动手深度学习(Pytorch)之路 --- Attention and Transformer
近年来,Attention机制越来越火,在下不才,可能比你们多看了几篇博客,分享一些我对于Attention机制的理解,推荐大家去看李宏毅老师的视频,讲的非常清楚,也可以参考博客。和绝大多数神经网络模型相似,Attention机制最先应用于图像领域,后来逐渐引入到自然语言处理中。经典的论文可以看看这几篇:《Recurrent Models of Visual Attention》、《Neural Machine Translation by Jointly Learning to Align and Translate》、《Attention is all you need》。下面来聊聊Attention机制到底是如何工作的。
我们都知道,相对于卷积神经网络来说,循环神经网络能够更好的处理具有时序特征的数据。然而,在RNN模型中,当前时刻的输入依赖于前一时刻的输出,因此,注定了RNN模型无法完成并行计算,这极大的局限了高效计算的实现,Attention机制的出现恰好解决了这个问题。
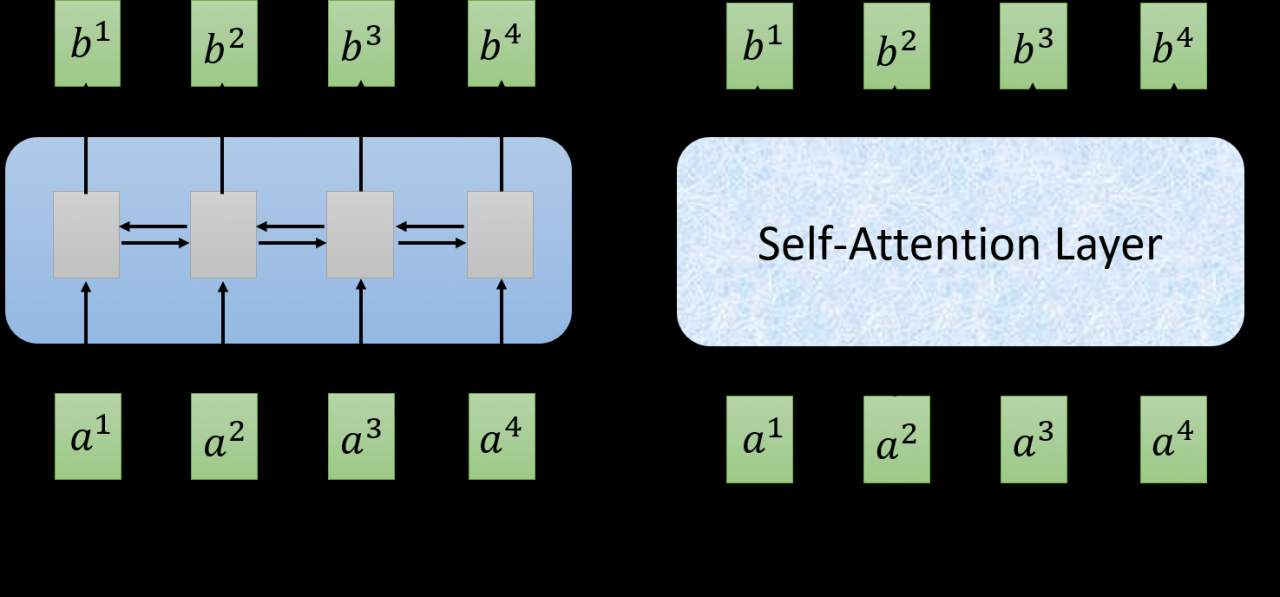
如上图所示,在Attention机制里,所有的输入和输出是并行完成的,没有RNN模型中相互依赖的过程。下面再看看其内部是如何计算的。
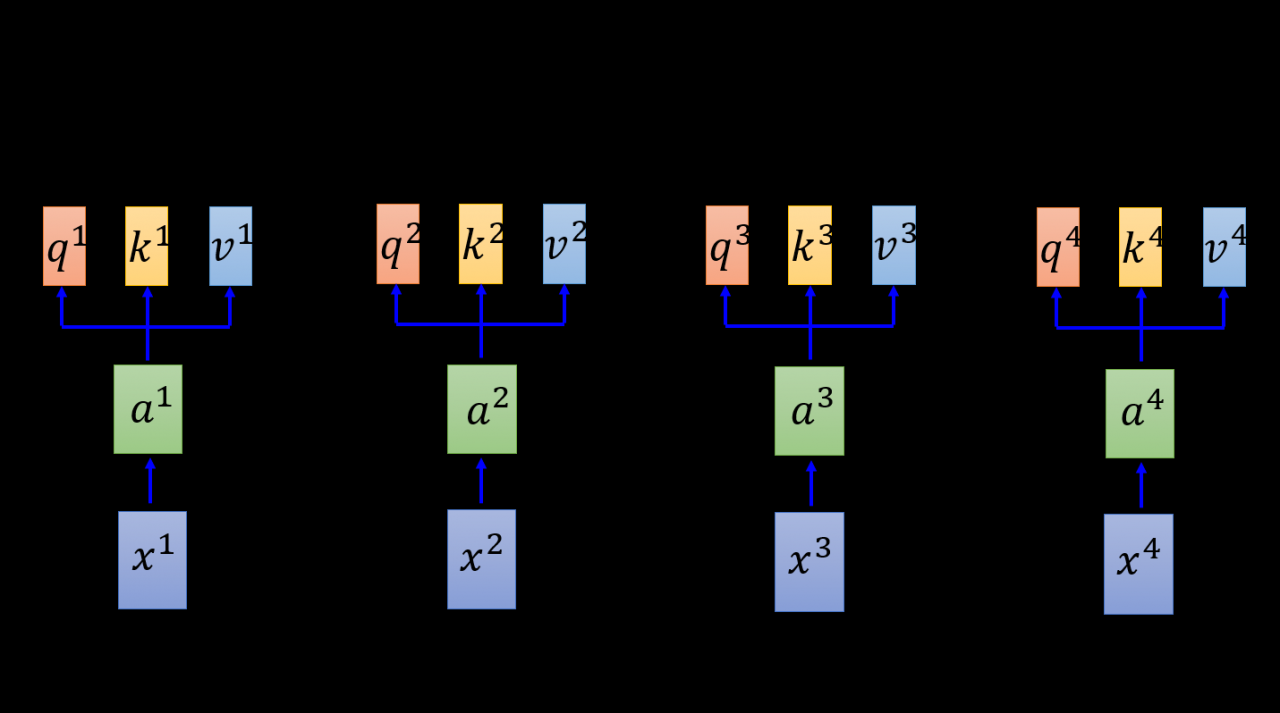
第一步,输入是单个字(词,下面统一用字表示)的idxix^{i}xi,经过Embedding层(Word2Vec或其他工具),产生每次字的字向量aia^{i}ai,这几乎和目前使用的所有模型一致。接着,初始化三个矩阵Wq,Wk,WvW^{q}, W^{k}, W^{v}Wq,Wk,Wv,将aia^{i}ai和矩阵相乘,获得每个id所对应的qi,ki,viq^{i}, k^{i}, v^{i}qi,ki,vi向量。
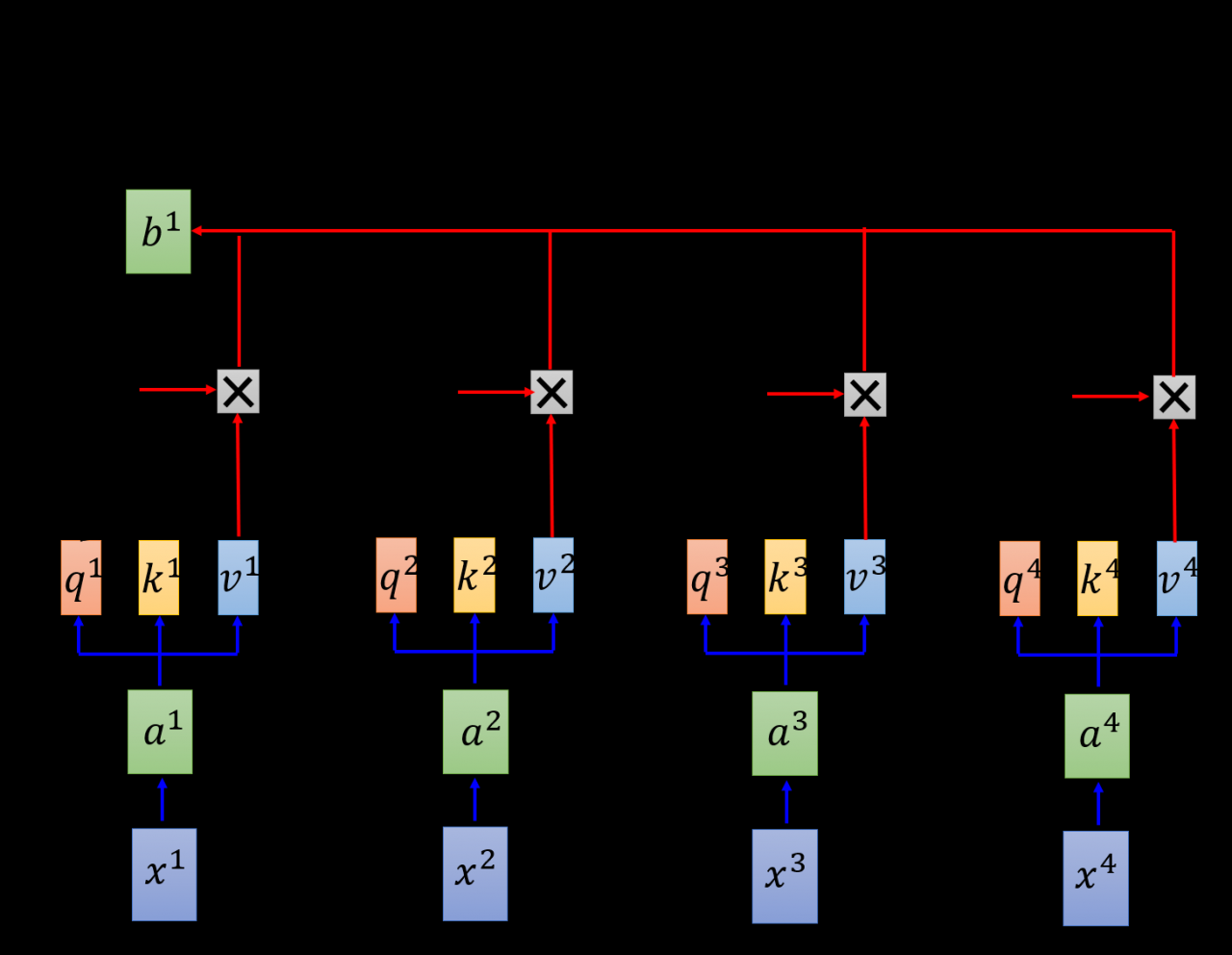
第二步,将q1q^{1}q1与所有的kik^{i}ki进行点积运算α1,i=q1⋅ki/d\alpha _{1,i} = q^{1} \cdot k^{i} / \sqrt{d}α1,i=q1⋅ki/d和softmax激活函数,得到α1,i^\hat{\alpha_{1,i}}α1,i^,接着,α1,i^\hat{\alpha_{1,i}}α1,i^与所有的viv_{i}vi相乘,得到当前节点qiq^{i}qi的输出b1b^{1}b1,以此类推,得出所有的输出。这个过程就是Attention机制的计算过程。
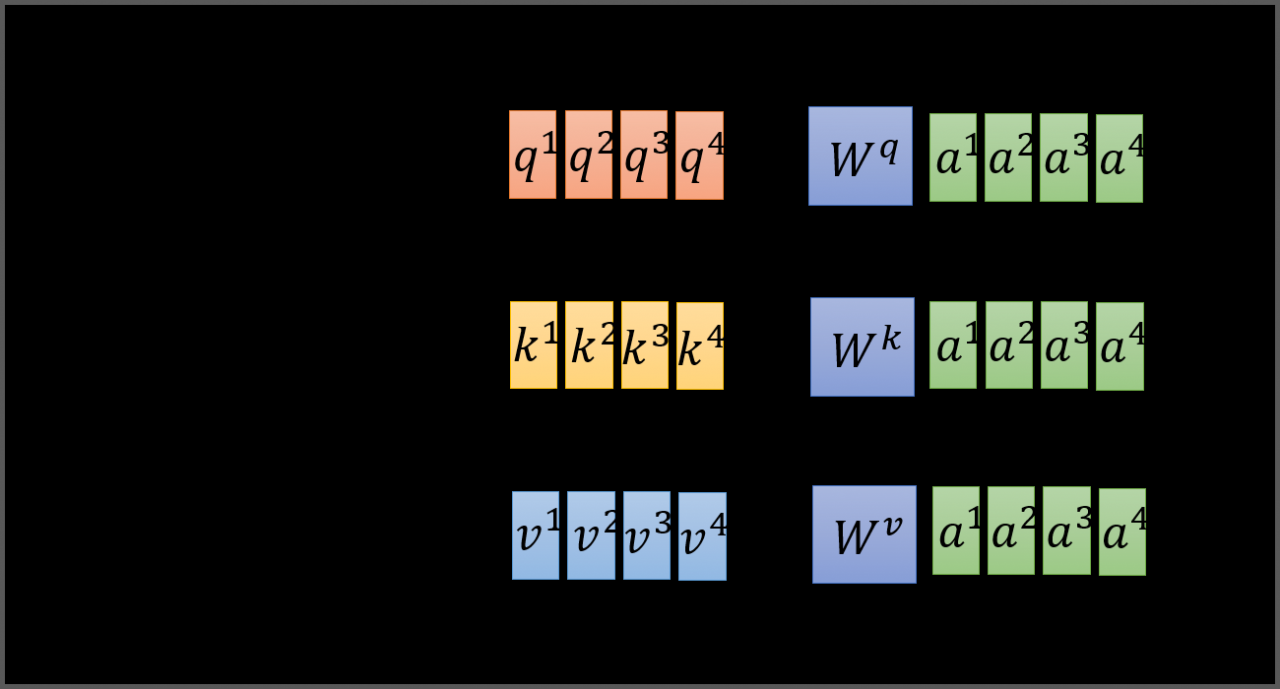
下面谈谈一开始提到的并行计算的问题。如下图所示,我感觉李老师的图已经很清晰了,我就不再啰嗦了。
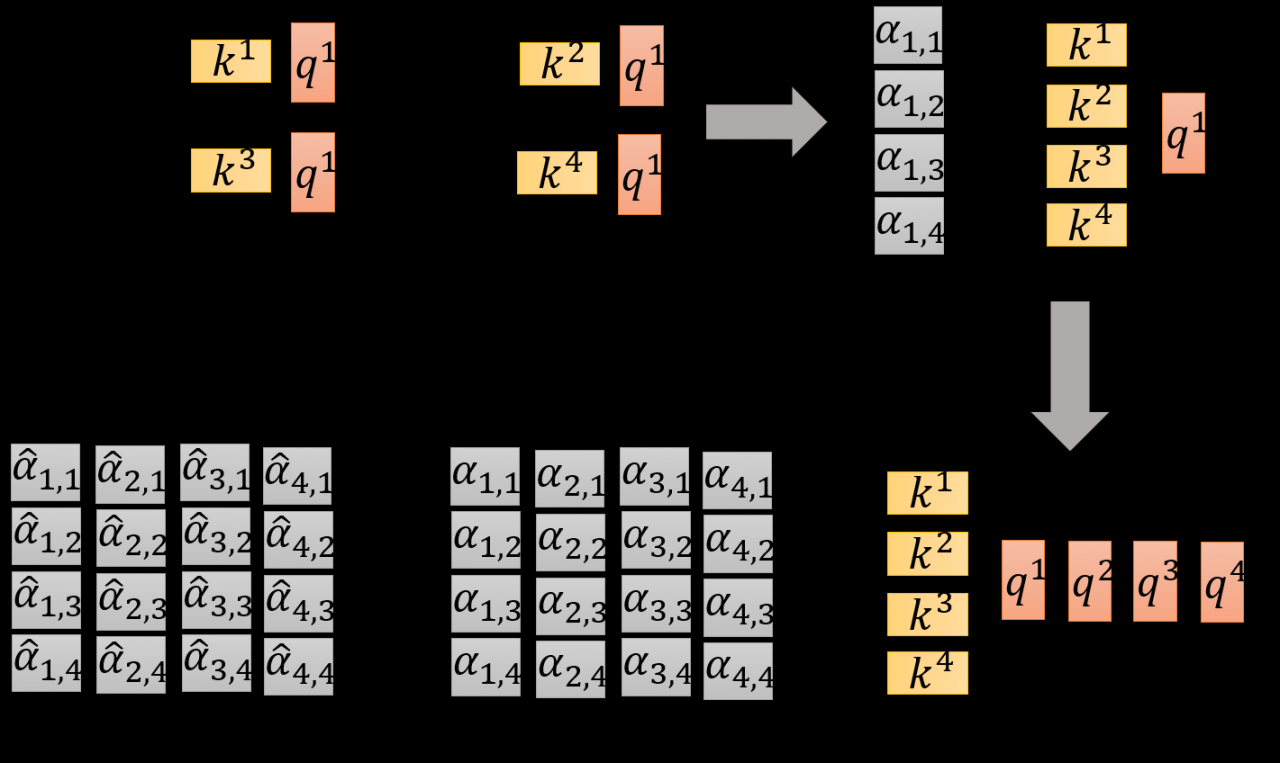
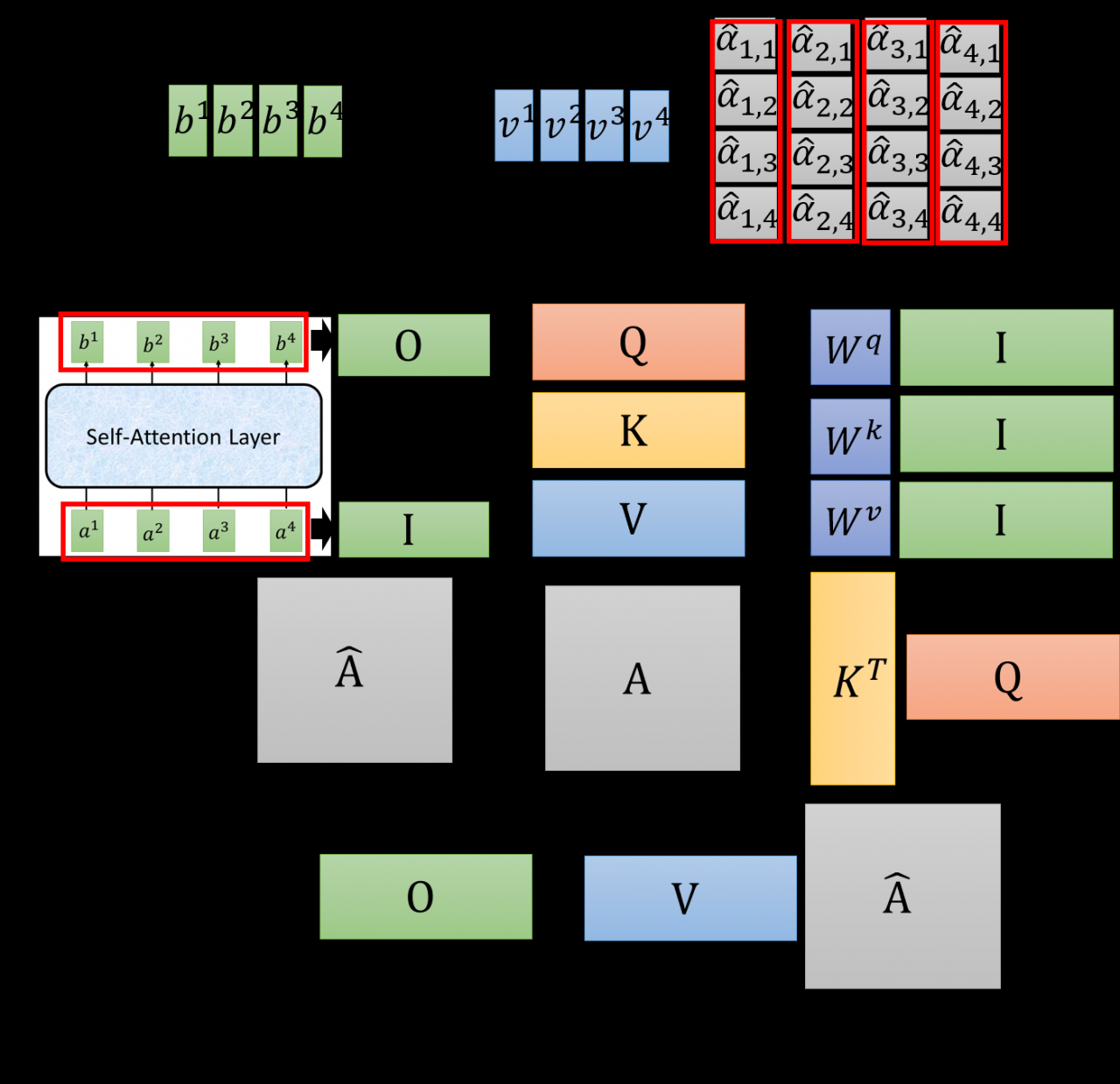
至此,Attention机制的运算就结束了。
19年可以说是NLP最火爆的一年,无他,BERT模型在11项NLP任务中打遍天下,未逢敌手,引爆了整个NLP界对于词向量模型的研究。而BERT取得成功的一个关键因素是Transformer的强大作用。而Transformer又是由Attention堆叠而成的,下面来看看Transformer做了哪些优化。
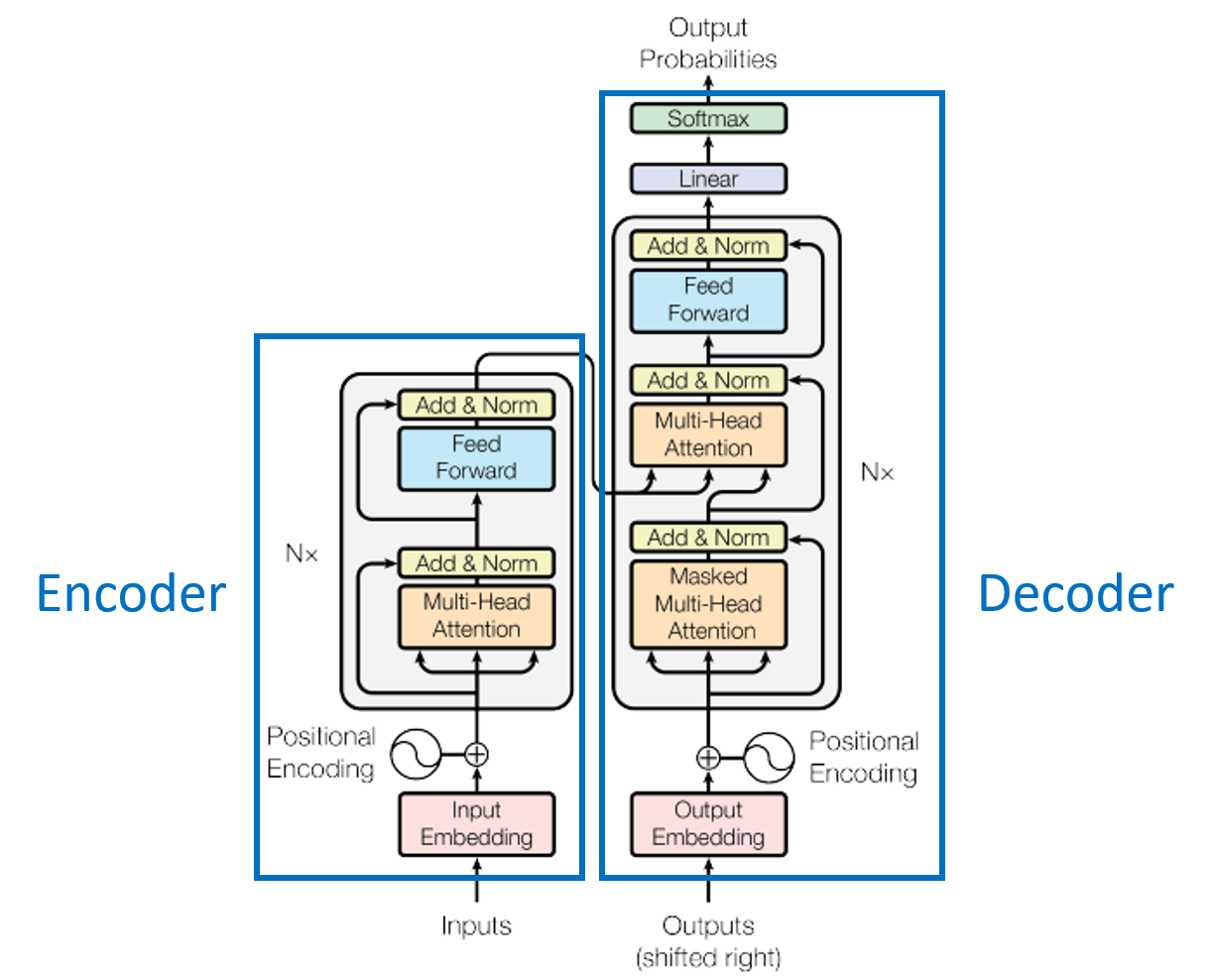
这就是Transformer的模型图,由两部分构成:Encoder和Decoder。
其实Decoder和Encoder部分的机构基本是相同的,先来看看Encoder部分。Encoder结构也可以分为三部分:首先是输入,然后是self-Attention层,最后是Position-wise FFN层,后面两部分组成了Encoder的基础结构单元,在Transformer中,这个单元被重复了N次。
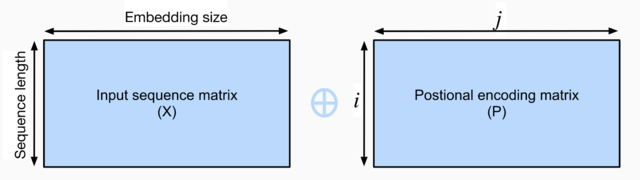
输入:在传统的Embedding基础上,Transformer的输入增加了一个Positional Encoding结构,我们称之为位置信息。位置信息是一个二维矩阵,其计算公式如下,其中,iii对应的是该单词在居中的位置(i=1,2,3...{i = 1,2,3...}i=1,2,3...),jjj对应的是在Embedding中,目前是第jjj个向量。
Pi,2j=sin(i/100002j/d)P_{i,2j} = sin(i / 10000^{2j/d})Pi,2j=sin(i/100002j/d) Pi,2j+1=cos(i/100002j/d)P_{i,2j+1} = cos(i / 10000^{2j/d})Pi,2j+1=cos(i/100002j/d)
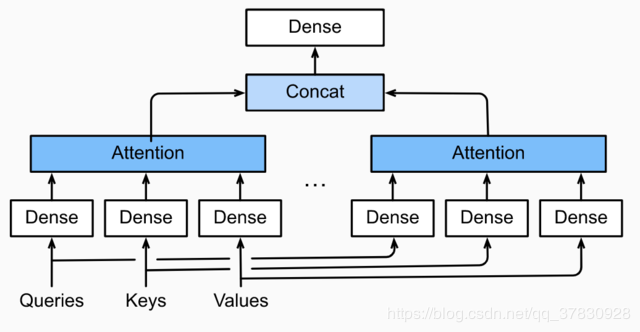
self-Attention层:多头注意力层包含 hhh个并行的自注意力层,每一个这种层被成为一个head,其实就是上面的Attention层并行计算了hhh次,然后将hhh个输出直接进行拼接即可。
Position-wise FFN层:接受一个形状为(batch_size,seq_length, feature_size)的三维张量。Position-wise FFN由两个全连接层组成,他们作用在最后一维上。因为序列的每个位置的状态都会被单独地更新,所以我们称他为position-wise,这等效于一个1x1的卷积。
值得注意的是,在Transformer中,使用了残差网络的思想,首先将前一层的输入进行Layer Norm,然后连接到下一层中进行运算,即模型图中的Add & Norm模块。
最后,将这个Encoder结构连接N层,就完成了整个Encoder部分。
Decoder的结构和Encoder是非常相似的,这从模型图也可以看出来。
对于Decoder来说,可以分为两个模块。第一个模块中,预测的句子作为输入,和Encoder的输入相同,Embedding加上Positional encoding作为输入,在这里有一个Masked的处理,是因为在机器翻译的时候,解码器只能根据前边出现的单词预测下一单词。所以,需要将句中当前时刻以后的词信息进行Masked处理,然后就是同样的Attention计算和Add & Norm操作。第二个模块接收Encoder的输出作为Attention机制的KKK和QQQ矩阵,第一个模块的输出作为Attention机制的VVV矩阵。用这三个矩阵和Encoder结构做同样的计算,并且堆叠N层,作为Decoder结构的输出。最后在经过全连接层,映射到字典中,预测下一个词的概率。
Transformer是在Attention基础上进行的堆叠,不仅计算速度更快,在翻译任务上也获得了更好的结果。
作者:FNLP