【人工智能学习】【十六】Self Attention和Transformer
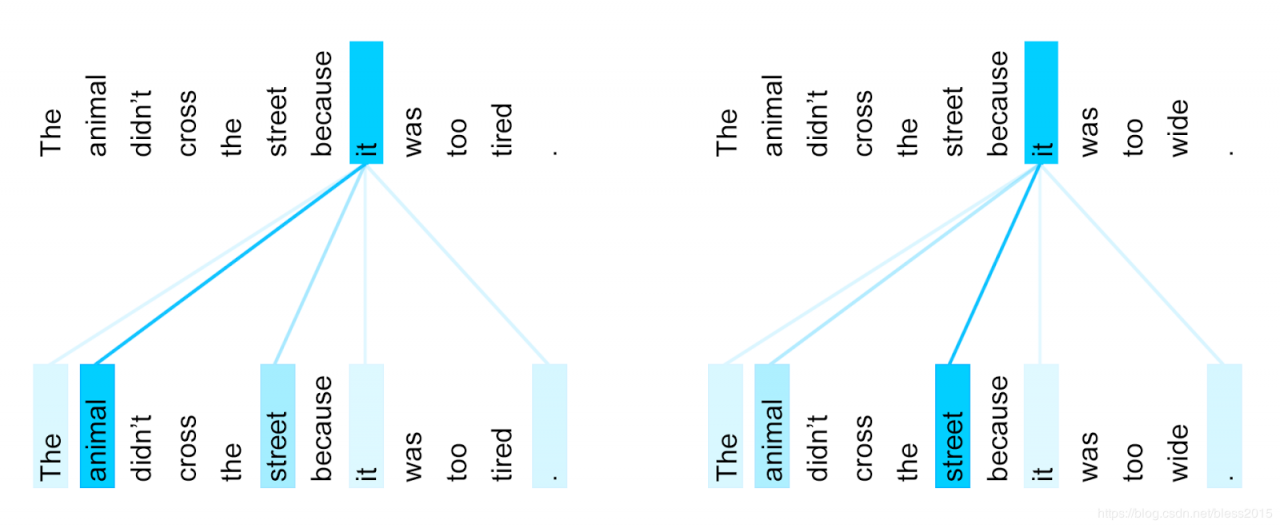
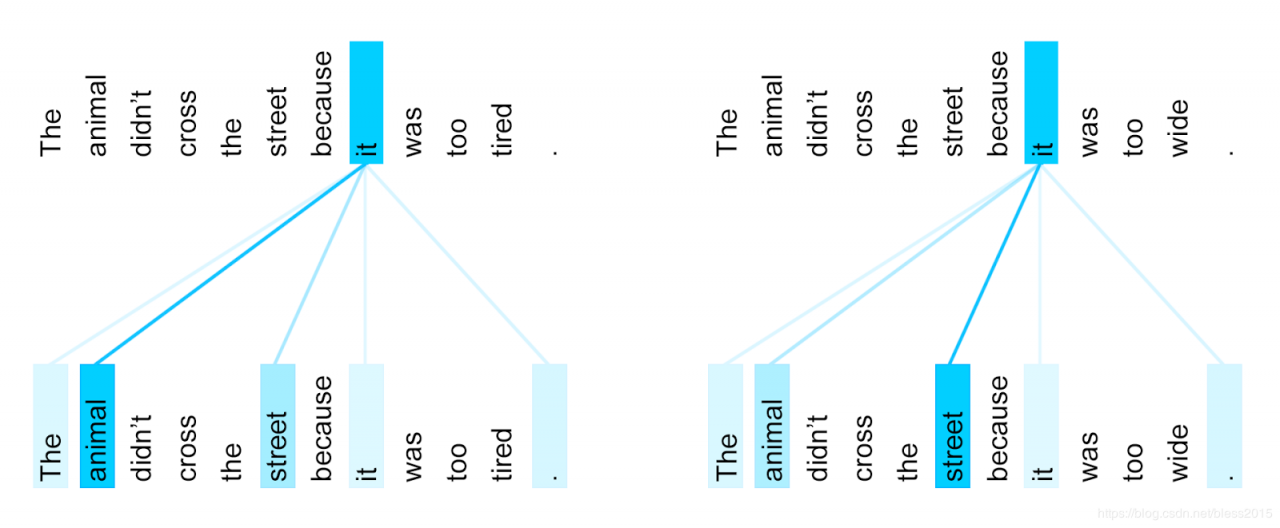
Attention机Decoder是输出元素和Encoder中的输入元素做attention,说的是翻译的结果和输入的哪些信息有关。 Self Attention则是Encoder中的信息自己对自己做attention,说的是自己这一句话内容之间的关系,比如The cat wants to cross the street,but it to tired。it指的是cat。
The cat wants to cross the street,but it to wide。it指的是street。
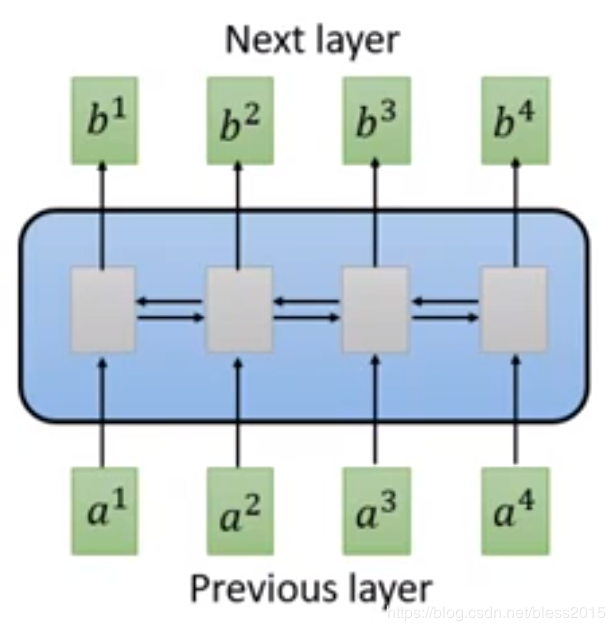
在做有attention的RNN时,encoder部分会输出一个attention值(Decoder和Encoder做的attention),从结构上来说就是如下这个样子。(图中蓝色方框是一个双向的RMM)本质上来说我们想在Encoder部分,给定一个输入,得到一个attention输出,那么这里的RNN,可以用Self Attention Layer来替代。
做如下变换
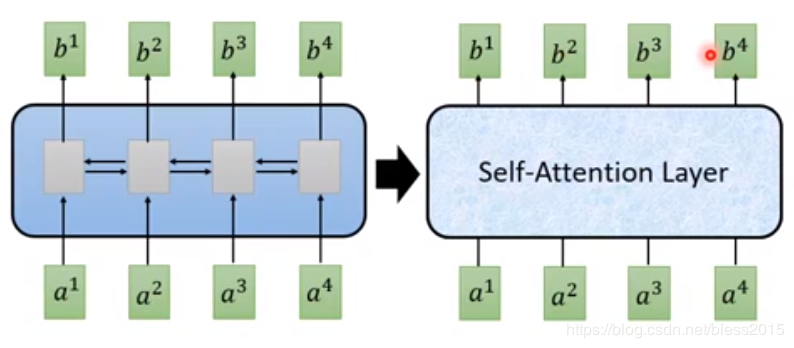
Self Attention的b1b^1b1、b2b^2b2、b3b^3b3、b4b^4b4是可以并行计算的,原来的Attention是不能的。【人工智能学习】【十三】注意力机制与Seq2Seq模型
你可以在用RNN的地方,全部替换成可并行计算的Self Attention Layer。
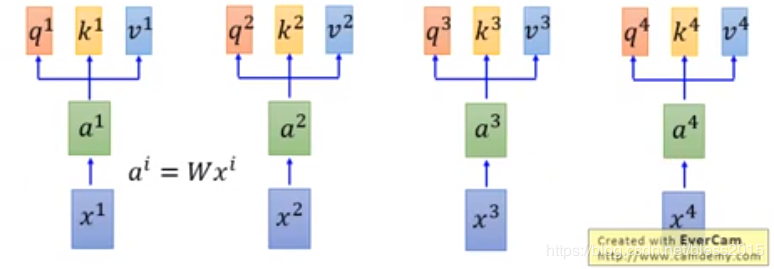
做线性变换
ai=Wxia^i=Wx^iai=Wxi
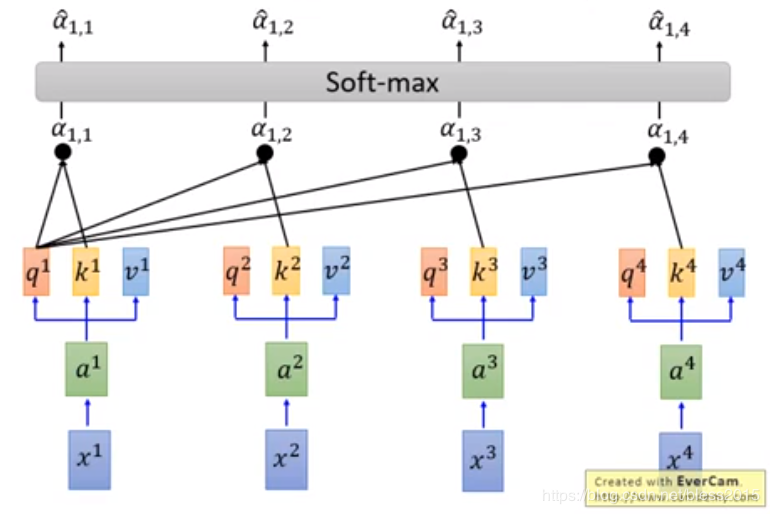
q:query(用来匹配其他的,百度搜索框里输入的关键词)
qi=Wqaiq^i=W^qa^iqi=Wqai
k:key(被匹配的那个)
ki=Wkaik^i=W^ka^iki=Wkai
v:value(k包含的信息)
vi=Wvaiv^i=W^va^ivi=Wvai
query和key来做字符匹配变换
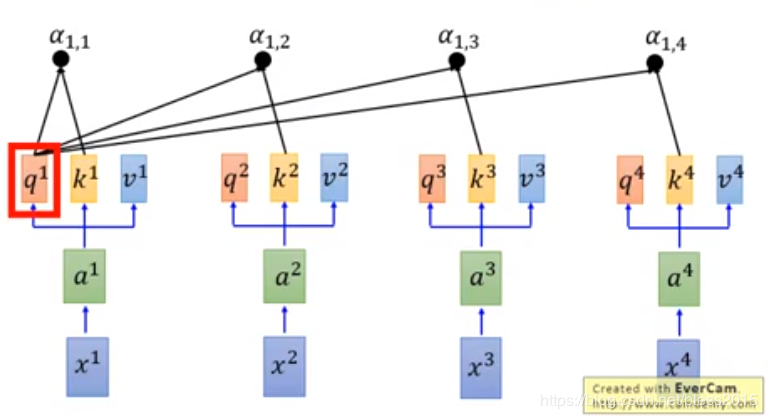
a1,i=q1⋅ki/da_{1,i}=q^1·k^i{/}\sqrt{d}a1,i=q1⋅ki/d
之所以要sqrtdsqrt{d}sqrtd,论文上是说a1,ia_{1,i}a1,i的大小会根据q和k的dim来增加,为了排除dim的影响。
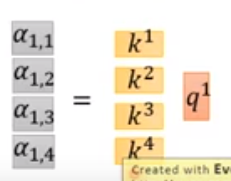
q1q^1q1和k1k^1k1得到了a1,1a_{1,1}a1,1
q1q^1q1和k2k^2k2得到了a1,2a_{1,2}a1,2
q1q^1q1和k3k^3k3得到了a1,3a_{1,3}a1,3
q1q^1q1和k4k^4k4得到了a1,4a_{1,4}a1,4
a1,iˊ=ea1,i∑jea1,j\acute{a_{1,i}}=\frac{e^{a_{1,i}}}{\sum_je^{a_{1,j}}}a1,iˊ=∑jea1,jea1,i
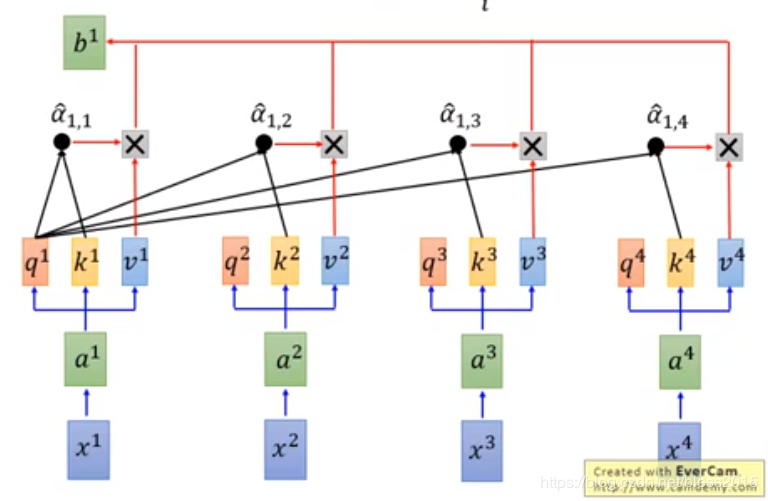
b1=∑ia1,iˊvib^1=\sum_i\acute{a_{1,i}}v^ib1=i∑a1,iˊvi
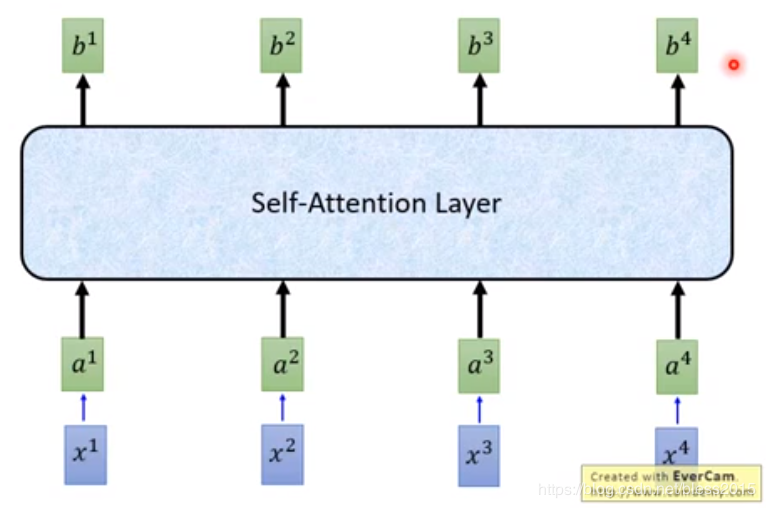
同样的操作可以算出类b2b^2b2、b3b^3b3、b4b^4b4,最后的bib^ibi就是Self Attention的state矩阵
最终将RNN变成了如下这张图的结构
第一步的并行化
q1=Wqa1q^1=W^qa^1q1=Wqa1
q2=Wqa2q^2=W^qa^2q2=Wqa2
q3=Wqa3q^3=W^qa^3q3=Wqa3
q4=Wqa4q^4=W^qa^4q4=Wqa4
上式等价于
Q=WqIQ=W^qIQ=WqI
同理
K=WkIK=W^kIK=WkI
V=WvIV=W^vIV=WvI
第二步的并行化
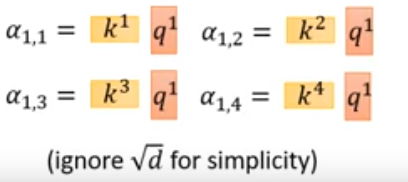
得到
推广到所有input
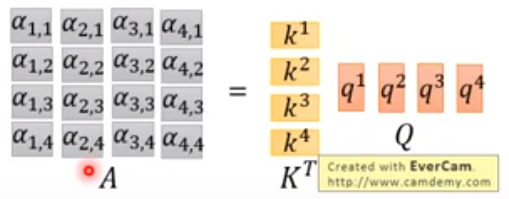
把A进行softmax

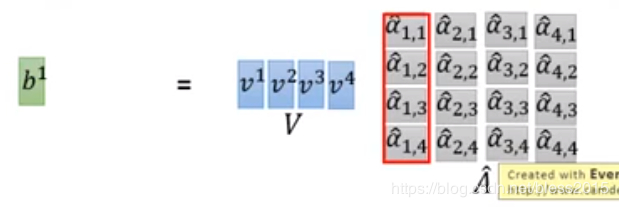
b1b_1b1的计算变成如下:
推广到所有bib_ibi
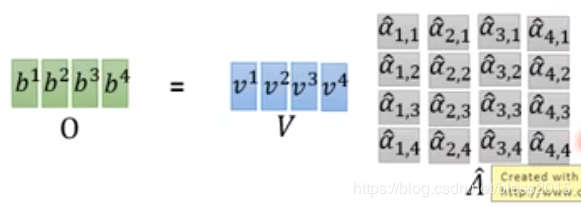
最终的计算图如下,矩阵乘法可以在GPU中很快的计算
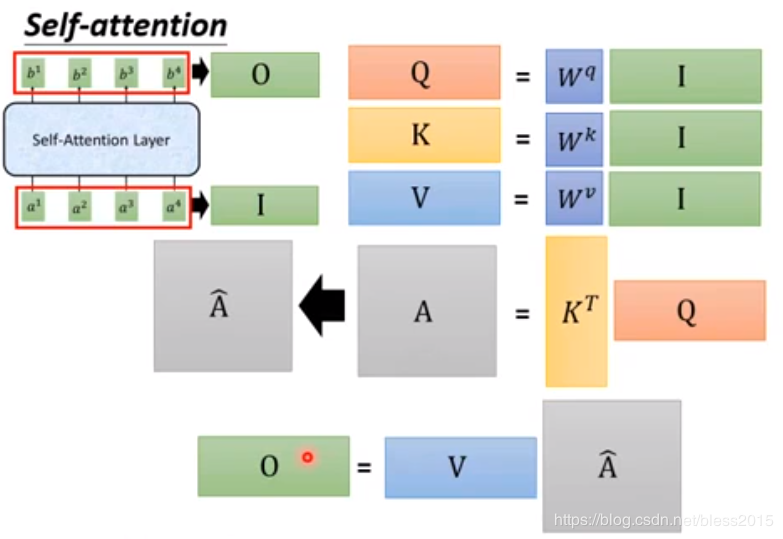
此时我们想,注意力是不是可以多个?将qqq继续做变换
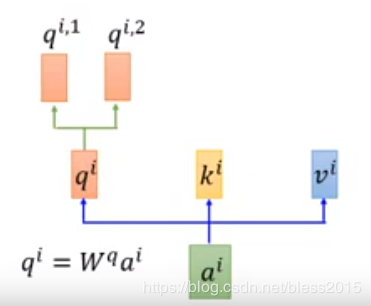
qi,1=Wq,1qiq^{i,1}=W^{q,1}q^iqi,1=Wq,1qi
qi,2=Wq,2qiq^{i,2}=W^{q,2}q^iqi,2=Wq,2qi
推广到KKK和VVV
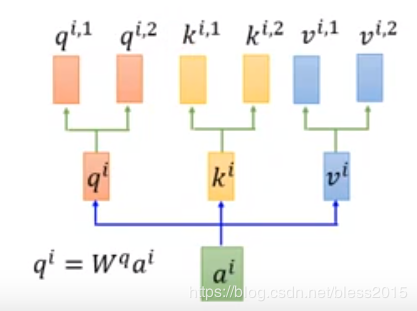
计算方式呢,两条线互补干扰,qi,1q^{i,1}qi,1只和ki,1k^{i,1}ki,1、kj,1k^{j,1}kj,1做变换。
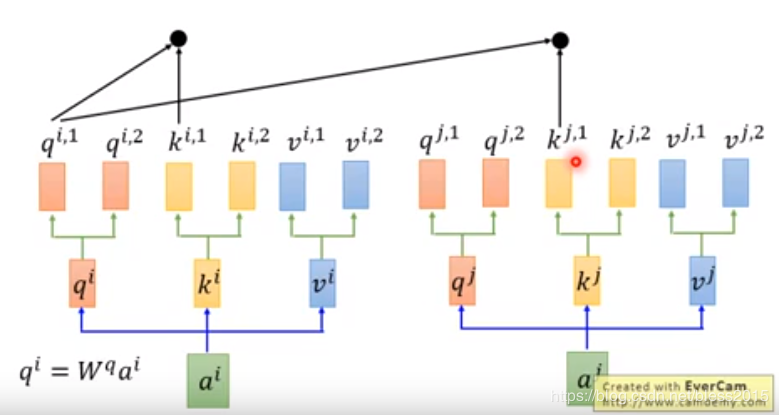
这样计算得出bi,1b^{i,1}bi,1
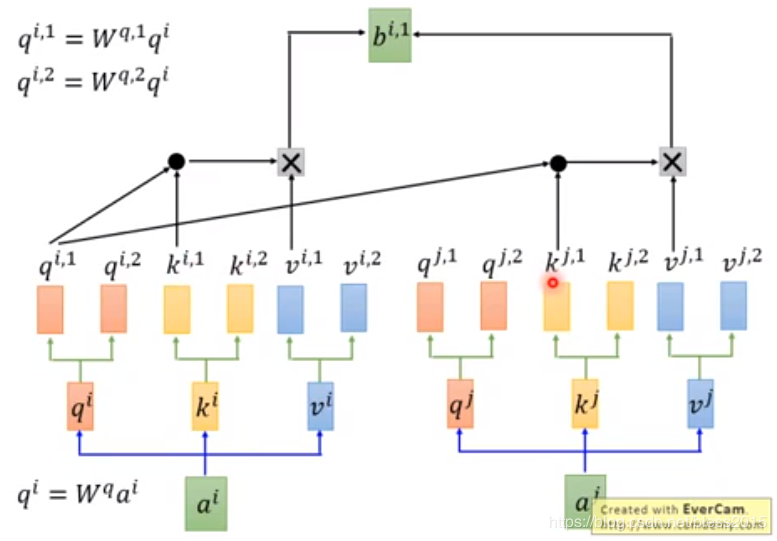
multi-head的数量在代码里是可以配置的,这里以multi-head=2为例
即最后得到bi,1b^{i,1}bi,1和bi,2b^{i,2}bi,2,做如下变换得到bib^ibi
bi=Wobi,1bi,2b^i=W_o{ \begin{matrix}
b^{i,1} \\
b^{i,2} \\
\end{matrix}}bi=Wobi,1bi,2
既然self-attention可以并行计算attention,意味着不在注意词的先手顺序,但是“张三打了李四”,这句话是有顺序性的,顺序颠倒后的含义就反了。为此self attention在输入上增加了一个表示顺序信息的向量:
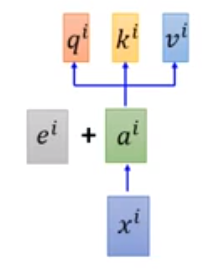
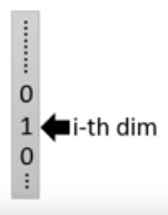
这个eie^iei呢是一个由0和1构成的向量,长度和字典长度相同,xix^ixi所在的位置是1,其他为0。这里做的是一个向量加法运算(用concat可以吗)。这个eie^iei是一个超参数,不是模型学习得到的。
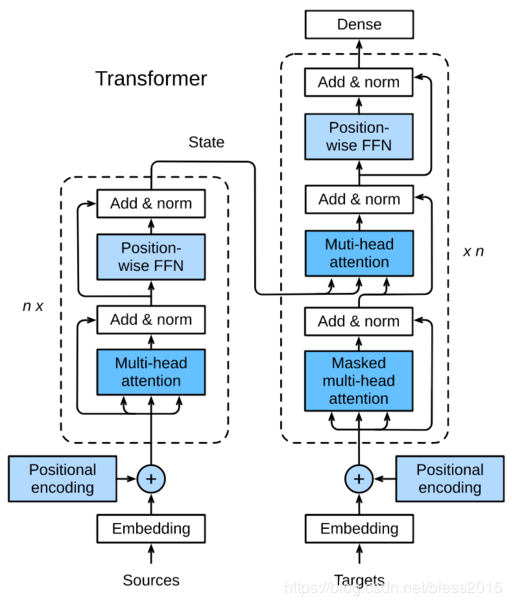
Transformer 是 Google 团队在2017年6月提出的 NLP 经典之作,由 Ashish Vaswani 等人在2017年发表的论文 Attention Is All You Need 中提出。其结构如下。
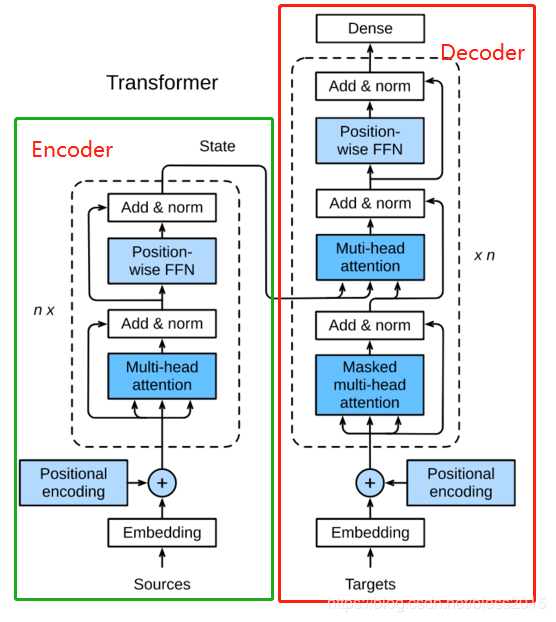
这张图很多地方都有,但是一上来就放这张图相信很多同学和我一样看得云里雾里。我们来分析一下。首先这是一个Encoder-Decoder模型
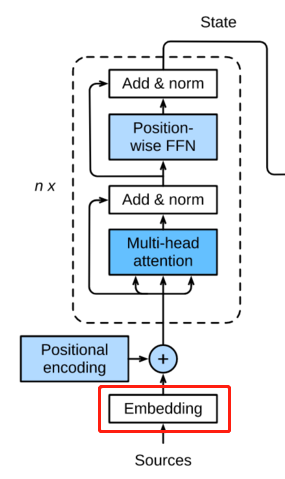
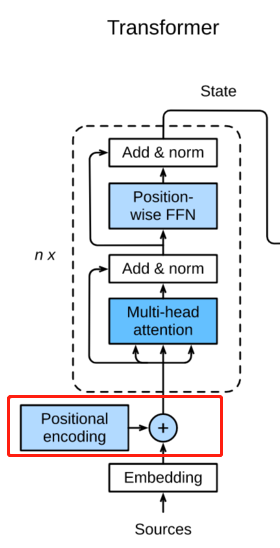
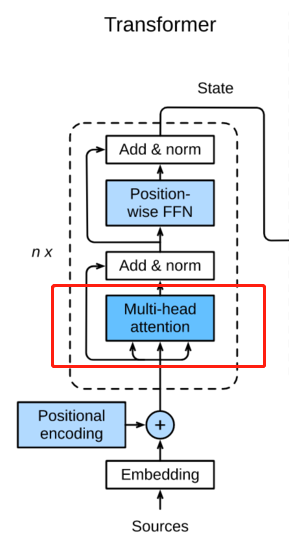
这个multi-head就是如下结构
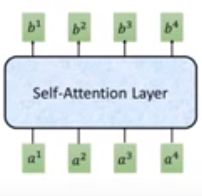
经过这一层后,将输入aia^iai变成了另一个序列bib^ibi
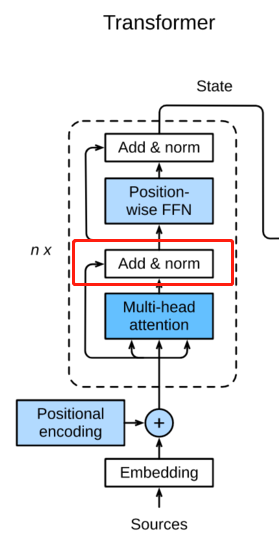
这理是两个操作,第一个Add,第二个是Norm。
Add就是残差网络中的inpit+output的结构【人工智能学习】【十五】残差网络
biˊ=ai+bi\acute{b^i}=a^i+b^ibiˊ=ai+bi
Norm就是正则化Layer Normalization,在【人工智能学习】【十四】批量归一化有介绍
在RNN中常用的是LN,这也许是这里使用LN的原因。
将Add and Norm的结果经过一个前馈神经网络进行变换,这里也用到了残差网络类似的结构。输出结果继续Add and Norm。
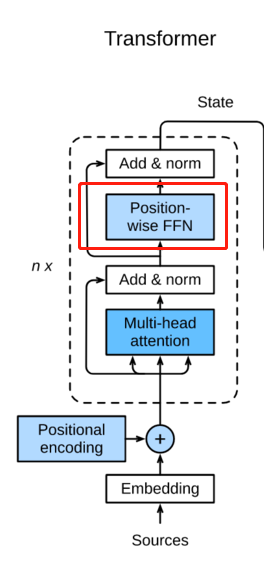
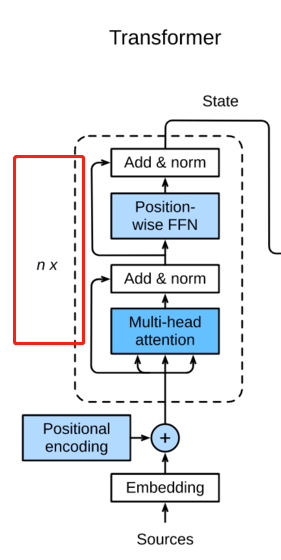
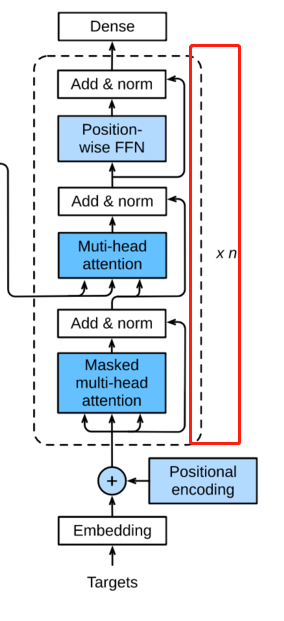
这里是个循环,意思是如上所有结构可以当做一个cell,放到RNN中进行循环计算attention
这部分和Encoder中一样,向量化和位置向量加和
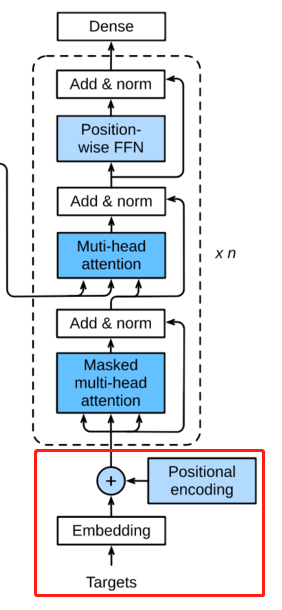
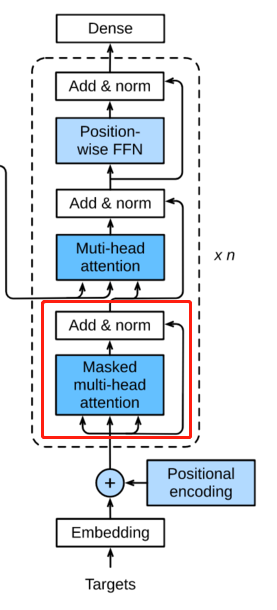
在做self-attention的时候,这个decoder只会attention到它已经产生的sequence,因为后面还没产生的sequence没法做attention,只会attention到已经产生的部分。这里的这个attention是decoder的attention。
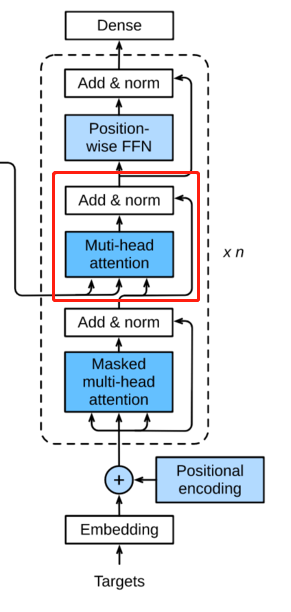
这里使用的是Encoder产生的attention,所以不是masked的了。同样做一个Add and Norm。
和Encoder一样
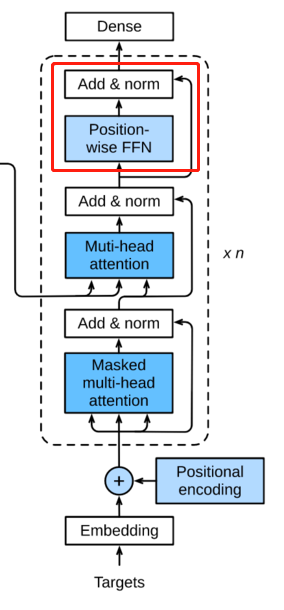
这里的循环可以是RNN网络
作者:番茄发烧了