《Bilinear Attention Networks》论文笔记
总得来说,这篇文章较为抽象,理解起来相当费劲。很多地方加入了个人描述语句,如果有理解不当的地方,还望指出。
1. Abstract协同注意力机制 ( Co-Attention ) 对每个模态的输入建立各自的注意力分布,忽略模态输入间的相互关联,这可以有效的降低计算开销。本文就是在协同注意力机制的基础上更进一步,考虑不同模态的输入的通道间的相互关联。以 VQA 为例,本文是为了发掘 Question 和 Image 在不同通道间的注意力分布,然后建立两者间的相互关联,最后以联合表征的形式输出信息。同时本文还提出了 MRN 变体,可以用来学习多模态输入间的关系,究其本质通过残差连接方式,学习多个注意力分布图。
2. Low-rank bilinear pooling模型架构这里主要分为:(1) 回顾低秩双线性池化(Low-rank bilinear pooling),(2) 描述双线性注意力网络(Bilinear Attention Network),BAN 是在 MLB 的基础上改进。简单来说,MLB 通过池化得到多模态联合表征,进一步得到注意力分布,再通过信息加权最后得到加入注意力机制的多模态联合表征。而对 BAN 来说,池化后得到多个注意力分布图,通过残差方式连接方式将注意力机制融入多模态联合表征信息。
在 Low-rank bilinear pooling 中,模型的输入有 x,yx,yx,y,前者是单通道(对应于 Question 向量),后者是多通道的(对应于 Image 的特征向量),通过融合输入,得到单通道的中间层次的表征信息(对应于注意力特征向量)
2.1 Low-rank bilinear model整个的模型的任务是学习参数矩阵 WiW_iWi,由于 WiW_iWi 可能维度过高,导致参数过多,会增加计算开销。但是由于WiW_iWi 是低秩矩阵,通过低秩矩阵分解,将 WiW_iWi 近似分解成两个小矩阵,则有:Wi≈UiViTW_i \approx U_iV_i^TWi≈UiViT,因此有如下推导:
fi=xTWiy≈xTUiViTy=1T(UiTx ∘ViTy) (1)
f_i=x^TW_iy \approx x^TU_iV_i^Ty= 1^T(U_i^Tx \ \circ V_i^Ty) \ \ \ \ \ \ \ \ \ \ (1) \\
fi=xTWiy≈xTUiViTy=1T(UiTx ∘ViTy) (1)
引入池化矩阵 PPP 可以控制输出长度(在本文中映射成标量),通过双线性池化融合两个模态的特征向量:
f=PT(UTx ∘VTy) (2)
f = P^T(U^Tx \ \circ V^Ty) \ \ \ \ \ \ \ \ \ \ (2) \\
f=PT(UTx ∘VTy) (2)
对多通道输入 YYY 由集合 ϕ=∣{yi}∣\phi=|\{y_i\}|ϕ=∣{yi}∣,通过注意力机制得到单通道向量 y^\hat{y}y^:
y^=∑iαiyi (3)
\hat{y} = \sum_i \alpha_iy_i \ \ \ \ \ \ \ \ \ \ (3) \\
y^=i∑αiyi (3)
使用 Low-rank bilinear pooling 结果,由 Softmax 做归一化得到注意力分布 αi\alpha_iαi :
α=softmax(PT((UTx⋅1T)∘(VTY))) (4)
\alpha = softmax(P^T((U^Tx \cdot 1^T) \circ(V^TY))) \ \ \ \ \ \ \ \ \ \ (4) \\
α=softmax(PT((UTx⋅1T)∘(VTY))) (4)
前面提到的 MLB 是对单个模态特征的 Attention, 即 output=feature * attention map ,但是 BAN 是对两个模态特征的 Attention, output=feature1 * bilinear attention map * feature2
设两个多通道输入为:X∈RN×ρX \in \mathbb{R}^{N \times \rho}X∈RN×ρ,Y∈RM×ϕY \in \mathbb{R}^{M \times \phi}Y∈RM×ϕ,其中第二个维度表示通道数。引入注意力分布矩阵 AAA :
fk′=(XTU′)kTA(YTV′)k=∑i=1ρ∑j=1ϕAi,j(XiTUk′)(Vk′TYj)=∑i=1ρ∑j=1ϕAi,jXiT(Uk′Vk′T)Yj (5)
f_k^{'}=(X^TU^{'})_k^TA(Y^TV^{'})_k=\sum_{i=1}^{\rho}\sum_{j=1}^{\phi}A_{i,j}(X_i^TU_k^{'})(V_k^{'T}Y_j)=\sum_{i=1}^{\rho}\sum_{j=1}^{\phi}A_{i,j}X_i^T(U_k^{'}V_k^{'T})Y_j \ \ \ \ \ \ \ \ \ \ (5)
fk′=(XTU′)kTA(YTV′)k=i=1∑ρj=1∑ϕAi,j(XiTUk′)(Vk′TYj)=i=1∑ρj=1∑ϕAi,jXiT(Uk′Vk′T)Yj (5)
上述公式从代数的角度来说的话,即通过 AAA 所描述线性关系融合两个不同模态的输入,相当于建立了两个模态各自通道间的关联,得到融合后的双线性池化矩阵 f′f^{'}f′ (设秩为 KKK),再经过池化操作,得到了两个模态输入的联合表征 f=PTf′f = P^Tf^{'}f=PTf′ ,为了简单起见,定义整个过程:
f=BAN(X,Y;A) (6)
f = BAN(X, Y; A) \ \ \ \ \ \ \ \ \ \ (6) \\
f=BAN(X,Y;A) (6)
其中 BAN 的注意力分布 AgA_gAg 类似于 Low-rank bilinear pooling 中的 (4) 式计算:
Ag=softmax(((1⋅pgT)∘XTU)VTY) (7)
A_g = softmax(((1 \cdot p_g^T) \circ X^TU)V^TY) \ \ \ \ \ \ \ \ \ \ (7) \\
Ag=softmax(((1⋅pgT)∘XTU)VTY) (7)
这个公式是本文最大的创新点,下标 ggg 表明了 glimpse 的标号。直观上来说,相当于生成 ggg 个注意力图。那么另一个问题是如何控制输出的数量?这就需要通过 pgp_gpg 映射到指定的维度。
前面的过程,我们得到了多个注意力分布图。受 MRN 启发,提出 MRN 变体来整合多重双线性注意力分布(其实残差连接方式的提出可以处理多模态输入的问题):
fi+1=BANi(fi,Y;Ai)⋅1T+fi (8)
f_{i+1}=BAN_i(f_i,Y;A_i) \cdot 1^T + f_i \ \ \ \ \ \ \ \ \ \ (8) \\
fi+1=BANi(fi,Y;Ai)⋅1T+fi (8)
对最后一次输出,沿通道这一维度求和。由于矩阵链乘法和低秩分解的性质, BAN 的时间复杂度与一个多通道输入相同。以 VQA 问题,输入为图像和问题。具体的网络架构如下所示:生成了两个注意力分布图,然后通过残差连接方式输出加入注意力机制的联合表征信息,送入 MLP 预测结果。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bYsDXJzr-1581906928200)(../Image/BAN/1.png)]](/upload/wp-content/uploads/2020/02/20200217103656866.png)
BAN 的非线性函数使用的 ReLU:
fk′=σ(XTU′)kT ⋅A ⋅σ(YTV′)k (9)A:=((1⋅pT)∘σ(XTU))⋅σ(VTY) (10)
f_k^{'}=\sigma(X^TU^{'})_k^T \ \cdot A \ \cdot \sigma(Y^TV^{'})_k \ \ \ \ \ \ \ \ \ \ (9) \\
A := ((1 \cdot p^T) \circ \sigma(X^TU)) \cdot \sigma(V^TY) \ \ \ \ \ \ \ \ \ \ (10) \\
fk′=σ(XTU′)kT ⋅A ⋅σ(YTV′)k (9)A:=((1⋅pT)∘σ(XTU))⋅σ(VTY) (10)
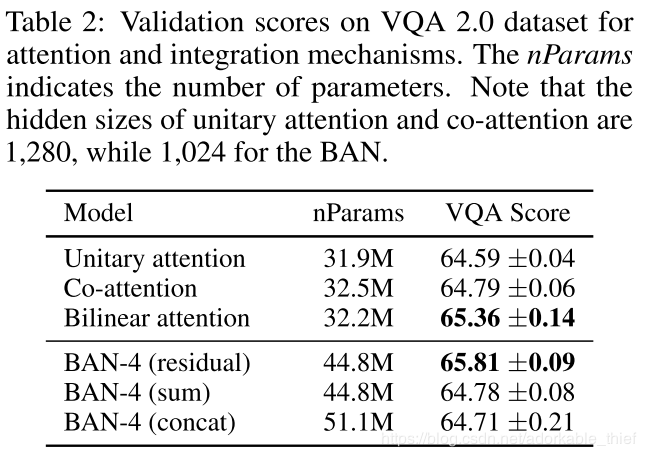
具体的实验参数这里不再赘述,有需要了解的可以参照原论文。在 VQA2.0 上,对 Unitary attention,Co-Attention 和 BAN 的实验比较(其实这里我一直认为 BAN 也归类为 Co-Attention),从实验结果表明,使用残差连接要比求和与 concatenate 的融合机制在参数数量与性能上都要好。
下图的 (d) 也是挺有意思的,在模型 BAN-4 中计算 4 个注意力图的信息熵:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xAXMW6vB-1581906928201)(../Image/BAN/3.png)]](/upload/wp-content/uploads/2020/02/20200217103723360.png)
与其他模型的对比结果,注意对于 VQA 比较棘手的计数问题,作者通过在残差网络中结合了计数模块,得到了最好的计数性能表现:
fi+1=(BANI(fi,Y,Ai)+gi(ci))⋅1T+fi (11)
f_{i+1} = (BAN_I(f_i,Y,A_i) + g_i(c_i)) \cdot 1^T + f_i \ \ \ \ \ \ \ \ \ \ (11)
fi+1=(BANI(fi,Y,Ai)+gi(ci))⋅1T+fi (11)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ldTtptgS-1581906928201)(../Image/BAN/4.png)]](/upload/wp-content/uploads/2020/02/20200217103742628.png)
《Bilinear Attention Networks》
作者:斜光的博客园