Flume用法
Flume包含三部分
Source:从哪收集,一般使用:avro(序列化),exec(命令行),spooling(目录),taildir(目录和文件,包含offset,不会数据丢失),kafka
Channel:数据存哪里:(memory,kafka,file)
Sink:数据输出到哪里:(hdfs,logger,avro,kafka)
Flume环境配置
配置jdk
作者:jim8973
cd $FLUME_HOME/conf
cp flume-env.sh.template flume-env.sh
vi flume-env.sh
export JAVA_HOME=/usr/java/jdk
方法使用
netcat-logger:采集数据到控制台
vi netcat-logger.conf
# Name the components on this agent
# source的名字
a1.sources = r1
# sink的名字
a1.sinks = k1
# channel的名字
a1.channels = c1
# Describe/configure the source 定义source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44404
# Use a channel which buffers events in memory 定义channel
a1.channels.c1.type = memory
# Descripe the sink 定义sink
a1.sinks.k1.type = logger
# Bind the sources and sink to the channel
# 定义source和channel的连线
a1.sources.r1.channels = c1
# 定义sink的channel的连线
a1.sinks.k1.channel = c1
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/script/netcat-logger.conf \
-Dflume.root.logger=INFO,console

上图的Event: Flume数据传输的基本单元 event ==> flume ==>dst
header:可选的,是一组(k,v)形式的数据
body:字节数组,即是数据
exec-hdfs: 监控文件,通过命令采集数据到hdfs上
vi exec-hdfs.conf
a1.sources = r1
# sink的名字
a1.sinks = k1
# channel的名字
a1.channels = c1
# Describe/configure the source 定义source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/ruoze/data/flume/ruozedata_wc.txt
a1.sources.r1.shell = /bin/sh -c
# Use a channel which buffers events in memory 定义channel
a1.channels.c1.type = memory
# Descripe the sink 定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ruozedata001:9000/ruozedata/flume/tail
# 多少事件写入到文件,在文件刷到hdfs之前
a1.sinks.k1.hdfs.batchSize = 10
# hdfs上文件类型使用SequenceFile要配置压缩格式
a1.sinks.k1.hdfs.fileType = DataStream
# hdfs上文件格式,生产上配置Text
a1.sinks.k1.hdfs.writeFormat = Text
# Bind the sources and sink to the channel
# 定义source和channel的连线
a1.sources.r1.channels = c1
# 定义sink的channel的连线
a1.sinks.k1.channel = c1
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/script/exec-hdfs.conf \
-Dflume.root.logger=INFO,console
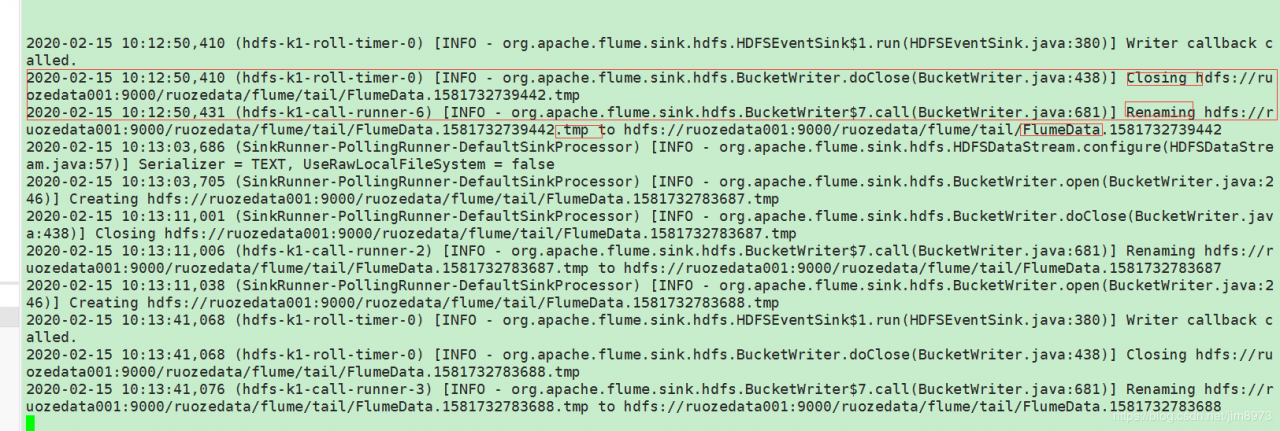
缺点:1、没有offset,脚本挂了,数据就要重新收集了;
2、hdfs上生成的都是小文件
小文件需要根据生产上数据量测试如下参数,达到合理的值
hdfs.rollInterval 30 多长时间滚动一次
hdfs.rollSize 1024 文件多大滚动一次
hdfs.rollCount 10 多少事情写到文件中滚动一次
监控目录:spool-hdfs
vi spool-hdfs.conf
a1.sources = r1
# sink的名字
a1.sinks = k1
# channel的名字
a1.channels = c1
# Describe/configure the source 定义source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/ruoze/data/flume/spool
# Use a channel which buffers events in memory 定义channel
a1.channels.c1.type = memory
# Descripe the sink 定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ruozedata001:9000/ruozedata/flume/spool/%Y%m%d%H%M
# 一个批次写入hdfs数据,默认100条
a1.sinks.k1.hdfs.batchSize = 10
# hdfs上文件类型使用SequenceFile要配置压缩格式
a1.sinks.k1.hdfs.fileType = DataStream
# hdfs上文件格式,生产上配置Text
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.useLocalTimeStamp = true
# Bind the sources and sink to the channel
# 定义source和channel的连线
a1.sources.r1.channels = c1
# 定义sink的channel的连线
a1.sinks.k1.channel = c1
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/script/spool-hdfs.conf \
-Dflume.root.logger=INFO,console
缺点:没有offset
重要生产使用选型:source =Taildir
不会有数据的丢失,因为设置了offset,同时支持文件和文件夹
vi taildir-logger.conf
a1.sources = r1
# sink的名字
a1.sinks = k1
# channel的名字
a1.channels = c1
# Describe/configure the source 定义source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /home/ruoze/data/flume/taildir_position.json
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /home/ruoze/data/flume/taildir/test1/example.log
a1.sources.r1.headers.f1.headerKey1 = value1
a1.sources.r1.filegroups.f2 = /home/ruoze/data/flume/taildir/test2/.*log.*
a1.sources.r1.headers.f2.headerKey1 = value2
a1.sources.r1.headers.f2.headerKey2 = value2-2
a1.sources.r1.fileHeader = true
a1.sources.ri.maxBatchCount = 1000
# Use a channel which buffers events in memory 定义channel
a1.channels.c1.type = memory
# Describe the sink <== 定义sink
a1.sinks.k1.type = logger
# Bind the sources and sink to the channel
# 定义source和channel的连线
a1.sources.r1.channels = c1
# 定义sink的channel的连线
a1.sinks.k1.channel = c1
flume-ng agent \
--name a1 \
--conf $FLUME_HOME/conf \
--conf-file $FLUME_HOME/script/taildir-logger.conf \
-Dflume.root.logger=INFO,console
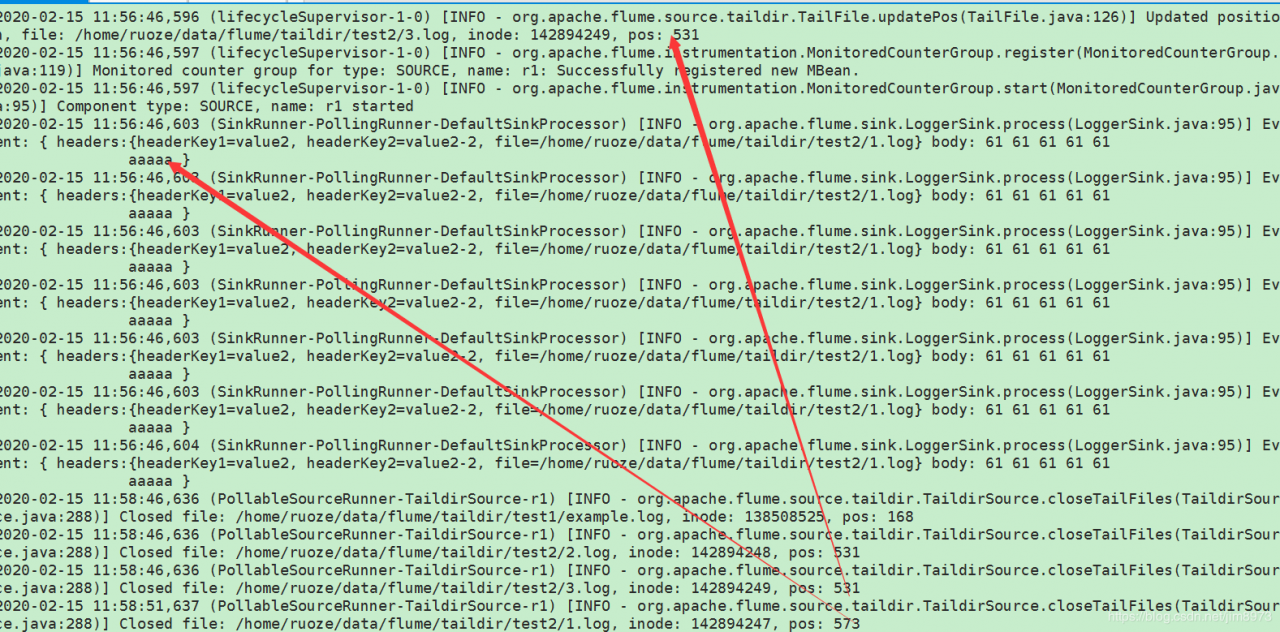
在taildir_position.json会记录相应的offset

启动脚本挂了,也会重新读取

作者:jim8973