使用Python和scikit-learn创建混淆矩阵的示例详解
一、混淆矩阵概述
1、示例1
2、示例2
二、使用Scikit-learn 创建混淆矩阵
1、相应软件包
2、生成示例数据集
3、训练一个SVM
4、生成混淆矩阵
5、可视化边界
一、混淆矩阵概述在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况。
这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据。
如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的。
现在,当您测试您的模型时,您向其提供数据 - 并将预测与基本事实进行比较,测量真阳性、真阴性、假阳性和假阴性的数量。这些随后可以在视觉上吸引人的混淆矩阵中可视化。
在今天我们将学习如何使用 Scikit-learn 创建这样的混淆矩阵,Scikit-learn 是当今机器学习社区中使用最广泛的机器学习框架之一。通过使用 Python 创建的示例,展示如何生成一个矩阵,您可以使用该矩阵轻松直观地确定模型的性能。
1、示例1
一个混淆矩阵的例子
它是一个归一化的混淆矩阵。它的描述了两个度量:
True label,这是您的测试集所代表的基本事实。
Predicted label,即机器学习模型对与真实标签对应的特征生成的预测。
例如,在上面的模型中,对于所有真实标签 1,预测标签为 1。这意味着来自第 1 类的所有样本都被正确分类。
对于其他类,性能也不错,但稍差一些。如您所见,对于第 2 类,一些样本被预测为第 0 类和第 1 类的一部分。
简而言之,它回答了“对于我的真实标签/基本事实,模型的预测效果如何?”这个问题。
2、示例2也可以从预测的角度看,问题将变为“对于我的预测标签,有多少预测实际上是预测类别的一部分?”。这是相反的观点,但在许多机器学习案例中可能是一个有意义的问题。
最优情况,是整个真实标签集等于预测标签集。在这些情况下,除了从左上角到右下角的线之外,您会在各处看到零。然而,在实践中,这种情况并不经常发生。很可能更加分散,例如下面这个 SVM 分类器,其中需要许多支持向量来绘制不能完美工作但足够充分的决策边界:


现在创建一个混淆矩阵。将使用 Python 和 Scikit-learn。
创建混淆矩阵涉及多个步骤:
1、生成示例数据集。需要数据来训练我们的模型。因此,我们将首先生成数据,以便我们接下来可以为 ML 模型类做出适当的选择。
2、选择机器学习模型类。显然,如果我们要评估一个模型,我们需要训练一个模型。我们将首先选择适合我们数据特征的特定类型的模型。
3、构建和训练 ML 模型。前两个步骤的结果是我们最终得到了一个训练有素的模型。
4、生成混淆矩阵。最后,基于训练好的模型,我们可以创建我们的混淆矩阵。
1、相应软件包需要以下包,假定已经安装好了Python环境、Scikit-learn、Numpy、Matplotlib、Mlxtend
2、生成示例数据集第一步是生成示例数据集。我们也将为此目的使用 Scikit-learn。首先,创建一个名为 的文件confusion-matrix.py。
(1)导入相关的包
# Imports
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
Scikit-learn的make_blobs功能可以生成样本的“blob”或集群。这些斑点以某个点为中心,并且样本基于某个标准偏差分散在该点周围。这使您可以灵活地确定生成的数据集的位置和结构,从而使您可以试验各种 ML 模型。
在评估模型时,我们需要确保数据集在训练数据和测试数据之间进行分割。Scikit-learn使用train_test_split函数实现分割。
(2)相关配置
# Configuration options
blobs_random_seed = 42
centers = [(0,0), (5,5), (0,5), (2,3)]
cluster_std = 1.3
frac_test_split = 0.33
num_features_for_samples = 4
num_samples_total = 5000
随机种子描述了用于生成数据块的伪随机数生成器的初始化。您可能知道,没有随机数生成器是真正随机的。更重要的是,它们的初始化方式也不同。配置固定种子可确保每次运行脚本时,随机数生成器都以相同的方式初始化。如果出现奇怪的行为,您就知道它可能不是随机数生成器。
中心描述了我们数据块的二维空间中的中心。如您所见,我们今天有 4 个 blob。
聚类标准差描述了从随机点生成器使用的抽样分布中抽取样本的标准差。我们将其设置为 1.3;较低的数字会产生更好分离的集群,反之亦然。
训练/测试拆分的比例决定了为了测试目的拆分了多少数据。在我们的例子中,这是 33% 的数据。
我们样本的特征数量是 4,并且确实描述了我们有多少目标:4,因为我们有 4 个数据块。
最后,生成的样本数量。我们将其设置为 5000 个样本。
(3)生成数据
# Generate data
inputs, targets = make_blobs(n_samples = num_samples_total, centers = centers, n_features = num_features_for_samples, cluster_std = cluster_std)
X_train, X_test, y_train, y_test = train_test_split(inputs, targets, test_size=frac_test_split, random_state=blobs_random_seed)
(4)保存数据(可选)
# Save and load temporarily
np.save('./data_cf.npy', (X_train, X_test, y_train, y_test))
X_train, X_test, y_train, y_test = np.load('./data_cf.npy', allow_pickle=True)
(5)可视化数据
# Generate scatter plot for training data
plt.scatter(X_train[:,0], X_train[:,1])
plt.title('Linearly separable data')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()

(1)导入相关包
from sklearn import svm
from sklearn.metrics import plot_confusion_matrix
from mlxtend.plotting import plot_decision_regions
(2)训练分类器
# Initialize SVM classifier
clf = svm.SVC(kernel='linear')
# 拟合数据
clf = clf.fit(X_train, y_train)
4、生成混淆矩阵
它是评估步骤的一部分,我们用它来可视化它在测试集上的预测和泛化能力。
使用plot_confusion_matrix调用为我们解决了这个问题,我们只需向它提供分类器 (clf)、测试集 (X_test和y_test)、颜色图以及是否对数据进行归一化。
# Generate confusion matrix
matrix = plot_confusion_matrix(clf, X_test, y_test,
cmap=plt.cm.Blues,
normalize='true')
plt.title('Confusion matrix for our classifier')
plt.show(matrix)
plt.show()

如果要生成边界图,需要安装 Mlxtend
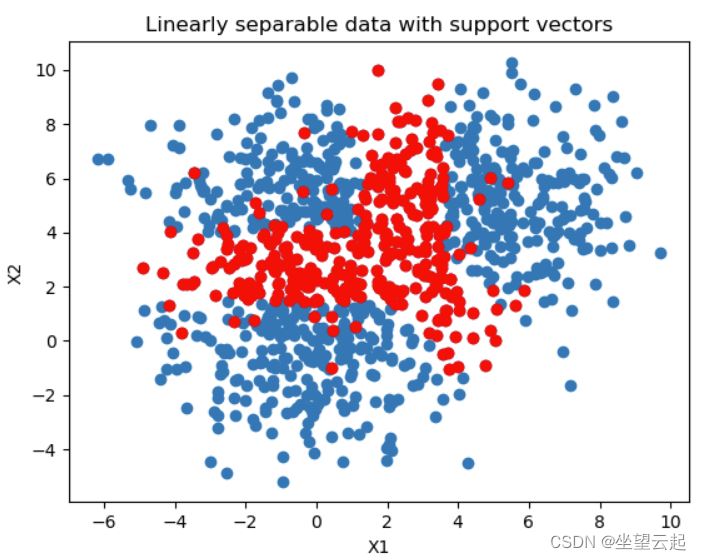
# Get support vectors
support_vectors = clf.support_vectors_
# Visualize support vectors
plt.scatter(X_train[:,0], X_train[:,1])
plt.scatter(support_vectors[:,0], support_vectors[:,1], color='red')
plt.title('Linearly separable data with support vectors')
plt.xlabel('X1')
plt.ylabel('X2')
plt.show()
# Plot decision boundary
plot_decision_regions(X_test, y_test, clf=clf, legend=2)
plt.show()


唯一表现不佳的班级是第 3 类,得分为 0.68。这可以通过查看决策边界图中的类来解释。在这里,由于这些样本被其他样本包围,很明显模型在生成决策边界时遇到了很大的困难。例如,我们可以通过使用考虑到这一点的不同内核函数来解决这个问题,从而确保更好的可分离性。
以上就是我们使用 Python 和 Scikit-learn 创建了一个混淆矩阵。在研究了混淆矩阵是什么,以及它如何显示真阳性、真阴性、假阳性和假阴性之后,我们给出了一个自己创建示例。
该示例包括生成数据集、为数据集选择合适的机器学习模型、构建、配置和训练它,最后解释结果,即混淆矩阵。
到此这篇关于使用Python和scikit-learn创建混淆矩阵的文章就介绍到这了,更多相关Python和scikit-learn混淆矩阵内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!