Flume安装和简单使用
来自官网
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.
简单来说就是一个把日志进行采集汇总传输的框架
Flume安装安装路径:https://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.12.0.tar.gz
解压 配置java环境 配置Flume环境变量 Flume框架A Flume agent is a (JVM) process
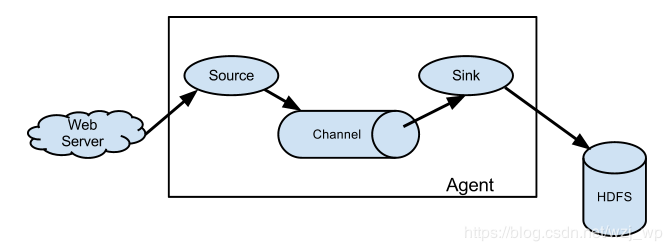
Flume agent 包括:Source Channel Sink
avro 序列化
exec 命令行
spooling 目录
taildir
kafka Channel常用类型
memory
kafka
file Sink常用类型
hdfs
logger 控制台
avro
kafka 示例
选型1:Source:NetCat Source | Sink:Logger Sink | Channel:memory
将44444端口的数据输出到控制台
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/script/netcatsource.conf \
-Dflume.root.logger=INFO,console
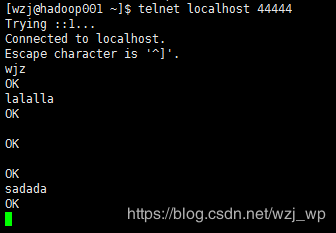
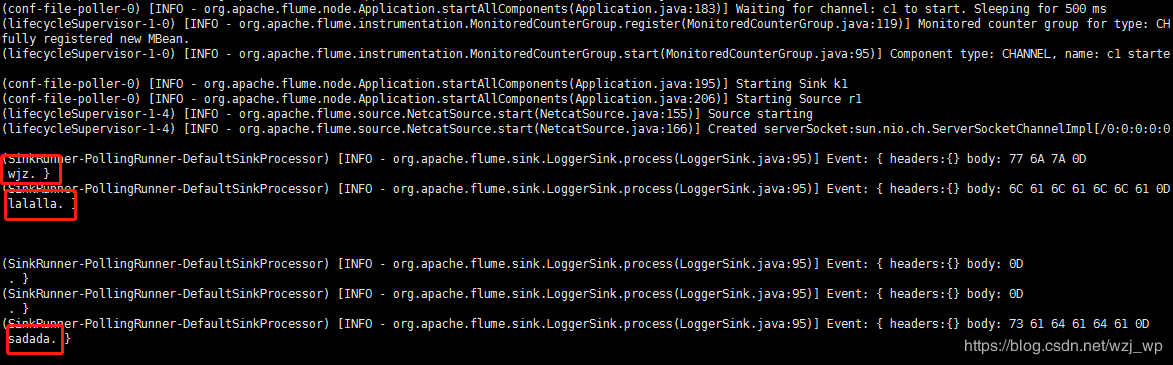
启动44444telnet localhost 44444
注意先后顺序,先启端口会报错
选型2:Source:exec Source | Sink:HDFS Sink | Channel:memory
监控某个文件,将数据传入HDFS
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/wzj/data/flume/data.log
a1.sources.r1.shell = /bin/sh -c
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/tail
a1.sinks.k1.hdfs.batchSize = 10
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/script/flume-exec-hdfs.conf \
-Dflume.root.logger=INFO,console
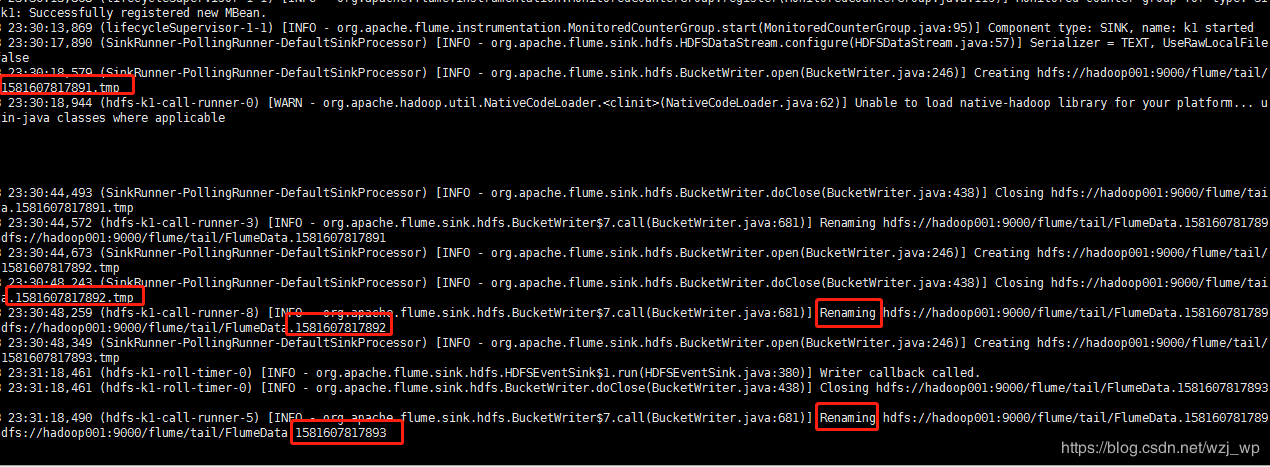
往/home/wzj/data/flume/data.log文件中追加数据观察控制台信息和hdfs文件中的变化:
选型3:Source:spooldir Source | Sink:HDFS Sink | Channel:memory
监控某个文件夹,将数据传入HDFS
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/wzj/data/flume/spool
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop001:9000/flume/spool/%Y%m%d%H%M
a1.sinks.k1.hdfs.batchSize = 10
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.filePrefix = wzj-
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.channels.c1.type = memory
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动flume
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/script/flume-spool-hdfs.conf \
-Dflume.root.logger=INFO,console
作者:jerrfy_w