【飞桨PaddlePaddle学习心得】day5(学习过程中遇到的坑的汇总)
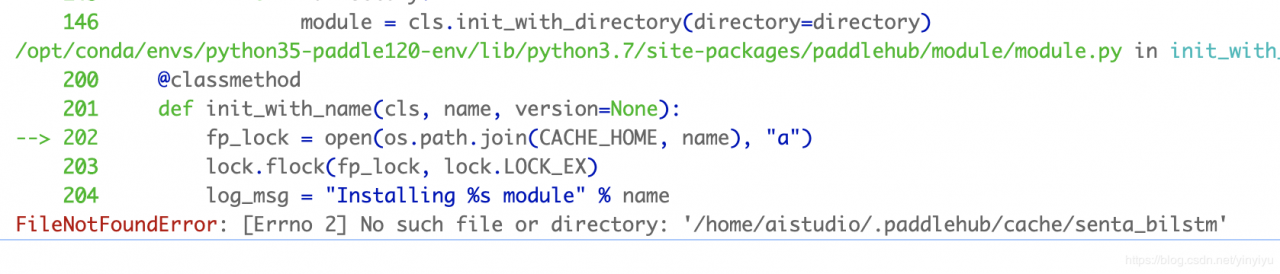
没有下载paddlehub 没有import paddlehub 没有使用hub命令下载senta_bilstm模型
模型下载命令:!hub install senta_bilstml==1.0.0
可以引伸出来 使用paddlehub,所有找不到模型额问题,都是paddle没有加载进来
坑2 matplotlib显示中文的问题
1.没有安装中文字体
2.安装了中文字体,但是没有复制到matplotlib下面
3.设置matplotlib.rcParams
4.for mac:安装好以后需要使用rm -r ~/.matplotlib 删除~/.matplotlib文件
解决方法
#下载中文字体
wget https://mydueros.cdn.bcebos.com/font/simhei.ttf
#在操作系统中创建字体目录fonts(可能已经有
mkdir .fonts
# 复制字体文件到该路径
cp simhei.ttf .fonts/
#复制字体到当前使用的conda环境中的matplotlib下的指定路径
cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
# Linux系统默认字体文件路径
ls /usr/share/fonts/
# 查看系统可用的ttf格式中文字体
fc-list :lang=zh | grep ".ttf"
# 设置显示中文
matplotlib.rcParams['font.family'] = ['SimHei']
# 解决负号'-'显示为方块的问题
matplotlib.rcParams['axes.unicode_minus'] = False
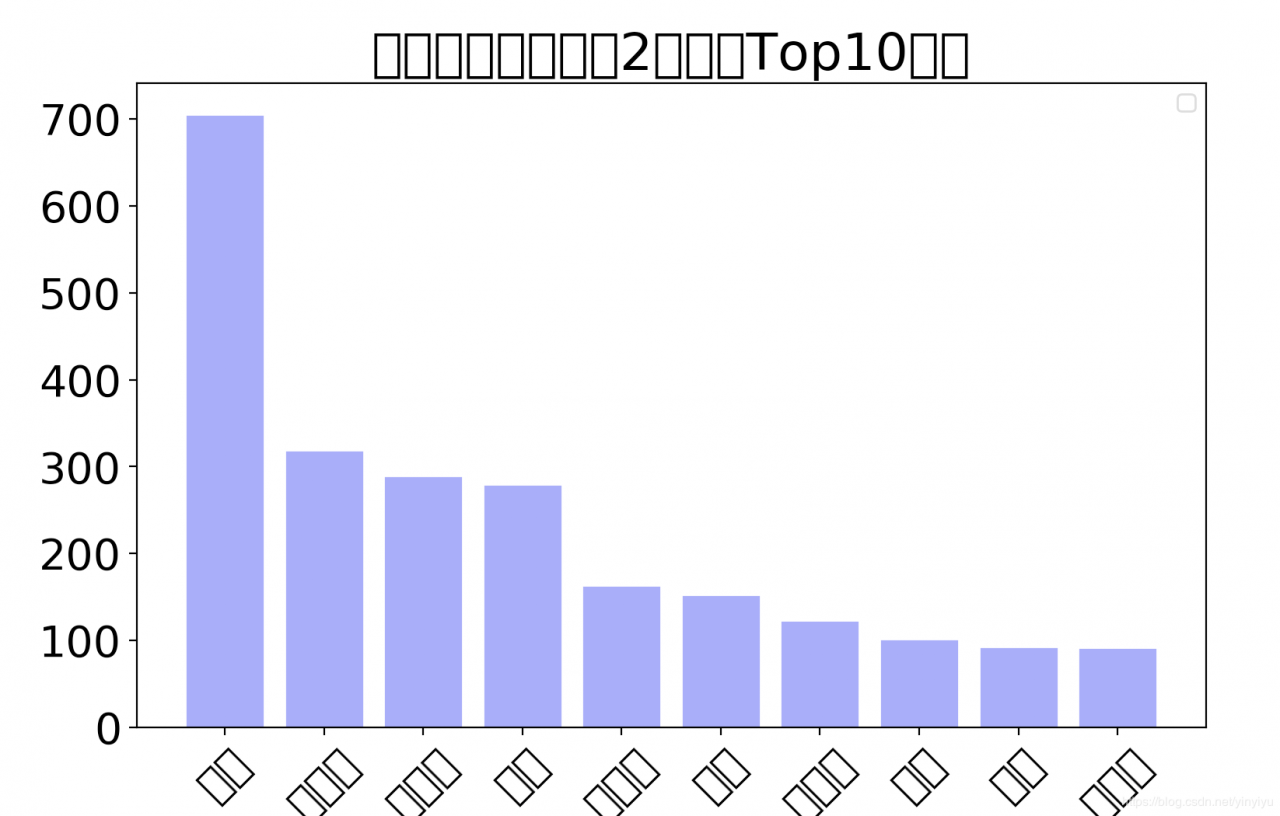
最终效果:
这一系列的问题都出现在使用paddlehub进行Finetune的时候 也就是在运行run_states = task.finetune_and_eval()这行代码的时候。
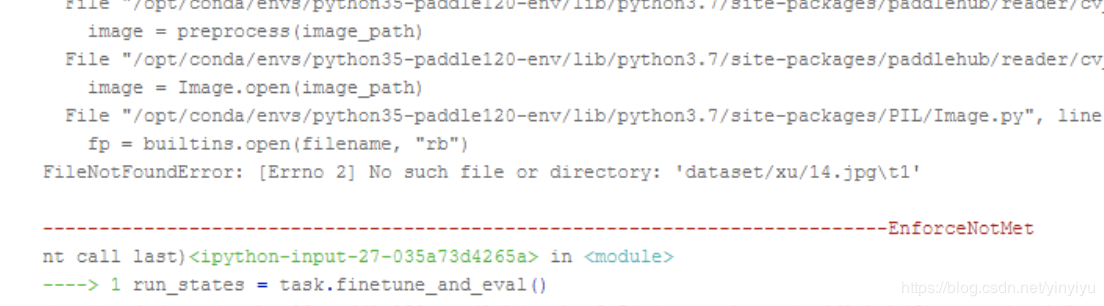
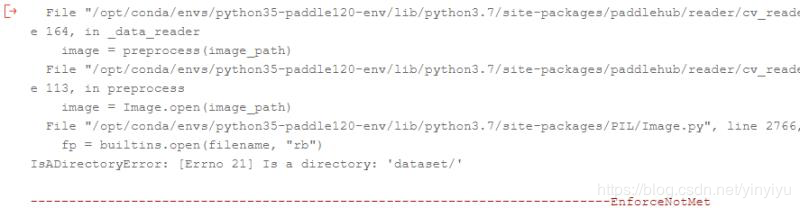

其实可以很容易知道,我们不能对模型做什么改动,只有在运行这一行代码的时候报错了,那么我们唯一和模型进行交互的是什么呢?是我们的数据集,所有肯定是我们的额数据集出现了问题呀。
归根到底,出现问题还是没有理解paddlehua的自定义数据集的规定。
from paddlehub.dataset.base_cv_dataset import BaseCVDataset
class DemoDataset(BaseCVDataset):
def __init__(self):
# 数据集存放位置
self.dataset_dir = "dataset"
super(DemoDataset, self).__init__(
base_path=self.dataset_dir,
train_list_file="train_list.txt",
validate_list_file="validate_list.txt",
test_list_file="test_list.txt",
label_list_file="label_list.txt", )
dataset = DemoDataset()
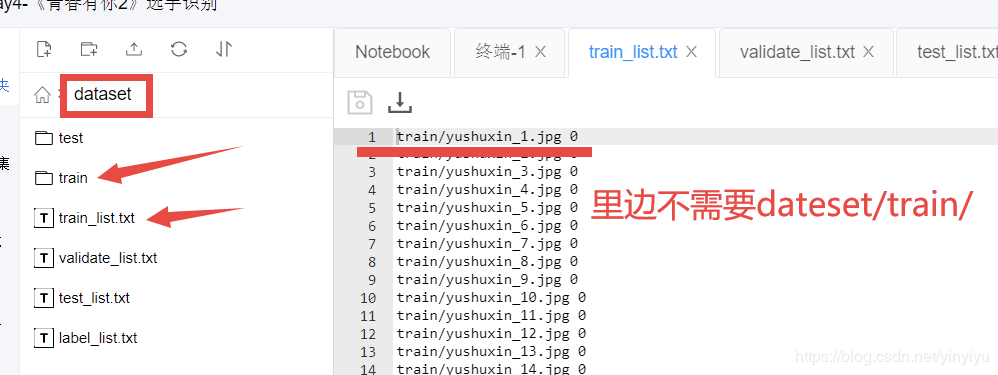
从这个DemoDataset可以看出,dataset_dir设定了所有的路径的root节点,相当于下面super里面的所有路径前面都要加入dataset/这个前缀。详细的要求可以查看适配自定义数据
然后就是train_list.txt、validate_list.txt和test_list.txt里面的内容了。
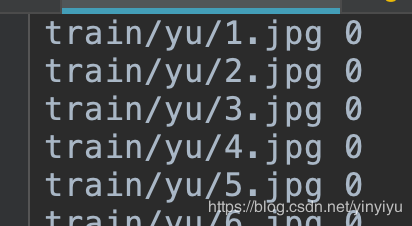
以上图(train_list.txt)里面的内容为例.分为两列:
第一列是训练数据的路径,这里也是最容易出错的,这里的路径默认前面是有了一个dataset的,也就是我们在前面代码里面设置的self.dataset_dir = “dataset”,很多问题都是出现在这里的,因为这里写错了,那么模型就加载不到图片,肯定会报错呀。
然后就是第二列的数据,中间以空格分割,第二列的数据与label_list.txt里面的内容形成索引。

以上是label_list.txt里面的内容,paddle在查询的时候,训练和测试文件的时候,会自动根据索引去label_list.txt中匹配label。
这个的坑在于,传入的数据必须是个字典,而且字典的key要为text,value必须要是个list。
senta = hub.Module(name='senta_bilstm', version='1.0.0')
input_dict = {'text':['你好呀!','ennenene']}
res = senta.sentiment_classify(data=input_dict)
坑5 大作业爬虫
本次大作业第一步就是爬取评论的数据,这个爬虫相对来说不要太容易了,唯一的槽点就是调用的接口找起来有点麻烦,在这里给出,结构的url如下,对于参数来说,只要注意content_id和last_id就行了,content_id代表的是那一步电影/电视(in iqiyi)。然后last_id的话主要是达到一个翻页的作业,只需要把本次查询到的最后一个评论的用户的id赋值给last_id就可以实现查询下一页的评论了。
接口链接和参数如下意思的话从参数名上面大部分就能看明白了
这两个函数会由于基本功的问题,容易搞混淆或者记不起怎么用。
当我们通过接口爬取到数据后,返回的通常都是json类型的字符串数据。这个时候我们就需要上面的两个函数来帮忙了,那么到底这两个函数怎么用呢。
通俗的讲:
json.loads(str(data):将一个JSON编码的字符串转换回一个Python数据结构(通常为字典
json.dump(json_data): 将一个Python数据结构转换为JSON字符串,通常在写文件的时候使用。
所有本次大作业,先拿到的就是json类型的字符串,我们要拿到里面的comments的话就要先把它转换为dict类型的数据,然后再访问:
lastId = ''
response = getComment(lastId) #getComment发送请求得到json类型的字符串
response = json.loads(response) #使用json.loads解析
comment_list = response['data']['comments'] #得到一次返回的所有comments的list
lastId = comment_list[-1]['id'] #得到lastID 然后再次使用getComment(lastId)
while len(comment_list) <1000:
getComment(lastId)
……
……
#当要持久化爬取到的json数据的时候 就要使用json.dump()
with open('day5.json', 'w', encoding='UTF-8') as f:
json.dump(comment_list, f, ensure_ascii=False)
2020.4.27 00:12 未完待续
作者:小诺~