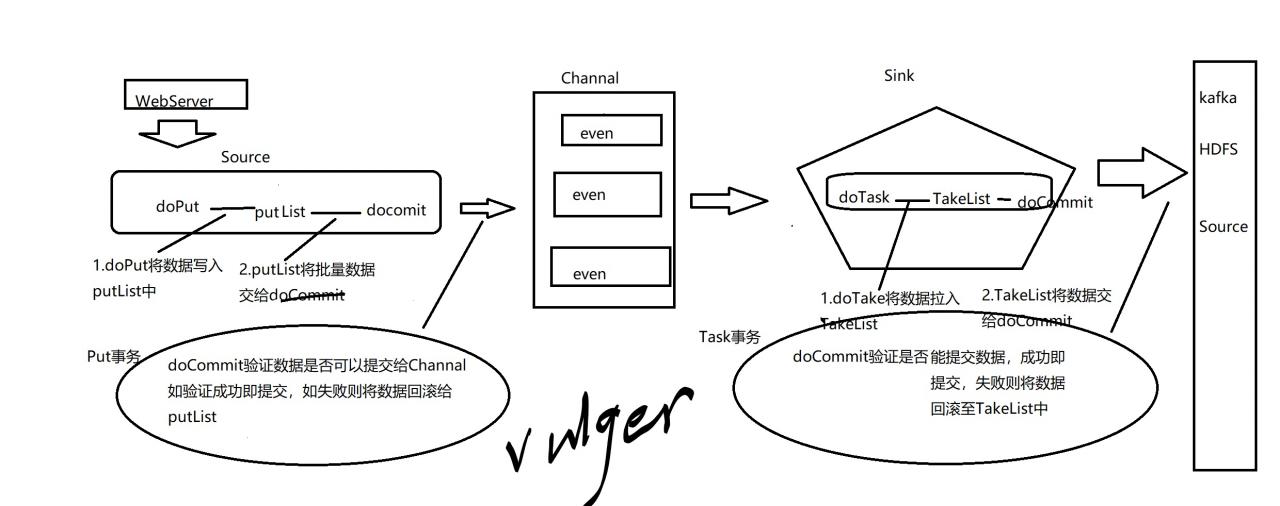
由上图可知:flume是具有事务的,因此它是不会丢数据的高可靠数据传输框架
注:图上手写体为作者签名
作者:静谭水月