机器学习入门 --- LDA与PCA算法(公式推导、纯python代码实现、scikit-learn api调用对比结果)
为什么要做降维:
提高计算效率 留存有用的特征,为后续建模使用在项目中实际拿到的数据,可能会有几百个维度(特征)的数据集,这样的数据集在建模使用时,非常消耗计算资源,所以需要通过使用降维方法来优化数据集
线性判别分析(Linear Discriminant Analysis)用途:数据预处理中的降维,分类任务(有监督问题)
目标:LDA关心的是能够最大化类间区分度的坐标轴成分
将特征空间(数据集中的多维样本)投影到一个维度更小的 k 维子空间中,同时保持区分类别的信息
原理:投影到维度更低的空间中,使得投影后的点,会形成按类别区分,一簇一簇的情况,相同类别的点,将会在投影后的空间中更接近
投影:找到更合适分类的空间
监督性:LDA是“有监督”的,它计算的是另一类特定的方向
线性判别分析要优化的目标: 数学原理:原始数据:
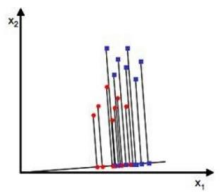
变换数据:
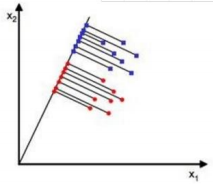
目标:找到该投影
y=wTxy = w^Txy=wTx
重点:如何求解 www
LDA分类的一个目标是使得不同类别之间的距离越远越好,另一个目标是使得同一类别之中的距离越近越好
如何算不同簇之间的距离?
在算簇之间的距离时,因为一个簇中,各个点的分布并不均匀,不能按照其中某一个点或几个点之间的距离来计算,可能存在选中的点偏离簇的点聚集区域,因此需要对簇算平均值再计算簇之间的距离
投影前的每类样例(簇)的均值:
μi=1Ni∑x∈wix
\mu _i = \frac{1}{N_i}\sum_{x\in w_i}x
μi=Ni1x∈wi∑x
投影后的每类样例(簇)的均值:
μi~=1Ni∑y∈wiy=1Ni∑x∈wiwTx=wTμi
\tilde{\mu _i} = \frac{1}{N_i}\sum_{y\in w_i}y= \frac{1}{N_i}\sum_{x\in w_i}w^T x=w^T \mu _i
μi~=Ni1y∈wi∑y=Ni1x∈wi∑wTx=wTμi
投影后要使两类样本中心点尽量分离,其目标函数为:
j(w)=∣μ1~−μ2~∣=∣wT(μ1−μ2)∣
j(w)=|\tilde{\mu _1}-\tilde{\mu _2}|=|w^T(\mu_1-\mu_2)|
j(w)=∣μ1~−μ2~∣=∣wT(μ1−μ2)∣
得到了目标函数,还有一个问题,是不是使 j(w)j(w)j(w) 最大化就可以了呢?
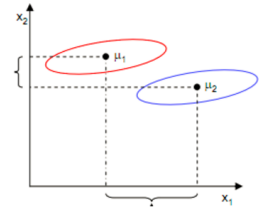
通过这张图可以看到,在 x1x_1x1 轴方向的 μ∗\mu_*μ∗ 的差值比在 x2x_2x2 轴方向的大,但在 x1x_1x1 轴方向显然比在 x2x_2x2 轴方向的分类效果差,所以就有了上面那个目标2,不仅要使得不同类别之间的距离越远越好,还要使得同一类别之中的距离越近越好
因此我们需要引入新的方法 — 散列值
散列值:样本点的密集程度,值越大,越分散,反之,越集中
st~2=∑y∈wi(y−μi~)2
\tilde{s_t}^2 = \sum_{y\in w_i}(y-\tilde{\mu_i})^2
st~2=y∈wi∑(y−μi~)2
对于离散值描述的散列值越小,越集中,那么对此函数的要求就是越小越好
对一个二分类问题,即希望 s1+s2s_1+s_2s1+s2 越小越好
因此我们得到了符合两个标准的目标函数:
j(w)=∣μ1~−μ2~∣s1~2−s2~2 j(w)=\frac{|\tilde{\mu_1}-\tilde{\mu_2}|}{\tilde{s_1}^2-\tilde{s_2}^2} j(w)=s1~2−s2~2∣μ1~−μ2~∣
对于此目标函数的优化方向是 j(w)j(w)j(w) 越大越好
散列值公式展开:
st~=∑y∈wi(y−μi~)2=∑x∈wi(wTx−wTμi)2=∑x∈wiwT(x−μi)(x−μi)Tw
\tilde{s_t} = \sum_{y\in w_i}(y-\tilde{\mu_i})^2=\sum_{x\in w_i}(w^Tx-w^T\mu_i)^2 = \sum_{x\in w_i}w^T(x-\mu_i)(x-\mu_i)^Tw
st~=y∈wi∑(y−μi~)2=x∈wi∑(wTx−wTμi)2=x∈wi∑wT(x−μi)(x−μi)Tw
散列矩阵(scatter matrices):
Si=∑x∈wi(x−μi)(x−μi)T
S_i =\sum_{x\in w_i}(x-\mu_i)(x-\mu_i)^T
Si=x∈wi∑(x−μi)(x−μi)T
类内散布矩阵:
Sw=S1+S2si~2=wTSiws1~2+s2~2=wTSww
\begin{aligned}
S_w &= S_1+S_2 \\
\tilde{s_i}^2&=w^TS_iw \\
\tilde{s_1}^2 + \tilde{s_2}^2 &= w^TS_ww
\end{aligned}
Swsi~2s1~2+s2~2=S1+S2=wTSiw=wTSww
目标函数分子展开:
(μ1~−μ2~)=(wTμ1−wTμ2)2=wT(μ1−μ2)(μ1−μ2)Tw
(\tilde{\mu_1}-\tilde{\mu_2})=(w^T\mu_1-w^T\mu_2)^2=w^T(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw
(μ1~−μ2~)=(wTμ1−wTμ2)2=wT(μ1−μ2)(μ1−μ2)Tw
设 SB=(μ1−μ2)(μ1−μ2)TS_B=(\mu_1-\mu_2)(\mu_1-\mu_2)^TSB=(μ1−μ2)(μ1−μ2)T,类间散布矩阵:
wT(μ1−μ2)(μ1−μ2)Tw=wTSBw
w^T(\mu_1-\mu_2)(\mu_1-\mu_2)^Tw = w^TS_Bw
wT(μ1−μ2)(μ1−μ2)Tw=wTSBw
得到最终目标函数:
j(w)=wTSBwwTSww
j(w) = \frac{w^TS_Bw}{w^TS_ww}
j(w)=wTSwwwTSBw
使用拉格朗日乘子法求导求解
分母进行归一化:如果分子、分母是都可以取任意值的,那就会使得有无穷解,我们将分母限制为长度为1
c(w)=wtSBw−λ(wtSww−1)⇒dcdw=2SBw−2λSww=0⇒SBw=λSww
\begin{aligned}
&c(w)=w^tS_Bw-\lambda(w^tS_ww-1) \\
&\Rightarrow \frac{d_c}{d_w}=2S_Bw-2\lambda S_ww=0 \\
&\Rightarrow S_Bw=\lambda S_ww
\end{aligned}
c(w)=wtSBw−λ(wtSww−1)⇒dwdc=2SBw−2λSww=0⇒SBw=λSww
两边都乘以Sw的逆:
Sw−1SBw=λw
S_w^{-1}S_Bw=\lambda w
Sw−1SBw=λw
至此,www 就是矩阵 Sw−1SBS_w^{-1}S_BSw−1SB 的特征向量了,得到 Sw−1S_w^{-1}Sw−1、SBS_BSB,www 就可以求出来了
LDA算法代码练习这里使用的是鸢尾花数据,先导入数据,看一下,这个数据集现在是4维的,这里将通过LDA将其改变为2维:
import pandas as pd
# 创建标签
feature_dict = {i:label for i,label in zip(
range(4),
('sepal length in cm',
'sepal width in cm',
'petal length in cm',
'petal width in cm', ))}
# 导入数据
df = pd.io.parsers.read_csv(
filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None,
sep=',',
)
# 修改列名
df.columns = [l for i,l in sorted(feature_dict.items())] + ['class label']
df.dropna(how="all", inplace=True) # to drop the empty line at file-end
# 展示
df.tail()
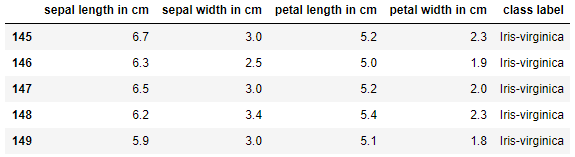
数据集结构如下:
X=[x1sepallengthx1sepalwidthx1petallengthx1petalwidthx2sepallengthx2sepalwidthx2petallengthx2petalwidth...x150sepallengthx150sepalwidthx150petallengthx150petalwidth],y=[wsetosawsetosa...wvirginica] X= \begin{bmatrix} x_{1sepal length} & x_{1sepal width} & x_{1petal length} & x_{1petal width} \\ x_{2sepal length} & x_{2sepal width} & x_{2petal length} & x_{2petal width} \\ ... & & & \\ x_{150sepal length} & x_{150sepal width} & x_{150petal length} & x_{150petal width} \end{bmatrix} ,y= \begin{bmatrix} w_{setosa}\\ w_{setosa}\\ ...\\ w_{virginica} \end{bmatrix} X=⎣⎢⎢⎡x1sepallengthx2sepallength...x150sepallengthx1sepalwidthx2sepalwidthx150sepalwidthx1petallengthx2petallengthx150petallengthx1petalwidthx2petalwidthx150petalwidth⎦⎥⎥⎤,y=⎣⎢⎢⎡wsetosawsetosa...wvirginica⎦⎥⎥⎤
看完数据集发现,标签是字符串的形式,需要将其改为数字才可以,这里我们使用 sklearn 的 LabelEncoder 方法进行转换,使得 label_dict = {1: 'Setosa', 2: 'Versicolor', 3:'Virginica'}
from sklearn.preprocessing import LabelEncoder
X = df[['sepal length in cm','sepal width in cm','petal length in cm','petal width in cm']].values
y = df['class label'].values
# 实例化
enc = LabelEncoder()
# 执行操作
label_encoder = enc.fit(y)
y = label_encoder.transform(y) + 1
变换标签后,是这样的形式:
y=[wsetosawsetosa...wvirginica]⇒[11...3] y= \begin{bmatrix} w_{setosa}\\ w_{setosa}\\ ...\\ w_{virginica} \end{bmatrix} \Rightarrow \begin{bmatrix} 1\\ 1\\ ...\\ 3 \end{bmatrix} y=⎣⎢⎢⎡wsetosawsetosa...wvirginica⎦⎥⎥⎤⇒⎣⎢⎢⎡11...3⎦⎥⎥⎤
分别求三种鸢尾花数据在不同特征维度上的均值向量 mim _imi
mi=[μwi(sepallength)μwi(sepalwidth)μwi(petallength)μwi(petalwidth)],withi=1,2,3 m_i= \begin{bmatrix} \mu_{w_i(sepal length)}\\ \mu_{w_i(sepal width)}\\ \mu_{w_i(petal length)}\\ \mu_{w_i(petal width)} \end{bmatrix},with i=1,2,3 mi=⎣⎢⎢⎡μwi(sepallength)μwi(sepalwidth)μwi(petallength)μwi(petalwidth)⎦⎥⎥⎤,withi=1,2,3
import numpy as np
np.set_printoptions(precision=4)
mean_vectors = []
for cl in range(1,4):
mean_vectors.append(np.mean(X[y==cl], axis=0))
print('Mean Vector class %s: %s\n' %(cl, mean_vectors[cl-1]))
Mean Vector class 1: [5.006 3.418 1.464 0.244]
Mean Vector class 2: [5.936 2.77 4.26 1.326]
Mean Vector class 3: [6.588 2.974 5.552 2.026]
因为在上述公式推导中,最后与 www 有关的是类内散布矩阵和类间散布矩阵,那么只需要计算这两个结果即可
类内散布矩阵:
Sw=∑i=1cSiSi=∑x∈Din(x−mi)(x−mi)Tmi=1ni∑x∈Dinxk
\begin{aligned}
S_w &= \sum_{i=1}^{c}S_i \\
S_i &=\sum_{x\in D_i}^{n}(x-m_i)(x-m_i)^T \\
m_i &=\frac{1}{n_i}\sum_{x\in D_i}^{n}x_k
\end{aligned}
SwSimi=i=1∑cSi=x∈Di∑n(x−mi)(x−mi)T=ni1x∈Di∑nxk
# 构造矩阵 4*4
S_W = np.zeros((4,4))
for cl,mv in zip(range(1,4), mean_vectors):
class_sc_mat = np.zeros((4,4)) # 每个类的散布矩阵
for row in X[y == cl]:
row, mv = row.reshape(4,1), mv.reshape(4,1) # 生成列向量
class_sc_mat += (row-mv).dot((row-mv).T)
S_W += class_sc_mat # 求和
print('类内散布矩阵:\n', S_W)
类内散布矩阵:
[[38.9562 13.683 24.614 5.6556]
[13.683 17.035 8.12 4.9132]
[24.614 8.12 27.22 6.2536]
[ 5.6556 4.9132 6.2536 6.1756]]
类间散布矩阵:
在原推导流程里面,是由两个类之间的均值相减,这里为了简化算法,提高计算速度,使用每个类别与全局均值的差值计算
SB=∑i=1cNi(mi−m)(mi−m)T
S_B=\sum _{i=1}^{c}N_i(m_i-m)(m_i-m)^T
SB=i=1∑cNi(mi−m)(mi−m)T
mmm 是全局均值,而 mim_imi 和 NiN_iNi 是每类样本的均值和样本数
overall_mean = np.mean(X, axis=0)
S_B = np.zeros((4,4))
for i,mean_vec in enumerate(mean_vectors):
n = X[y==i+1,:].shape[0]
mean_vec = mean_vec.reshape(4,1)
overall_mean = overall_mean.reshape(4,1)
S_B += n * (mean_vec - overall_mean).dot((mean_vec - overall_mean).T)
print('类间散布矩阵:\n', S_B)
类间散布矩阵:
[[ 63.2121 -19.534 165.1647 71.3631]
[-19.534 10.9776 -56.0552 -22.4924]
[165.1647 -56.0552 436.6437 186.9081]
[ 71.3631 -22.4924 186.9081 80.6041]]
求解矩阵的特征值与特征向量:
Sw−1SB S_w^{-1}S_B Sw−1SB
特征值与特征向量:
特征向量:表示映射方向 特征值:特征向量的重要程度# 拿到特征值和特征向量
eig_vals, eig_vecs = np.linalg.eig(np.linalg.inv(S_W).dot(S_B))
# 展示特征值与特征向量
for i in range(len(eig_vals)):
eigvec_sc = eig_vecs[:,i].reshape(4,1)
print('\nEigenvector {}: \n{}'.format(i+1, eigvec_sc.real))
print('Eigenvalue {:}: {:.2e}'.format(i+1, eig_vals[i].real))
Eigenvector 1:
[[ 0.2049]
[ 0.3871]
[-0.5465]
[-0.7138]]
Eigenvalue 1: 3.23e+01
Eigenvector 2:
[[-0.009 ]
[-0.589 ]
[ 0.2543]
[-0.767 ]]
Eigenvalue 2: 2.78e-01
Eigenvector 3:
[[-0.7113]
[ 0.0353]
[-0.0267]
[ 0.7015]]
Eigenvalue 3: -5.76e-15
Eigenvector 4:
[[ 0.422 ]
[-0.4364]
[-0.4851]
[ 0.6294]]
Eigenvalue 4: 7.80e-15
目前为止,还是4个维度的数据,接下来要将其降维至两个维度,从四个维度中选择两个维度映射至其上
# 列出(特征值,特征向量)元组
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
# 将(特征值,特征向量)元组从高到低排序
eig_pairs = sorted(eig_pairs, key=lambda k: k[0], reverse=True)
# 通过降低特征值来直观地确认列表已正确排序
print('降阶特征值:\n')
for i in eig_pairs:
print(i[0])
降阶特征值:
32.27195779972981
0.27756686384003953
1.1483362279322388e-14
3.422458920849769e-15
print('差异百分比:\n')
eigv_sum = sum(eig_vals)
for i,j in enumerate(eig_pairs):
print('特征值 {0:}: {1:.2%}'.format(i+1, (j[0]/eigv_sum).real))
差异百分比:
特征值 1: 99.15%
特征值 2: 0.85%
特征值 3: 0.00%
特征值 4: 0.00%
看完特征差异后,就确定了重要性最大的前两个维度,选择前两个维度特征,作为降维的目标
组合重要性排序的前两个维度:
W = np.hstack((eig_pairs[0][1].reshape(4,1), eig_pairs[1][1].reshape(4,1)))
print('矩阵 W:\n', W.real)
矩阵 W:
[[-0.2049 -0.009 ]
[-0.3871 -0.589 ]
[ 0.5465 0.2543]
[ 0.7138 -0.767 ]]
到这里就得到了我们前面公式推导中的 www,接下来就可以做降维任务了
# 降维
X_lda = X.dot(W) # [150,4]*[4,2] → [150,2]
# 判断结果
assert X_lda.shape == (150,2), "The matrix is not 150x2 dimensional."
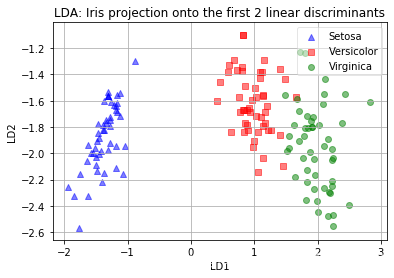
画图查看结果:
from matplotlib import pyplot as plt
label_dict = {1: 'Setosa', 2: 'Versicolor', 3:'Virginica'}
def plot_step_lda():
for label,marker,color in zip(
range(1,4),('^', 's', 'o'),('blue', 'red', 'green')):
plt.scatter(x=X_lda[:,0].real[y == label],
y=X_lda[:,1].real[y == label],
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label]
)
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title('LDA: Iris projection onto the first 2 linear discriminants')
plt.grid()
plt.tight_layout
plt.show()
# 执行
plot_step_lda()
原始数据分布:
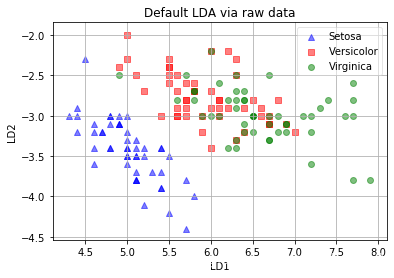
降维数据分布:
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
# LDA 实例化 降低为2维
sklearn_lda = LDA(n_components=2)
# 执行
X_lda_sklearn = sklearn_lda.fit_transform(X, y)
查看结果:
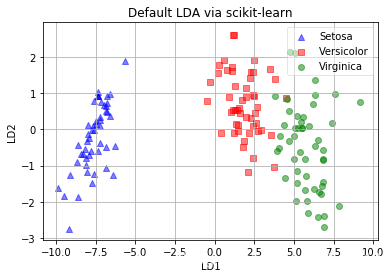
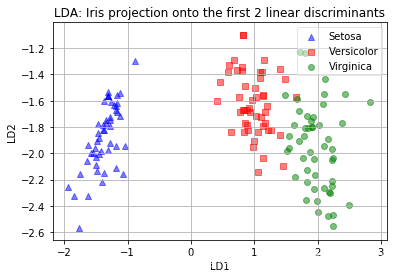
对比这两个结果,Sklearn 与 我们自己写的代码效果差不多
(a1,a2,...,an)T⋅(b1,b2,...,bn)T=a1b1+a2b2+...+anbn (a_1,a_2,...,a_n)^T \cdot (b_1,b_2,...,b_n)^T=a_1b_1+a_2b_2+...+a_nb_n (a1,a2,...,an)T⋅(b1,b2,...,bn)T=a1b1+a2b2+...+anbn
解释:
A⋅B=∣A∣∣B∣cos(a)
A \cdot B=|A||B|cos(a)
A⋅B=∣A∣∣B∣cos(a)
向量可以表示为 (3,2)(3,2)(3,2),实际上表示线性组合:
x(1,0)T+y(0,1)T
x(1,0)^T+y(0,1)^T
x(1,0)T+y(0,1)T
基是正交的,即内积为0,或直观说相互垂直,线性无关
基变换变换:数据与一个基做内积运算,结果作为第一个新的坐标分量,然后与第二个基做内积运算,结果作为第二个新坐标的分量
数据 (3,2)(3,2)(3,2) 映射到基中坐标:
(1212−1212)(32)=(52−12) \begin{pmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{pmatrix} \binom{3}{2} =\binom{\frac{5}{\sqrt{2}}}{-\frac{1}{\sqrt{2}}} (21−212121)(23)=(−2125)
基变换公式完整表达:
(p1p2...pR)(a1a2...aM)=(p1a1p1a2...p1aMp2a1p2a2...p2aM............pRa1pRa2...pRaM)
\begin{pmatrix}
p_1\\
p_2\\
...\\
p_R
\end{pmatrix}
\begin{pmatrix}
a_1 & a_2 & ... & a_M
\end{pmatrix}=
\begin{pmatrix}
p_1a_1 & p_1a_2 & ... & p_1a_M\\
p_2a_1 & p_2a_2 & ... & p_2a_M\\
... & ... & ... & ...\\
p_Ra_1 & p_Ra_2 & ... & p_Ra_M
\end{pmatrix}
⎝⎜⎜⎛p1p2...pR⎠⎟⎟⎞(a1a2...aM)=⎝⎜⎜⎛p1a1p2a1...pRa1p1a2p2a2...pRa2............p1aMp2aM...pRaM⎠⎟⎟⎞
两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去
一种直观的看法是:希望投影后的投影值尽可能分散 方差:
Var(a)=1m∑i=1m(ai−μ)2 Var(a) = \frac{1}{m}\sum_{i=1}^{m}(a_i-\mu)^2 Var(a)=m1i=1∑m(ai−μ)2 目标:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大 协方差(假设均值为0时,数据归一化):
方差是一个特征的分散程度,协方差是表示两个特征之间的相关性,两个特征变化越相似的则协方差越大
Cov(a,b)=1m∑i=1maibi Cov(a,b)=\frac{1}{m}\sum_{i=1}^{m}a_ib_i Cov(a,b)=m1i=1∑maibi
如果单纯只选择方差最大的方向,后续方向应该会和方差最大的方向接近重合,那么这样就会使得它们之间存在(线性)相关性的,为了让两个字段尽可能表示更多的原始信息,我们是不希望它们之间存在(线性)相关性的,那么我们需要找到相互垂直的基,这时候就要使用协方差解决,协方差可以用来表示其相关性
当协方差为0时,表示两个字段完全独立。为了让协方差为0,选择第二个基时
只能在与第一个基正交的方向上选择。因此最终选择的两个方向一定是正交的
将一组N维向量降为K维(K大于0,小于N),目标是选择K个单位正交基,使原始数据变换到这组基上后,各字段两两间协方差为0,字段的方差则尽可能大
协方差矩阵:
X=(a1a2...amb1b2...bm)
X=
\begin{pmatrix}
a_1 & a_2 & ... & a_m\\
b_1 & b_2 & ... & b_m
\end{pmatrix}
X=(a1b1a2b2......ambm)
1mXXT=(1m∑i=1mai21m∑i=1maibi1m∑i=1maibi1m∑i=1mbi2)
\frac{1}{m}XX^T=
\begin{pmatrix}
\frac{1}{m}\sum_{i=1}^{m}a_i^2 & \frac{1}{m}\sum_{i=1}^{m}a_ib_i \\
\frac{1}{m}\sum_{i=1}^{m}a_ib_i & \frac{1}{m}\sum_{i=1}^{m}b_i^2
\end{pmatrix}
m1XXT=(m1∑i=1mai2m1∑i=1maibim1∑i=1maibim1∑i=1mbi2)
矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差
我们的目标是想要使得协方差为0,那就是说要使得协方差矩阵中非对角线的位置处处为0,接下来操作就是进行协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列
协方差矩阵对角化:
PCPT=Λ=(λ1λ2⋱λn)
PCP^T=\Lambda =
\begin{pmatrix}
\lambda_1 & & & \\
& \lambda_2 & & \\
& & \ddots & \\
& & & \lambda_n
\end{pmatrix}
PCPT=Λ=⎝⎜⎜⎛λ1λ2⋱λn⎠⎟⎟⎞
进行协方差矩阵对角化时,我们要用到实对称矩阵方法
实对称矩阵:一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量
E=(e1e2...en)
E=
\begin{pmatrix}
e_1 & e_2 & ... & e_n
\end{pmatrix}
E=(e1e2...en)
实对称阵可进行对角化:
ETCE=Λ=(λ1λ2⋱λn)
E^TCE=\Lambda =
\begin{pmatrix}
\lambda_1 & & & \\
& \lambda_2 & & \\
& & \ddots & \\
& & & \lambda_n
\end{pmatrix}
ETCE=Λ=⎝⎜⎜⎛λ1λ2⋱λn⎠⎟⎟⎞
根据特征值的从大到小,将特征向量从上到下排列,则用前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y
PCA实例:假设数据为两个特征的五条数据(二维化一维)
数据:(−1−1020−20011)\begin{pmatrix} -1 & -1 & 0 & 2 & 0\\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}(−1−2−10002101)
协方差矩阵:C=15(−1−1020−20011)(−1−2−10002101)=(65454565)C=\frac{1}{5}\begin{pmatrix} -1 & -1 & 0 & 2 & 0\\ -2 & 0 & 0 & 1 & 1 \end{pmatrix} \begin{pmatrix} -1 & -2\\ -1 & 0\\ 0 & 0\\ 2 & 1\\ 0 & 1 \end{pmatrix}= \begin{pmatrix} \frac{6}{5} & \frac{4}{5}\\ \frac{4}{5} & \frac{6}{5} \end{pmatrix}C=51(−1−2−10002101)⎝⎜⎜⎜⎜⎛−1−1020−20011⎠⎟⎟⎟⎟⎞=(56545456)
特征值:λ1=2,λ2=25\lambda_1=2,\lambda_2=\frac{2}{5}λ1=2,λ2=52
特征向量:c1(11),c2(−11)c_1\binom{1}{1},c_2\binom{-1}{1}c1(11),c2(1−1)
对角化:PCPT=(1212−1212)(65454565)(12−121212)=(20025)PCP^T= \begin{pmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \\ -\frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{pmatrix} \begin{pmatrix} \frac{6}{5} & \frac{4}{5}\\ \frac{4}{5} & \frac{6}{5} \end{pmatrix} \begin{pmatrix} \frac{1}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \\ \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{pmatrix}= \begin{pmatrix} 2 & 0\\ 0 & \frac{2}{5} \end{pmatrix}PCPT=(21−212121)(56545456)(2121−2121)=(20052)
降维:Y=(1212)(−1−1020−20011)=(−32−12032−12)Y=\begin{pmatrix} \frac{1}{\sqrt{2}} & \frac{1}{\sqrt{2}} \end{pmatrix} \begin{pmatrix} -1 & -1 & 0 & 2 & 0\\ -2 & 0 & 0 & 1 & 1 \end{pmatrix}= \begin{pmatrix} -\frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}} & 0 & \frac{3}{\sqrt{2}} & -\frac{1}{\sqrt{2}} \end{pmatrix}Y=(2121)(−1−2−10002101)=(−23−21023−21)
PCA算法代码练习# 读取数据
import numpy as np
import pandas as pd
df = pd.read_csv('iris.data')
# 指定列名
df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
# 将数据表拆分为数据X和类标签y
X = df.ix[:,0:4].values
y = df.ix[:,4].values
数据可视化展示
from matplotlib import pyplot as plt
import math
label_dict = {1: 'Iris-Setosa',
2: 'Iris-Versicolor',
3: 'Iris-Virgnica'}
feature_dict = {0: 'sepal length [cm]',
1: 'sepal width [cm]',
2: 'petal length [cm]',
3: 'petal width [cm]'}
plt.figure(figsize=(8, 6))
for cnt in range(4):
plt.subplot(2, 2, cnt+1)
for lab in ('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'):
plt.hist(X[y==lab, cnt],
label=lab,
bins=10,
alpha=0.3,)
plt.xlabel(feature_dict[cnt])
plt.legend(loc='upper right', fancybox=True, fontsize=8)
plt.tight_layout()
plt.show()
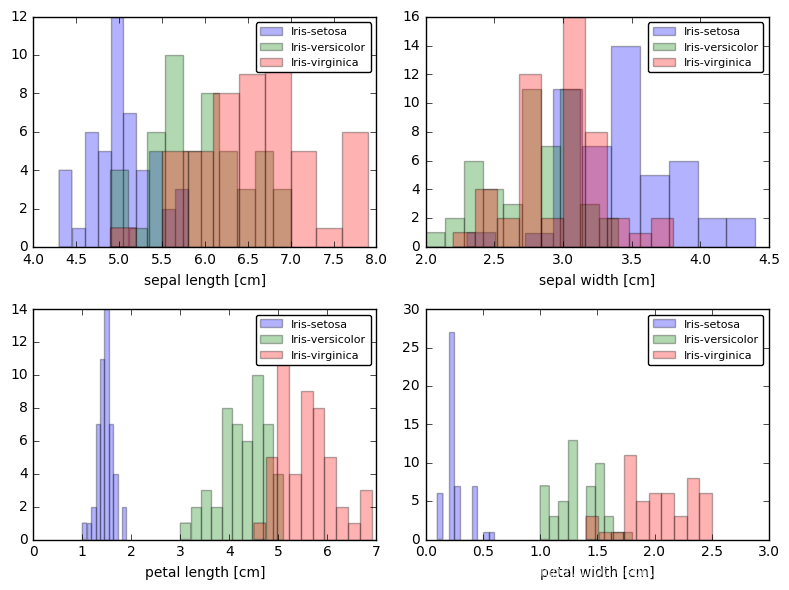
对数据进行标准化:
from sklearn.preprocessing import StandardScaler
X_std = StandardScaler().fit_transform(X)
mean_vec = np.mean(X_std, axis=0)
cov_mat = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0]-1)
print('协方差矩阵 \n%s' %cov_mat)
协方差矩阵
[[ 1.00675676 -0.10448539 0.87716999 0.82249094]
[-0.10448539 1.00675676 -0.41802325 -0.35310295]
[ 0.87716999 -0.41802325 1.00675676 0.96881642]
[ 0.82249094 -0.35310295 0.96881642 1.00675676]]
计算特征值和特征向量:
cov_mat = np.cov(X_std.T)
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print('特征向量 \n%s' %eig_vecs)
print('\n特征值 \n%s' %eig_vals)
特征向量
[[ 0.52308496 -0.36956962 -0.72154279 0.26301409]
[-0.25956935 -0.92681168 0.2411952 -0.12437342]
[ 0.58184289 -0.01912775 0.13962963 -0.80099722]
[ 0.56609604 -0.06381646 0.63380158 0.52321917]]
特征值
[2.92442837 0.93215233 0.14946373 0.02098259]
将特征值与特征向量进行对应:
# 列出(特征值,特征向量)元组
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
print (eig_pairs)
# 将(特征值,特征向量)元组从高到低排序
eig_pairs.sort(key=lambda x: x[0], reverse=True)
# 通过降序特征值来直观地确认列表已正确排序
print('\n降序特征值:')
for i in eig_pairs:
print(i[0])
[(2.9244283691111144, array([ 0.52308496, -0.25956935, 0.58184289, 0.56609604])), (0.9321523302535064, array([-0.36956962, -0.92681168, -0.01912775, -0.06381646])), (0.14946373489813314, array([-0.72154279, 0.2411952 , 0.13962963, 0.63380158])), (0.020982592764270606, array([ 0.26301409, -0.12437342, -0.80099722, 0.52321917]))]
降序特征值:
2.9244283691111144
0.9321523302535064
0.14946373489813314
0.020982592764270606
做特征值的百分占比,看各特征值的重要性
tot = sum(eig_vals)
# 求特征值的百分占比
var_exp = [(i / tot)*100 for i in sorted(eig_vals, reverse=True)]
print (var_exp)
# 做累加
cum_var_exp = np.cumsum(var_exp)
cum_var_exp
[72.62003332692034, 23.147406858644135, 3.7115155645845164, 0.5210442498510154]
array([ 72.62003333, 95.76744019, 99.47895575, 100. ])
画特征值的百分占比及重要性趋势图
from matplotlib import pyplot as plt
plt.figure(figsize=(6, 4))
plt.bar(range(4), var_exp, alpha=0.5, align='center',
label='individual explained variance')
plt.step(range(4), cum_var_exp, where='mid',
label='cumulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
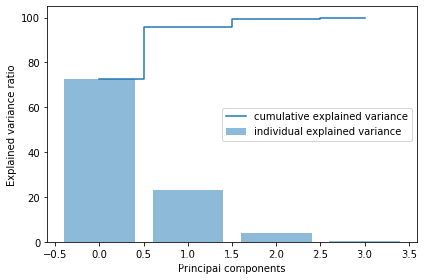
至此可以看出,前两维度的特征已经是占了95%以上的重要性,后面两个维度对结果的影响不大,那么这里就可以降到两维
# 拿到前两个特征向量
matrix_w = np.hstack((eig_pairs[0][1].reshape(4,1),
eig_pairs[1][1].reshape(4,1)))
print('矩阵 W:\n', matrix_w)
# 执行降维:原数据*特征向量
Y = X_std.dot(matrix_w)
完成降维后,来看一下分类结果:
原始数据:
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(X[y==lab, 0],
X[y==lab, 1],
label=lab,
c=col)
plt.xlabel('sepal_len')
plt.ylabel('sepal_wid')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
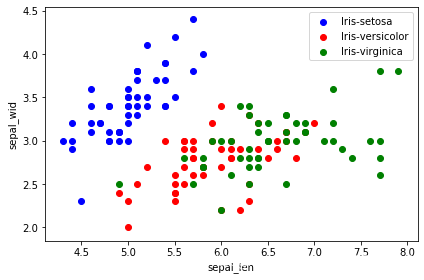
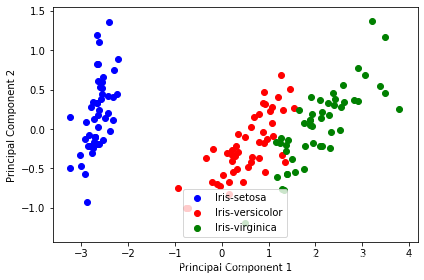
降维后的数据:
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(Y[y==lab, 0],
Y[y==lab, 1],
label=lab,
c=col)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(loc='lower center')
plt.tight_layout()
plt.show()
使用数据标准化的降维结果:
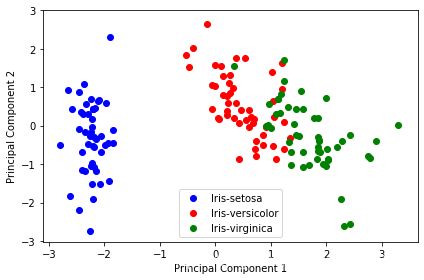
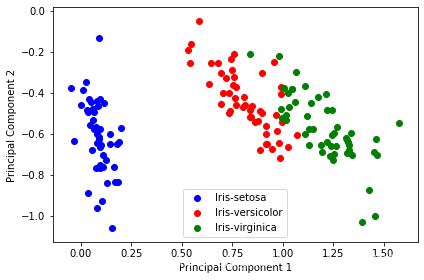
结果显示,对于此数据来说,进行归一化能够更好的将数据进行分类
from sklearn.decomposition import PCA
# LDA 实例化 降低为2维
sklearn_lda = PCA(n_components=2)
# 执行
X_pca_sklearn = sklearn_lda.fit_transform(X)
查看结果:
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(X_pca_sklearn[y==lab, 0],
X_pca_sklearn[y==lab, 1],
label=lab,
c=col)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(loc='lower center')
plt.tight_layout()
plt.show()
对比这几个结果,Sklearn 与 我们自己写的代码效果差不多
作者:六之