详文带你使用PaddlePaddle实战房屋信息预测(入门级)
前言
参数1模型地址,参数2执行器(执行引擎)。返回的值是, 返回参数1:加载propram(之前描述的程序),参数2:所需要提供的变量名称,参数3:所有输出变量。
最近在学习百度PaddlePaddle飞浆深度学习框架,做的第一个例子就是房屋价格预测。尽管官方在实例代码中做了些讲解,但是仍然有很多没有照顾到的地方。下面,我将通过这个例子,带大家掌握这个模型。

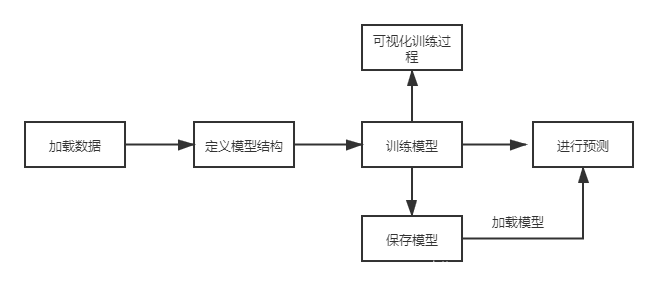
模型:
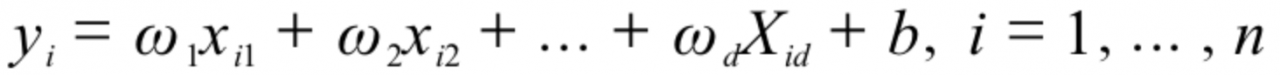
#每次缓存500个数据
BUF_SIZE=500
#每20个组成一个训练批次
BATCH_SIZE=20
#一次缓存500个数据,其中每次读取20个
#读取数据到缓存中,并且打乱数据。
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.uci_housing.train(),buf_size=BUF_SIZE),
batch_size=BATCH_SIZE
)
test_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.uci_housing.test(),buf_size=BUF_SIZE),
batch_size=BATCH_SIZE
)
代码解析:
paddle.reader.shuffle(reader,buf_size)作用:将reader中的数据读取到缓冲区,读取数据个数是buf_size。 paddle.batch(data,batch_size) 数据打包器,将shuffle方法读取的数据按照batch_size大小,进行打包。上述例子中,共有404个训练数据,batch_size=20,共可分得21份(404/20)。 定义模型结构#定义输入输出变量
x = fluid.layers.data(name='x',shape=[13],dtype='float32')
y = fluid.layers.data(name='y',shape=[1],dtype='float32')
y_predict = fluid.layers.fc(input=x,size=1,act=None)#全连接层。
#定义损失值计算方式,这里使用的是平方差损失函数
cost = fluid.layers.square_error_cost(input=y,label=y_predict)
avg_cost = fluid.layers.mean(cost)
#定义优化器,这里使用随机梯度下降优化器
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01)
opts = optimizer.minimize(avg_cost)
#克隆上述过程。
test_program = fluid.default_main_program().clone(for_test=True)
#创建CPU解释器
place = fluid.CPUPlace()
exe = fluid.Executor(place)#创建执行器
#初始化参数
exe.run(fluid.default_startup_program())
#向模型输入变量,转化成一种特殊的数据结构,可以输入到Executor
feeder = fluid.DataFeeder(place=place,feed_list=[x,y])
代码解析:
fluid.layers.data(name,shape,dtype)创建一个全局变量,也可以理解为一个占位符,在训练模型得时候通过name进行数据赋值。shape是变量得形状,dtype是该变量得数据类型。 fluid.layers.fc(input,size,act)神经网络中的全连接层,在此例子中也是作为预测结果得输出。size是改连接层大小,act是用于输出得激活函数。由于我们最终需要预测的是房价,所以这里size值为1. fluid.layers.square_error_cost(input,label)预测值和准确值的方差估计,作为计算误差的一种方式。Out=(input−label)² fluid.layers.mean(data) paddlepaddle框架自带的取平均值函数,返回值是data数据的平均值,这里用来计算每一批数据训练所得误差的平均值。 fluid.optimizer.SGDOptimizer(learning_rate)随机梯度下降优化器,参数是学习率。 optimizer.minimize()为网络添加反向计算过程,并根据反向计算所得的梯度,最小化网络损失值loss。也就是更新模型中的W权值。 fluid.default_main_program().clone(for_test=True)paddle框架采取类似于流程图的形式。program会记录用户定义的操作。这里将用户操作进行赋值,用于之后测试。 fluid.CPUPlace()指定一个解释器,我这里指定的是CPU,当然也可以指定GPU。 fluid.Executor(place)创建执行器,这个执行器用于执行program。 exe.run(fluid.default_startup_program())执行program。 fluid.DataFeeder()向模型输入变量,转化成一种特殊的数据结构,可以输入到Executor。 训练过程可视化
def draw_train_process(iters,train_costs):
title="training cost"
plt.title(title,fontsize=24)
plt.xlabel("iter",fontsize=14)
plt.ylabel("cost",fontsize=14)
plt.plot(iters,train_costs,color='red',label='training cost')
plt.grid()
plt.show()
代码解析:
这里定义一个方法,参数分别是迭代次数和误差值。这里具体涉及到matplotlib的知识,大家可以参考 matplotlib画图教程系列之-折线图 训练模型EPOCH_NUM = 30
for pass_id in range(EPOCH_NUM):#遍历数,也就是训练次数
trian_cost=0
for batch_id,data in enumerate(train_reader()):
train_cost = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),#喂数据#这里对比之前的例子feed={'x':x,'y':y}
fetch_list=[avg_cost])#输出
if batch_id % 40 ==0:#这里只是batch_id==0时才触发。
print("Pass:%d,Cost:%0.5f" %(pass_id,train_cost[0][0]))
iter = iter+BATCH_SIZE#记录训练次数,用作画图
iters.append(iter)
train_costs.append(train_cost[0][0])#将损失值保存下来,用于画图
test_cost = 0
for batch_id,data in enumerate(test_reader()):
test_cost = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost])
print('Test:%d,Cost:%0.5f' % (pass_id,test_cost[0][0]))
代码解析:
EPOCH_NUM 定义训练轮次。 enumerate(train_reader())从之前获取的数据集中,将键和值分别的遍历出来。为何这里使用train_reader()而不是train_reader,请看这篇文章:今天终于弄明白了python迭代器是什么 exe.run(program,feed,fetch_list)program 这里使用的是default_main_program(),这个program存储着变量和算子。feed是用来传入参数。这里使用的是feeder.feed(data)传入数据。目的是将数据转化为一种特殊的结构。fetch_list填入要输出的值。 保存模型mode_save_dir="model/house_bosdun.model"
if not os.path.exists(mode_save_dir):#路径不存在创建路径
os.makedirs(mode_save_dir)
print('save models to %s '% (mode_save_dir))
fluid.io.save_inference_model(mode_save_dir,
['x'],
[y_predict],
exe)
代码详情:
save_inference_model(dirname,feeded_var_names,target_vars, executor,)第一个参数是保存地址,第二个参数是所有输入变量的名字,第三个参数是包含所有输出变量的名字,第四个是用于保存预测模型的执行器 模型导入infer_exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
with fluid.scope_guard(inference_scope):#切换作用域
[inference_program,
feed_target_names,
fetch_targets] = fluid.io.load_inference_model(mode_save_dir,infer_exe)#参数1地址,参数2执行器(执行引擎)
infer_reader = paddle.batch(paddle.dataset.uci_housing.test(),batch_size=200)
代码详情:
with fluid.scope_guard(inference_scope) 切换作用域,这里切换作用域的原因:防止创建的变量污染全局。说白了,就是为了使变量为局部变量。 fluid.io.load_inference_model(mode_save_dir,infer_exe)参数1模型地址,参数2执行器(执行引擎)。返回的值是, 返回参数1:加载propram(之前描述的程序),参数2:所需要提供的变量名称,参数3:所有输出变量。
完整的代码我就不放了,与官方的基本一致。这里主要是更加详细解释一下一些方法的用法。觉得对你有帮助的话,点个