TensorFlow(一)Scikit-Learn之Transformer项目实战过程
本文主要对用scikit-learn来构建不同模型的实例项目进行介绍: Scikit-learn具体使用方法和语法参数在本人blog中的“TensorFlow(一)Scikit-Learn之Transformer“已进行详细介绍,链接如下:
https://huxiaoyang.blog.csdn.net/article/details/105645392
实战项目 实战项目一:以boston数据集为例 项目目标:使用sklearn实现对boston数据处理和降维
项目步骤:首先我们可以将对boston数据处理分为四个框架,即数据获取、数据划分、数据预处理、降维
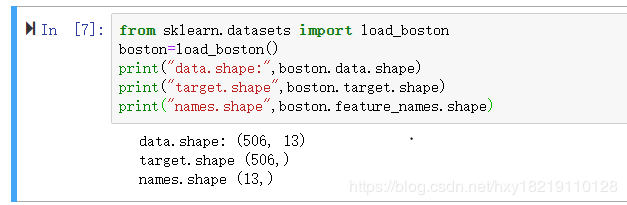
1.1:数据获取获取sklearn自带的boston数据集,
代码如下:
from sklearn.datasets import load_boston
boston=load_boston()
print("data.shape:",boston.data.shape)
print("target.shape",boston.target.shape)
print("names.shape",boston.feature_names.shape)
输出如下:
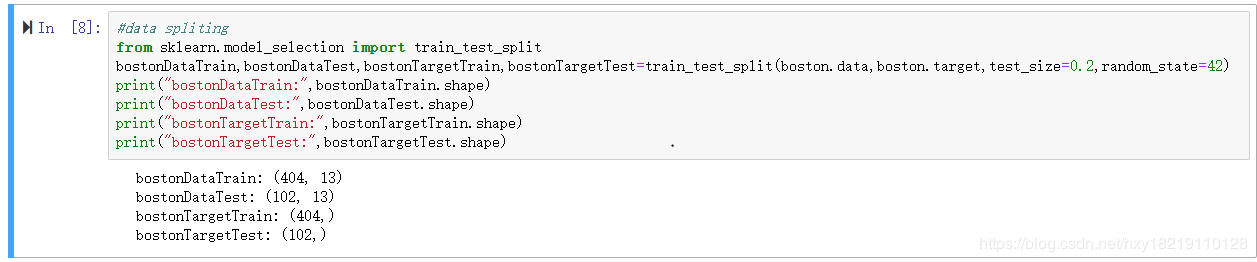
使用train_test_split方法进行数据划分为训练集和测试集,测试集占0.2,
代码如下:
#data spliting
from sklearn.model_selection import train_test_split
bostonDataTrain,bostonDataTest,bostonTargetTrain,bostonTargetTest=train_test_split(boston.data,boston.target,test_size=0.2,random_state=42)
print("bostonDataTrain:",bostonDataTrain.shape)
print("bostonDataTest:",bostonDataTest.shape)
print("bostonTargetTrain:",bostonTargetTrain.shape)
print("bostonTargetTest:",bostonTargetTest.shape)
输出如下:
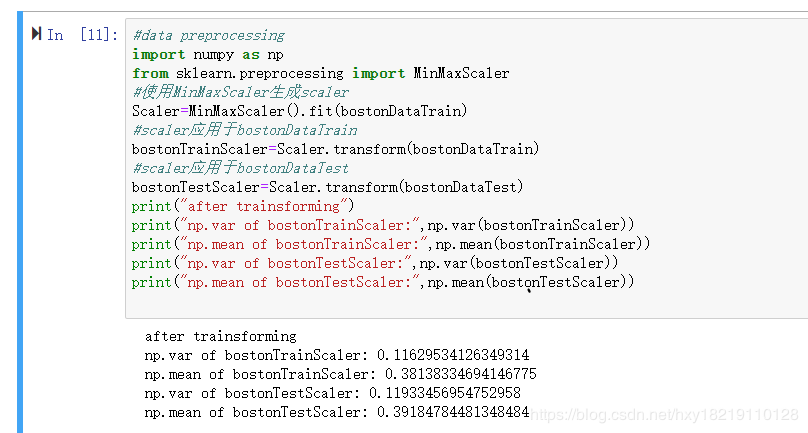
使用MinMaxScaler对数据集进行离差标准化,
代码如下:
#data preprocessing
import numpy as np
from sklearn.preprocessing import MinMaxScaler
#使用MinMaxScaler生成scaler
Scaler=MinMaxScaler().fit(bostonDataTrain)
#scaler应用于bostonDataTrain
bostonTrainScaler=Scaler.transform(bostonDataTrain)
#scaler应用于bostonDataTest
bostonTestScaler=Scaler.transform(bostonDataTest)
print("after trainsforming")
print("np.var of bostonTrainScaler:",np.var(bostonTrainScaler))
print("np.mean of bostonTrainScaler:",np.mean(bostonTrainScaler))
print("np.var of bostonTestScaler:",np.var(bostonTestScaler))
print("np.mean of bostonTestScaler:",np.mean(bostonTestScaler))
输出如下:
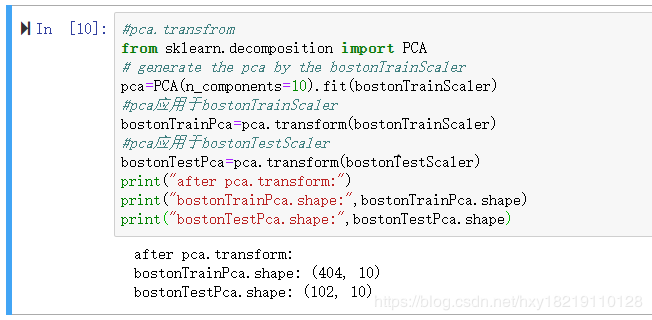
使用pca.transform方法对训练集和测试集进行降维,降成10个维度,
代码如下:
#pca.transfrom
from sklearn.decomposition import PCA
# generate the pca by the bostonTrainScaler
pca=PCA(n_components=10).fit(bostonTrainScaler)
#pca应用于bostonTrainScaler
bostonTrainPca=pca.transform(bostonTrainScaler)
#pca应用于bostonTestScaler
bostonTestPca=pca.transform(bostonTestScaler)
print("after pca.transform:")
print("bostonTrainPca.shape:",bostonTrainPca.shape)
print("bostonTestPca.shape:",bostonTestPca.shape)
输出如下:
通过wine和wine_quality两份datasets来进行分析葡萄酒的起源和预测葡萄酒的评分。
项目步骤:通过数据说明对数据分析后,首先我们可以将对boston数据处理分为五个框架,即数据获取、数据分离、数据划分(测试集0.1)、数据预处理(StandardScaler)、降维(降成5个维度)
2.1:数据获取利用pandas对datasets进行读取,(其中需要注意的是在wine数据集中数据可以直接读入,而wine_quality数据集是以‘;’作为间隔,则可以在read_csv方法中的sep参数赋值为该字符)
代码如下:
import pandas as pd
wine=pd.read_csv('wine.csv')
wineQuality=pd.read_csv('winequality.csv',sep=';')
print(wine.head(3))
print(wineQuality.head(3))
输出如下:
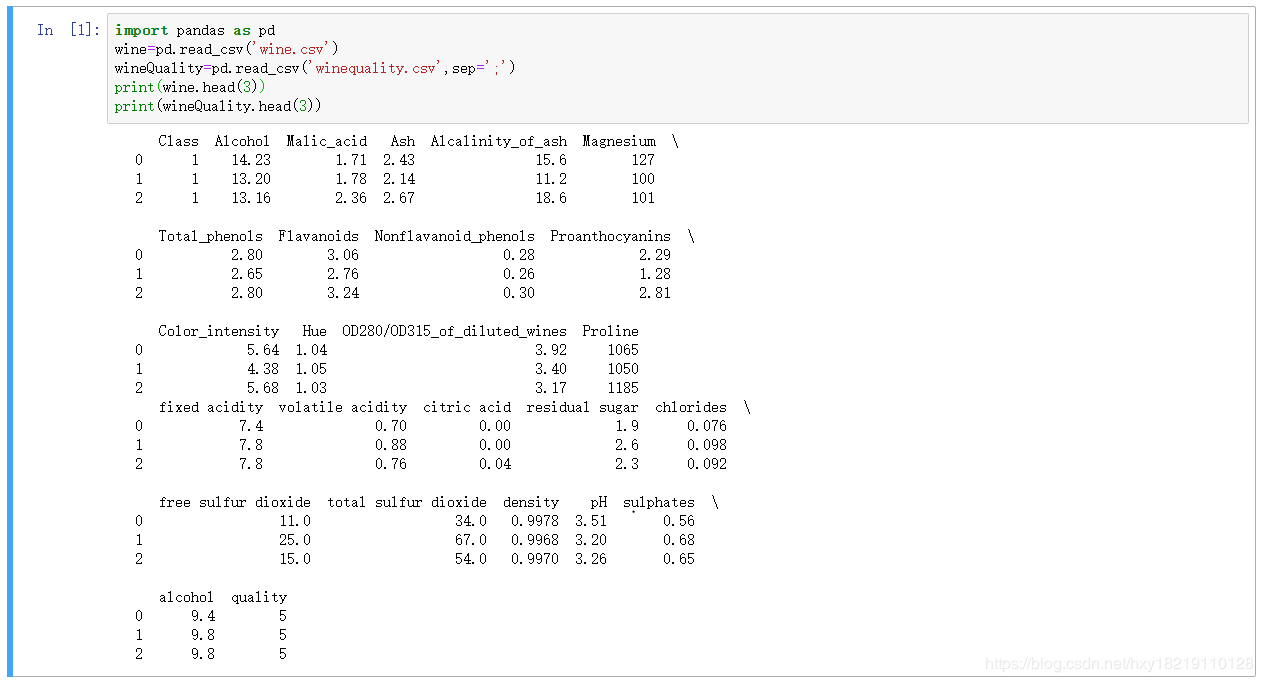
利用iloc方法对数据进行拆分,
代码如下:
#data daparting
wineData=wine.iloc[:,1:]
wineTarget=wine.iloc[:,0]
wineQualityData=wineQuality.iloc[:,:-1]
wineQualityTarget=wineQuality.iloc[:,-1]
print('wineData:\n',wineData.head(2))
print("wineTarget:\n",wineTarget.head(2))
print("wineQualityData:\n",wineQualityData.head(2))
print("wineQualityTarget\n",wineQualityTarget.head(2))
输出如下:
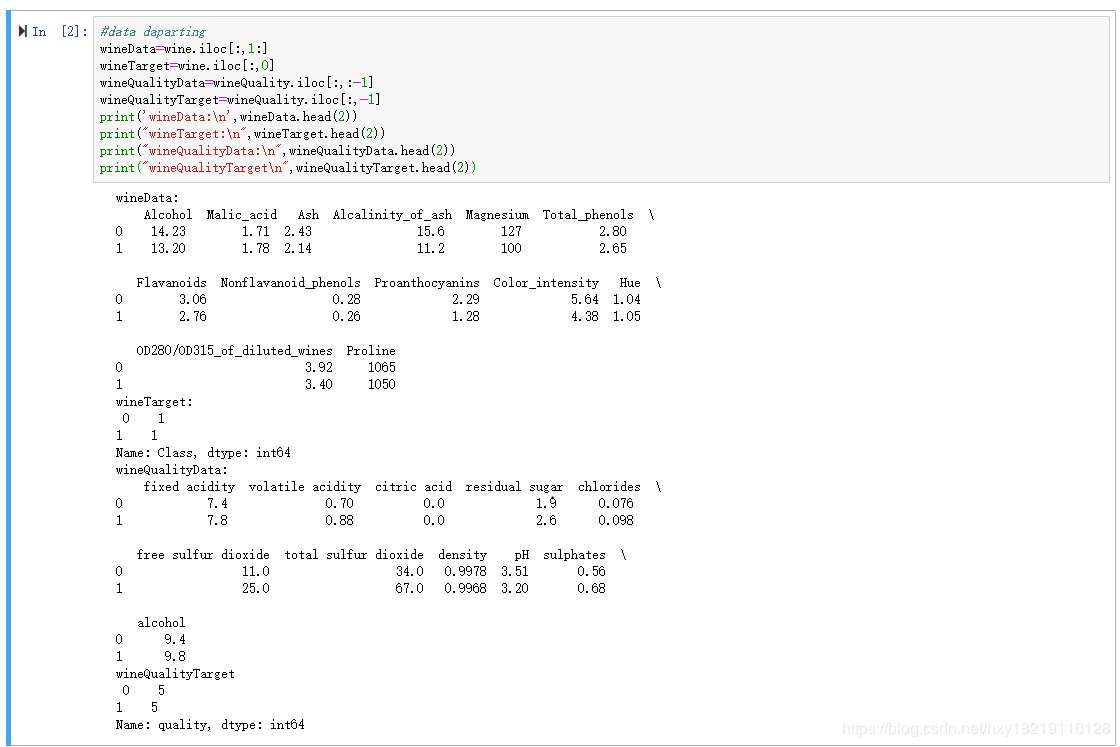
划分数据训练集和测试集,
代码如下:
#data spliting
from sklearn.model_selection import train_test_split
wineDataTrain,wineDataTest,wineTargetTrain,wineTargetTest=train_test_split(wineData,wineTarget,test_size=0.1,random_state=23)
wineQualityDataTrain,wineQualityDataTest,wineQualityTargetTrain,wineQualityTargetTest=train_test_split(wineQualityData,wineQualityTarget
,test_size=0.1,random_state=23)
print("wineDataTrain",wineDataTrain.shape)
print("wineDataTest",wineDataTest.shape)
print("wineTargetTrain",wineTargetTrain.shape)
print("wineTargetTest",wineTargetTest.shape)
print('-'*100)
print("wineQualityDataTrain",wineQualityDataTrain.shape)
print("wineQualityDataTest",wineQualityDataTest.shape)
print("wineQualityTargetTrain",wineQualityTargetTrain.shape)
print("wineQualityTargetTest",wineQualityTargetTest.shape)
输出如下:
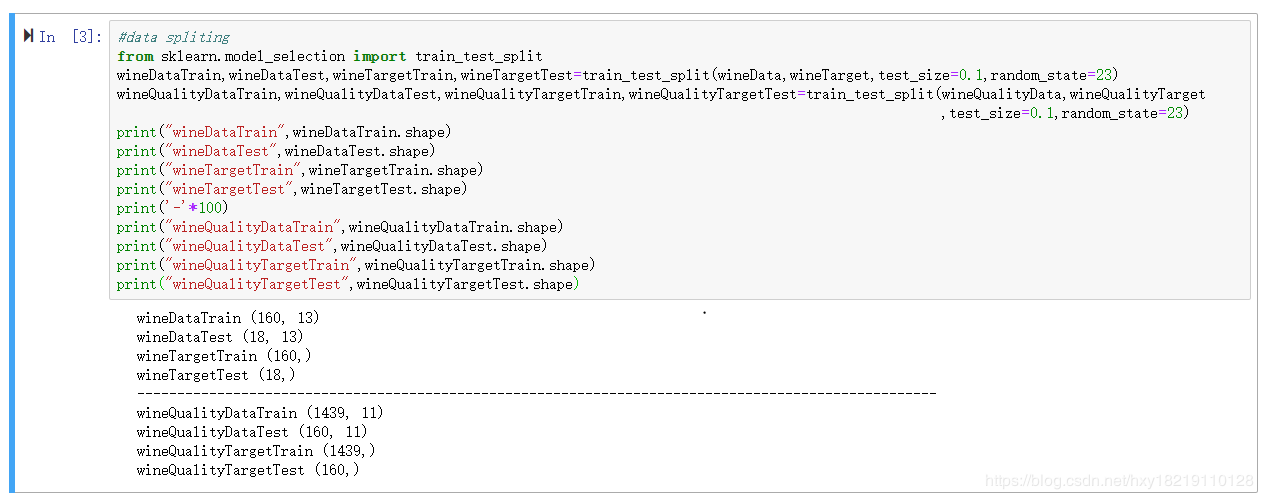
datasets的数据预处理,
代码如下:
#data preprocessing
import numpy as np
from sklearn.preprocessing import StandardScaler
#generate the Scaler by wineDataTrain
stdScaler=StandardScaler().fit(wineDataTrain)
#stdScaler应用于训练集
wineDataTrainScaler=stdScaler.transform(wineDataTrain)
#stdScaler应用于测试集
wineDataTestScaler=stdScaler.transform(wineDataTest)
#generate the Scaler by wineQualityDataTrain
stdScaler=StandardScaler().fit(wineQualityDataTrain)
#stdScaler应用于训练集
wineQualityDataTrainScaler=stdScaler.transform(wineQualityDataTrain)
#stdScaler应用于测试集
wineQualityDataTestScaler=stdScaler.transform(wineQualityDataTest)
print("after trainsforming:")
print("np.var of :wineDataTrainScaler",np.var(wineDataTrainScaler))
print("np.mean of :wineDataTrainScaler",np.mean(wineDataTrainScaler))
print("np.var of :wineDataTestScaler",np.var(wineDataTestScaler))
print("np.mean of :wineDataTestScaler",np.mean(wineDataTestScaler))
print('-'*100)
print("np.var of :wineQualityDataTrainScaler",np.var(wineQualityDataTrainScaler))
print("np.mean of :wineQualityDataTrainScaler",np.mean(wineQualityDataTrainScaler))
print("np.var of :wineQualityDataTestScaler",np.var(wineQualityDataTestScaler))
print("np.mean of :wineQualityDataTestScaler",np.mean(wineQualityDataTestScaler))
输出如下:
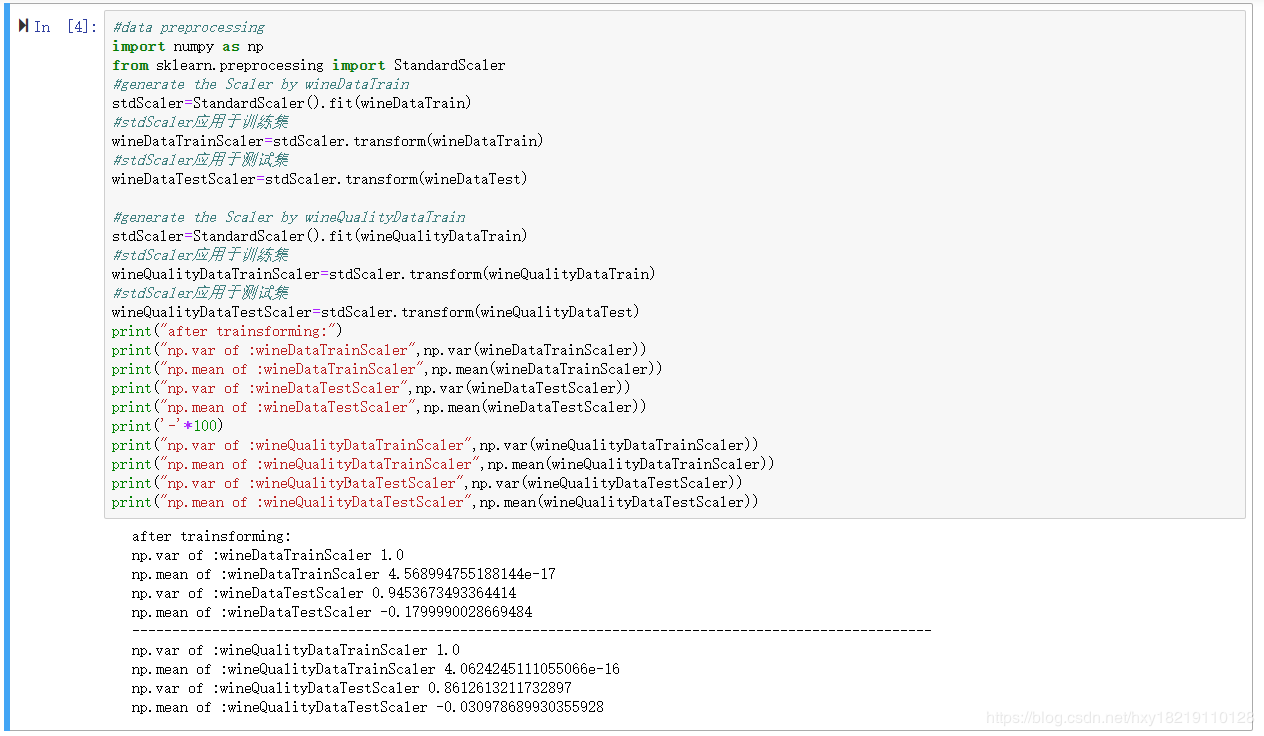
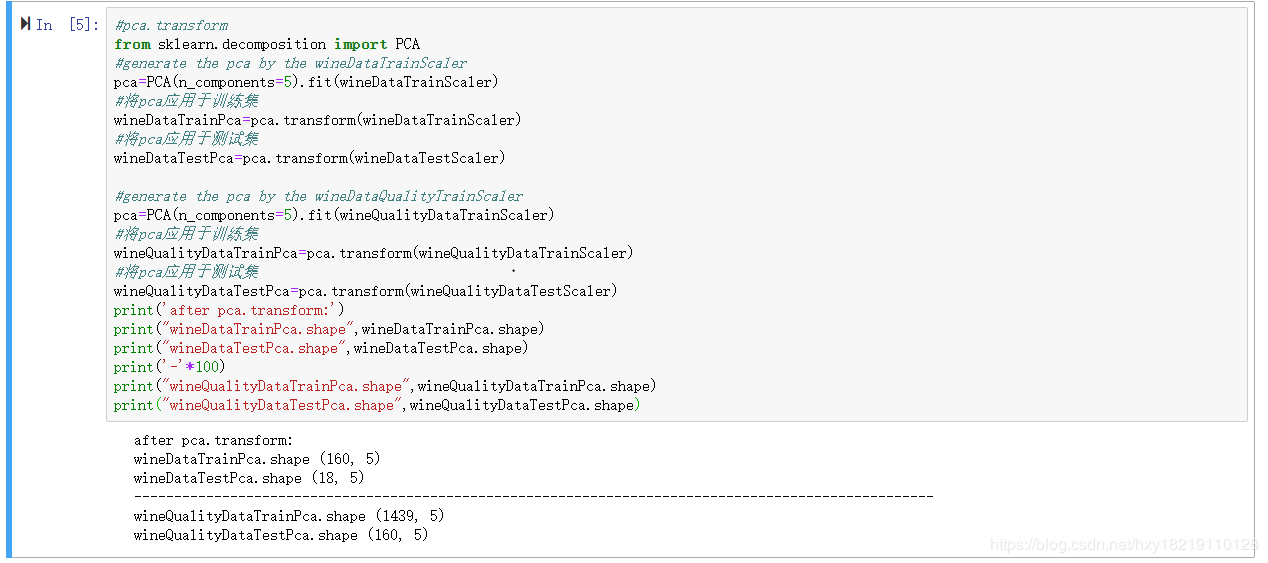
PCA降维,维度为5,
代码如下:
#pca.transform
from sklearn.decomposition import PCA
#generate the pca by the wineDataTrainScaler
pca=PCA(n_components=5).fit(wineDataTrainScaler)
#将pca应用于训练集
wineDataTrainPca=pca.transform(wineDataTrainScaler)
#将pca应用于测试集
wineDataTestPca=pca.transform(wineDataTestScaler)
#generate the pca by the wineDataQualityTrainScaler
pca=PCA(n_components=5).fit(wineQualityDataTrainScaler)
#将pca应用于训练集
wineQualityDataTrainPca=pca.transform(wineQualityDataTrainScaler)
#将pca应用于测试集
wineQualityDataTestPca=pca.transform(wineQualityDataTestScaler)
print('after pca.transform:')
print("wineDataTrainPca.shape",wineDataTrainPca.shape)
print("wineDataTestPca.shape",wineDataTestPca.shape)
print('-'*100)
print("wineQualityDataTrainPca.shape",wineQualityDataTrainPca.shape)
print("wineQualityDataTestPca.shape",wineQualityDataTestPca.shape)
输出如下:
项目目标:
项目步骤:
作者:hyhooo