Kaggle比赛系列:(6)Sklearn应用:data-science-london-scikit-learn
1、先使用一个简单的模型,得到一个baseline,在此基础上改进:输入特征标准化、特征降维等;
2、这里出现了GMM算法,其实际作用是对输入特征进行了后验概率的预测,构建了新的输入特征(使同一类的特征距离更短,聚类作用)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from subprocess import check_output
import warnings
warnings.filterwarnings('ignore')
print(check_output(['ls',"input"]).decode("utf8"))
test.csv
train.csv
trainLabels.csv
1、 read_csv注意原文件有没有header,没有header,赋值None
train = pd.read_csv("input/train.csv",header=None)#不读字段头
trainLabel = pd.read_csv("input/trainLabels.csv", header=None)
test = pd.read_csv("input/test.csv", header=None)
plt.style.use('ggplot')
print(train.shape)
print(trainLabel.shape)
print(test.shape)
(1000, 40)
(1000, 1)
(9000, 40)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score,train_test_split
X, y = train,trainLabel
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size = 0.3)
方法一:KNN n_neigbors参数网格搜索
2、使用KNN算法的时候,对neighbors的值可以采用网格搜索
3、np.arange().reshape()常搭配一起使用
4、model训练的数据集是经过train_test_split划分之后的训练集,而计算准确率的时候,是对整个训练数据集
neig = np.arange(1,25)#np.arange 不是 np.range
kfold = 10
train_accuracy = []
val_accuracy = []
bestknn = None
bestAcc = 0.0
for i,k in enumerate(neig):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train, y_train)#这里是train_test_split之后的训练特征和标签
train_accuracy.append(knn.score(x_train, y_train))
val_scores = cross_val_score(knn,X, y, cv = kfold)#这里是整个训练集的特征和标签
val_acc = val_scores.mean()
val_accuracy.append(val_acc)
if val_acc > bestAcc:
bestAcc = val_acc
bestknn = knn
plt.figure(figsize = (13,8))
plt.plot(neig,val_accuracy, label = "Validation Acurracy")
plt.plot(neig,train_accuracy, label = "Train Accuracy")
plt.legend(loc = "best")
plt.title("K value VS Accuracy")
plt.xlabel("K value")
plt.ylabel("Accuracy")
plt.xticks(neig)
plt.show()
print(bestAcc)
print(bestknn)
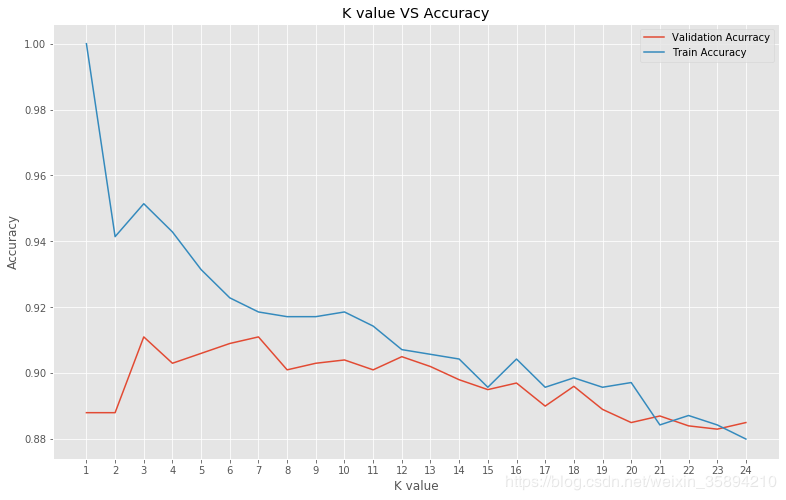
0.9109999999999999
KNeighborsClassifier(algorithm=‘auto’, leaf_size=30, metric=‘minkowski’,
metric_params=None, n_jobs=None, n_neighbors=3, p=2,
weights=‘uniform’)
submission = pd.Series(bestknn.predict(test), name = 'Soluton')
Id = pd.Series(np.arange(1,len(test)+1),name = 'Id')
submission = pd.concat([Id,submission], axis = 1)
submission.to_csv("submission_knn3.csv",index = False)
standscaler:标准化(正态分布)
minmaxscaler:区间化[0,1]
normalizer:正则化(l1 或 l2)
方法二:三种归一化(特征缩放)改进KNN
5、三种数据特征缩放的方法:standarscaler():标准化;Minmaxscaler():[0,1]区间化;Normalizer()默认为L2正则化
from sklearn.preprocessing import StandardScaler,MinMaxScaler,Normalizer#矩阵
std = StandardScaler()
X_std = std.fit_transform(X)
mms = MinMaxScaler()
X_mms = mms.fit_transform(X)
norm = Normalizer()
X_norm = norm.fit_transform(X)
6、计算accuracy的时候使用交叉验证
neig = np.arange(1,30)
kfold = 10
val_accuracy = {'std':[],'mms':[],'norm':[]}
bestknn = None
bestAcc = 0.0
bestScaling = None
for i,k in enumerate(neig):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(x_train, y_train)
s1 = np.mean(cross_val_score(knn,X_std,y,cv=kfold))
val_accuracy['std'].append(s1)
s2 = np.mean(cross_val_score(knn,X_mms,y, cv=kfold))
val_accuracy['mms'].append(s2)
s3 = np.mean(cross_val_score(knn,X_norm,y,cv=kfold))
val_accuracy['norm'].append(s3)
if s1 > bestAcc:
bestAcc = s1
bestknn = knn
bestScaling = 'std'
elif s2 > bestAcc:
bestAcc = s2
bestknn = knn
bestScaling = 'mms'
elif s3 > bestAcc:
bestAcc = s3
bestknn = knn
bestScaling = 'norm'
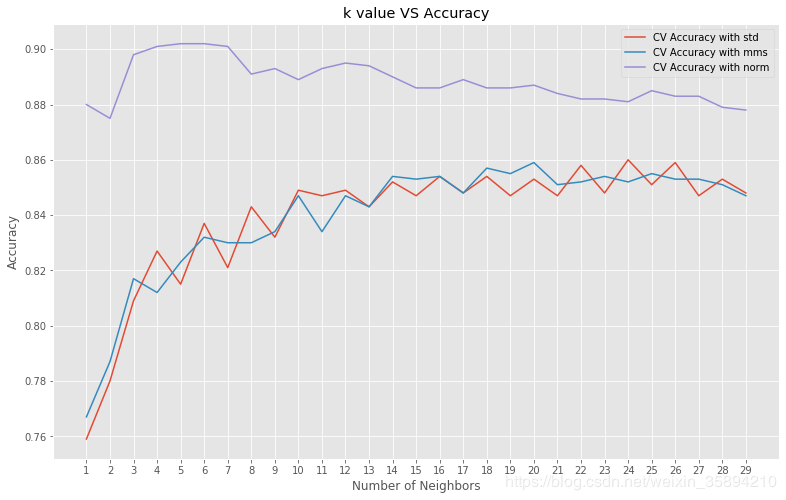
plt.figure(figsize = (13,8))
plt.plot(neig,val_accuracy['std'], label = 'CV Accuracy with std')
plt.plot(neig,val_accuracy['mms'], label = 'CV Accuracy with mms')
plt.plot(neig, val_accuracy['norm'], label = 'CV Accuracy with norm')
plt.legend()
plt.title('k value VS Accuracy')
plt.xlabel('Number of Neighbors')
plt.ylabel('Accuracy')
plt.xticks(neig)
plt.show()
print('Best Accuracy with feature scaling:', bestAcc)
print('Best kNN classifier:', bestknn)
print('Best scaling:', bestScaling)
bestknn.fit(X_norm,y)
Solution = pd.Series(bestknn.predict(norm.transform(test)),name = 'Solution')
Id = pd.Series(np.arange(1,len(test)+1), name = 'Id')
submission = pd.concat([Id,Solution], axis = 1)
submission.to_csv("submission_knn_norm.csv", index = False)
Best Accuracy with feature scaling: 0.9019999999999999
Best kNN classifier: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform')
Best scaling: norm
改进三:特征降维(这里使用了SVM分类方法,但是没有生成最终的提交文件)
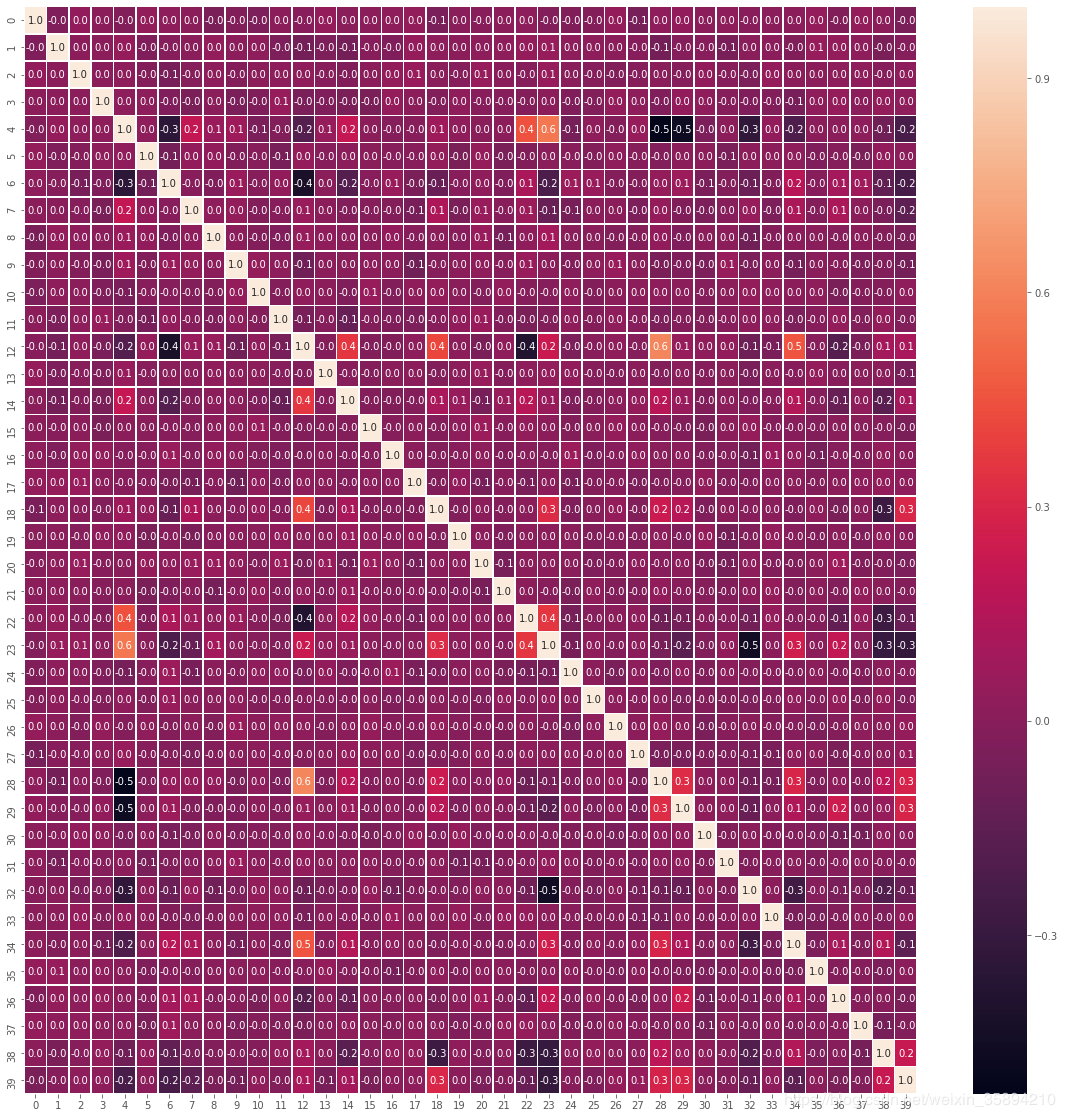
7、绘制热力图的data.corr()参数要求数据类型为DataFrame;fmt参数,保留小数点位数
f,ax = plt.subplots(figsize=(20,20))
p = sns.heatmap(pd.DataFrame(X_std).corr(), annot = True, linewidths=.5, fmt = '.1f',ax = ax)
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import f1_score, confusion_matrix,accuracy_score
X_train,X_val, y_train,y_val = train_test_split(X_std, y, test_size = 0.3, random_state=42)
clf_rf = RandomForestClassifier(random_state=43)
clf_rf = clf_rf.fit(X_train, y_train)#都是划分的训练集训练, 而不是从全体训练集训练
ac = accuracy_score(y_val, clf_rf.predict(X_val))#这里没有使用交叉验证,使用的是accuracy_score(metrics)
print('Accuracy is:{0}'.format(ac))
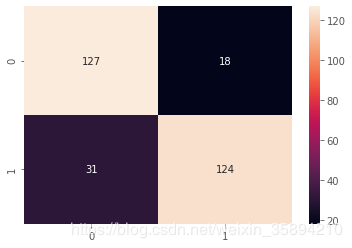
cm = confusion_matrix(y_val, clf_rf.predict(X_val))
sns.heatmap(cm,annot =True, fmt="d")
Accuracy is:0.8366666666666667
from sklearn.svm import SVC
from sklearn.feature_selection import RFECV
kfold = 10
bestSVC = None
bestAcc = 0.0
val_accuracy = []
cv_range = np.arange(5,11)
n_feature = []
for cv in cv_range:
svc = SVC(kernel="linear")
rfecv = RFECV(estimator=svc, step=1,cv=cv,scoring='accuracy')
rfecv.fit(X_std,y)
val_accuracy += [np.mean(cross_val_score(svc, X_std[:,rfecv.support_], y, cv=kfold))]#等同于append()
n_feature.append(rfecv.n_features_)
if val_accuracy[-1] > bestAcc:
bestAcc = val_accuracy[-1]
10、绘制折线图并在每个拐点设置标签plt.annotate(标签,位置)
plt.figure(figsize=[13,8])
plt.plot(cv_range,val_accuracy, label = 'CV Accuracy')
for i in range(len(cv_range)):
plt.annotate(str(n_feature[i]), xy = (cv_range[i], val_accuracy[i]))
plt.legend()
plt.title('Cross Validation Accuracy')
plt.xlabel('k fold')
plt.ylabel('Accuracy')
plt.show()
print('Best Accuracy with feature scaling and RFECV:', bestAcc)
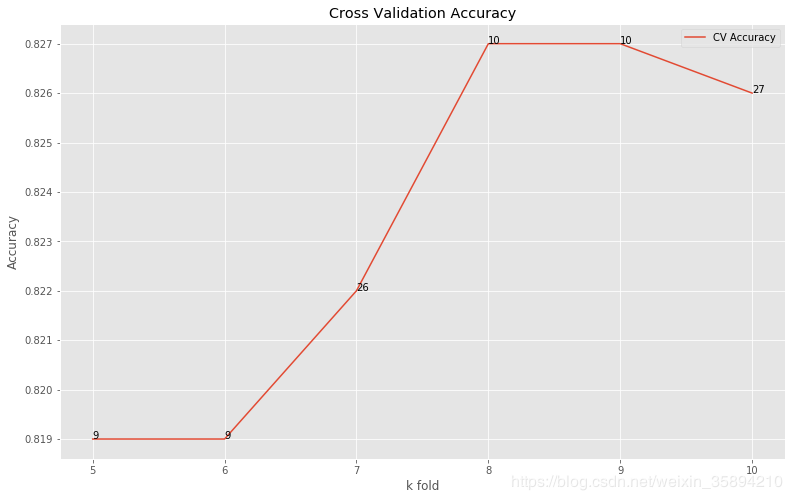
Best Accuracy with feature scaling and RFECV: 0.827
改进4:GMM输入特征预处理
疑问:使用网格搜索方法,但是没给搜索参数?
grid_search_knn.best_estimator_;
grid_search_knn.best_estimator_.score(x_train,y_train)
import numpy as np
#import sklearn as sk
#import matplotlib.pyplot as plt
import pandas as pd
#from sklearn.linear_model import LogisticRegression
#from sklearn.linear_model import Perceptron
#from sklearn import tree
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.ensemble import VotingClassifier
#from sklearn import svm
#### READING OUR GIVEN DATA INTO PANDAS DATAFRAME ####
x_train = train
y_train = trainLabel
x_test = test
x_train = np.asarray(x_train)
y_train = np.asarray(y_train)
x_test = np.asarray(x_test)
y_train = y_train.ravel()
print('training_x Shape:',x_train.shape,',training_y Shape:',y_train.shape, ',testing_x Shape:',x_test.shape)
#Checking the models
x_all = np.r_[x_train,x_test]#列相同拼接(行拼接)
#np.c_[]行相同拼接(列拼接)
print('x_all shape :',x_all.shape)
#使用GMM预测数据的最大后验概率
#### USING THE GAUSSIAN MIXTURE MODEL ####
from sklearn.mixture import GaussianMixture
lowest_bic = np.infty
bic = []
n_components_range = range(1, 7)
cv_types = ['spherical', 'tied', 'diag', 'full']
for cv_type in cv_types:
for n_components in n_components_range:
# Fit a mixture of Gaussians with EM
gmm = GaussianMixture(n_components=n_components,covariance_type=cv_type)
gmm.fit(x_all)
bic.append(gmm.aic(x_all))
if bic[-1] < lowest_bic:
lowest_bic = bic[-1]
best_gmm = gmm
best_gmm.fit(x_all)
x_train = best_gmm.predict_proba(x_train)
x_test = best_gmm.predict_proba(x_test)
#### TAKING ONLY TWO MODELS FOR KEEPING IT SIMPLE ####
knn = KNeighborsClassifier()
rf = RandomForestClassifier()
param_grid = dict( )
#### GRID SEARCH for BEST TUNING PARAMETERS FOR KNN #####
grid_search_knn = GridSearchCV(knn,param_grid=param_grid,cv=10,scoring='accuracy').fit(x_train,y_train)
print('best estimator KNN:',grid_search_knn.best_estimator_,'Best Score', grid_search_knn.best_estimator_.score(x_train,y_train))
knn_best = grid_search_knn.best_estimator_
#### GRID SEARCH for BEST TUNING PARAMETERS FOR RandomForest #####
grid_search_rf = GridSearchCV(rf, param_grid=dict( ), verbose=3,scoring='accuracy',cv=10).fit(x_train,y_train)
print('best estimator RandomForest:',grid_search_rf.best_estimator_,'Best Score', grid_search_rf.best_estimator_.score(x_train,y_train))
rf_best = grid_search_rf.best_estimator_
knn_best.fit(x_train,y_train)
print(knn_best.predict(x_test)[0:10])
rf_best.fit(x_train,y_train)
print(rf_best.predict(x_test)[0:10])
#### SCORING THE MODELS ####
print('Score for KNN :',cross_val_score(knn_best,x_train,y_train,cv=10,scoring='accuracy').mean())
print('Score for Random Forest :',cross_val_score(rf_best,x_train,y_train,cv=10,scoring='accuracy').max())
### IN CASE WE WERE USING MORE THAN ONE CLASSIFIERS THEN VOTING CLASSIFIER CAN BE USEFUL ###
#clf = VotingClassifier(
# estimators=[('knn_best',knn_best),('rf_best',rf_best)],
# #weights=[871856020222,0.907895269918]
# )
#clf.fit(x_train,y_train)
#print clf.predict(x_test)[0:10]
##### FRAMING OUR SOLUTION #####
knn_best_pred = pd.DataFrame(knn_best.predict(x_test))
rf_best_pred = pd.DataFrame(rf_best.predict(x_test))
#voting_clf_pred = pd.DataFrame(clf.predict(x_test))
knn_best_pred.index += 1
rf_best_pred.index += 1
#voting_clf_pred.index += 1
rf_best_pred.columns = ['Solution']
rf_best_pred['Id'] = np.arange(1,rf_best_pred.shape[0]+1)
rf_best_pred = rf_best_pred[['Id', 'Solution']]
print(rf_best_pred)
#knn_best_pred.to_csv('knn_best_pred.csv')
rf_best_pred.to_csv('Submission_rf.csv', index=False)
#voting_clf_pred.to_csv('voting_clf_pred.csv')
training_x Shape: (1000, 40) ,training_y Shape: (1000,) ,testing_x Shape: (9000, 40)
x_all shape : (10000, 40)
best estimator KNN: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=5, p=2,
weights='uniform') Best Score 0.996
Fitting 10 folds for each of 1 candidates, totalling 10 fits
[CV] ................................................................
[CV] .................................... , score=1.000, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=1.000, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=1.000, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=0.990, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=1.000, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=1.000, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=0.980, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=1.000, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=0.980, total= 0.0s
[CV] ................................................................
[CV] .................................... , score=1.000, total= 0.0s
best estimator RandomForest: RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False) Best Score 0.997
[Parallel(n_jobs=1)]: Using backend SequentialBackend with 1 concurrent workers.
[Parallel(n_jobs=1)]: Done 1 out of 1 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 0.0s remaining: 0.0s
[Parallel(n_jobs=1)]: Done 10 out of 10 | elapsed: 0.2s finished
[1 0 1 0 0 0 0 1 0 0]
[1 0 1 0 0 0 0 1 0 0]
Score for KNN : 0.9960000000000001
Score for Random Forest : 1.0
Id Solution
1 1 1
2 2 0
3 3 1
4 4 0
5 5 0
6 6 0
7 7 0
8 8 1
9 9 0
10 10 0
11 11 1
12 12 1
13 13 0
14 14 0
15 15 0
16 16 1
17 17 0
18 18 0
19 19 1
20 20 1
21 21 0
22 22 1
23 23 1
24 24 0
25 25 1
26 26 1
27 27 0
28 28 0
29 29 1
30 30 0
... ... ...
8971 8971 1
8972 8972 0
8973 8973 1
8974 8974 0
8975 8975 0
8976 8976 1
8977 8977 0
8978 8978 1
8979 8979 1
8980 8980 1
8981 8981 1
8982 8982 1
8983 8983 0
8984 8984 0
8985 8985 0
8986 8986 1
8987 8987 0
8988 8988 1
8989 8989 1
8990 8990 1
8991 8991 0
8992 8992 1
8993 8993 1
8994 8994 1
8995 8995 1
8996 8996 1
8997 8997 1
8998 8998 1
8999 8999 0
9000 9000 1
[9000 rows x 2 columns]
作者:sapienst