计算机视觉3—SIFT算法理解及实现
目录
一、SIFT介绍
二、SIFT特点
三、尺度空间
四、高斯金字塔
五、DOG空间极值检测
六、关键点方向分配、描述和匹配
1.关键点方向分配
2.关键点描述
3.关键点匹配
七、SIFT实现与分析
1.SIFT特征检测
1.1算法步骤
1.2算法实现
2.SIFT特征匹配
2.1算法步骤
2.2算法实现
3.数据集内检索匹配
八、总结
九、错误
一、SIFT介绍SIFT,即尺度不变特征变换(Scale-invariant feature transform,SIFT),是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。SIFT特征是基于物体上的一些局部外观的兴趣点而与影像的大小和旋转无关。对于光线、噪声、微视角改变的容忍度也相当高。基于这些特性,它们是高度显著而且相对容易撷取,在母数庞大的特征数据库中,很容易辨识物体而且鲜有误认。
二、SIFT特点1.SIFT特征是图像的局部特征,其对旋转、尺度缩放、亮度变化保持不变性,对视角变化、仿射变换、噪声也保持一定程度的稳定性;
2. 区分性好,信息量丰富,适用于在海量特征数据库中进行快速、准确的匹配;
3. 多量性,即使少数的几个物体也可以产生大量的SIFT特征向量;
4.高速性,经优化的SIFT匹配算法甚至可以达到实时的要求;
5.可扩展性,可以很方便的与其他形式的特征向量进行联合。
三、尺度空间在一定的范围内,无论物体是大还是小,人眼都可以分辨出来。然而计算机要有相同的能力却不是那么的容易,在未知的场景中,计算机视觉并不能提供物体的尺度大小,其中的一种方法是把物体不同尺度下的图像都提供给机器,让机器能够对物体在不同的尺度下有一个统一的认知。在建立统一认知的过程中,要考虑的就是在图像在不同的尺度下都存在的特征点。
而尺度空间的基本思想是:在图像信息处理模型中引入一个被视为尺度的参数,通过连续变化尺度参数获得多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓的提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测和不同分辨率上的特征提取等。
尺度空间中各尺度图像的模糊程度逐渐变大,能够模拟人在距离目标由近到远时目标在视网膜上的形成过程。要使得图像具有尺度空间不变形,就要建立尺度空间。
一个图像的尺度空间,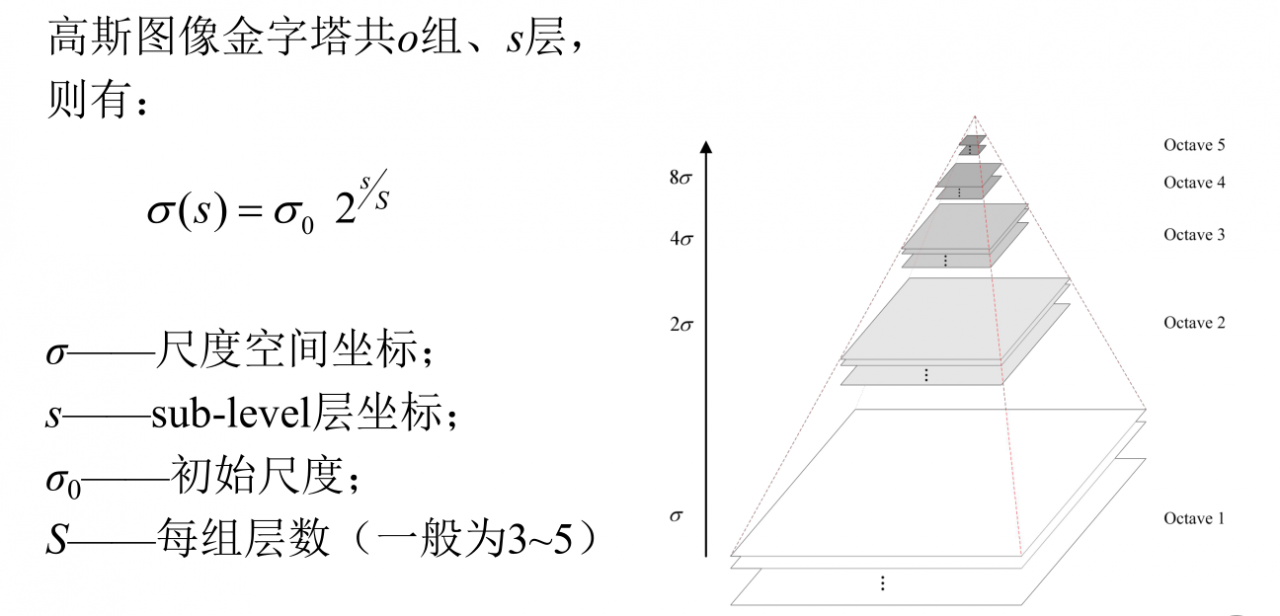
1、DOG函数
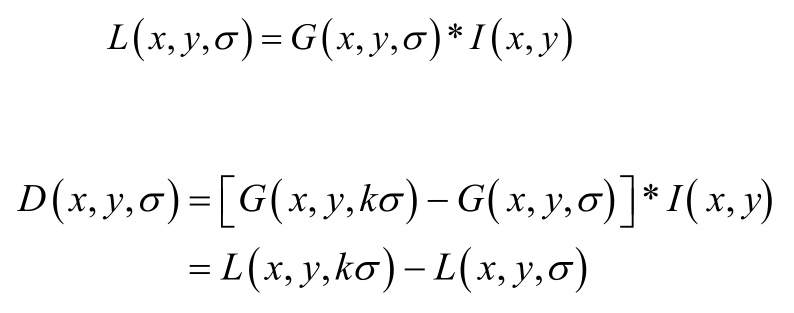
2、DoG高斯差分金字塔
(1)对应DOG算子,构建DOG金字塔。
可通过高斯差分图像看出图像上的像素值变化情况,DOG图像描绘的是目标的轮廓。
(2)DOG局部极值检测
特征点是由DOG空间的局部极值点组成的。为了寻找DoG函数的极值点,每一个像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小,特征点是由DOG空间的局部极值点组成的。
(3)去除边缘效应
在边缘梯度的方向上主曲率值比较大,而沿着边缘方向则主曲率值较小。
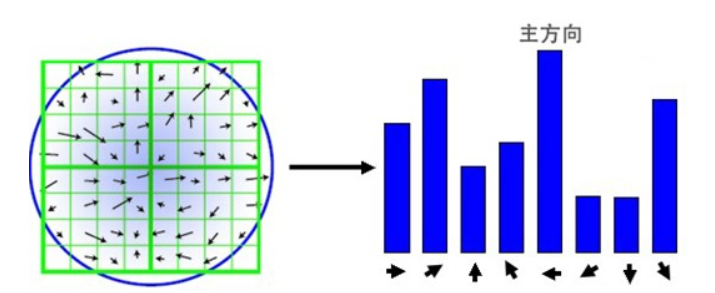
六、关键点方向分配、描述和匹配 1.关键点方向分配为了使描述符具有旋转不变性,需要利用图像的局部特征为给每一个关键点分配一个方向。通过尺度不变性求极值点,可以使其具有缩放不变的性质。而利用关键点邻域像素的梯度方向分布特性,可以为每个关键点指定方向参数方向,从而使描述子对图像旋转具有不变性。
通过求每个极值点的梯度来为极值点赋予方向,完成关键点的梯度计算后,使用直方图统计邻域内像素的梯度和方向。确定关键点的方向采用梯度直方图统计法,统计以关键点为原点,一定区域内的图像像素点对关键点方向生成所作的贡献。
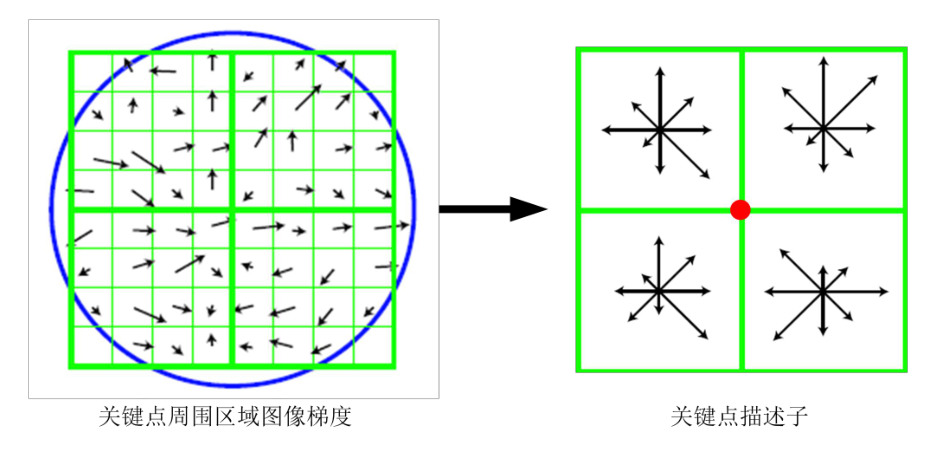
经过一系列步骤此时对于每一个关键点都拥有三个信息:位置、尺度以及方向。然后就是为每个关键点建立一个描述符,用一组向量将这个关键点描述出来,使其不随各种变化而改变,比如光照和视角等变化。这个描述子不但包括关键点,也包含关键点周围对其有贡献的像素点,并且描述符应该有较高的独特性,以便于提高特征点正确匹配的概率。
SIFT描述子是关键点邻域高斯图像梯度统计结果的一种表示。通过对关键点周围图像区域分块,计算块内梯度直方图,生成具有独特性的向量,这个向量对该区域图像信息的表达具有唯一性。
Lowe实验结果表明:描述子采用4×4×8=128维向量表征,综合效果最优(不变性与独特性)。
(1)分别对模板图(参考图,reference image)和实时图(观测图,observation image)建立关键点描述子集合。目标的识别是通过两点集内关键点描述子的比对来完成。具有128维的关键点描述子的相似性度量采用欧式距离。
(2)关键点的匹配可以采用穷举法来完成,但是这样耗费的时间太多,一般都采用kd树的数据结构来完成搜索。搜索的内容是以目标图像的关键点为基准,搜索与目标图像的特征点最邻近的原图像特征点和次邻近的原图像特征点。
(1)尺度空间极值检测:搜索所有尺度上的图像位置。通过高斯微分函数来识别潜在的对于尺度和旋转不变的兴趣点。
(2)关键点定位:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。
(3)方向确定:基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
(4)关键点描述:在每个关键点周围的邻域内,在选定的尺度上测量图像局部的梯度。这些梯度被变换成一种表示,这种表示允许比较大的局部形状的变形和光照变化。
1.2算法实现SIFT特征提取算法先以转换为灰度图的方式读取一张图片并转化为图像数组,引用sift.py中的process_image将图像文件转化为pgm格式。
# -*- coding: utf-8 -*-
from PIL import Image
from pylab import *
from PCV.localdescriptors import sift
from PCV.localdescriptors import harris
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
imname = 'data/pic1/2.jpg'
# 以灰度图的方式读入图片
im = array(Image.open(imname).convert('L'))
# 引用sift.py中的process_image将图像文件转化为pgm格式
sift.process_image(imname, '2.sift')
# l1为兴趣点坐标、尺度和方位角度 l2是对应描述符的128 维向
l1, d1 = sift.read_features_from_file('2.sift')
figure()
gray()
sift.plot_features(im, l1, circle=False)
title(u'SIFT特征',fontproperties=font)
需要的图像格式为灰度 .pgm,转换为 .pgm 格式文件代码如下,转换的结果以易读的格式保存在文本文件中。
def process_image(imagename,resultname,params="--edge-thresh 10 --peak-thresh 5"):
""" 处理一幅图像,然后将结果保存在文件中 """
if imagename[-3:] != 'pgm':
# 创建一个 pgm 文件
im = Image.open(imagename).convert('L')
im.save('tmp.pgm')
imagename = 'tmp.pgm'
cmmd = str("sift "+imagename+" --output="+resultname+
" "+params)
os.system(cmmd)
print 'processed', imagename, 'to', resultname
文本文件的数据的每一行前 4 个数值依次表示兴趣点的坐标、尺度和方向角度,然后是对应描述符的 128 维向量。这里的描述子使用原始整数数值表示,没有经过归一化处理,内容如下:
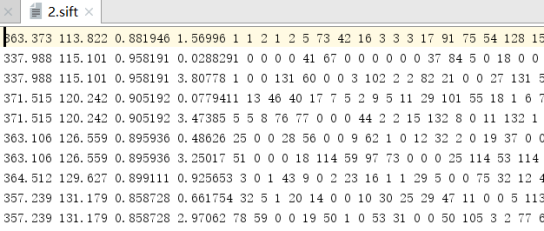
read_features_from_file将特征读取到 NumPy 数组中,如下示:
def read_features_from_file(filename):
""" 读取特征属性值,然后将其以矩阵的形式返回 """
f = loadtxt(filename)
return f[:,:4],f[:,4:] # 特征位置,描述子
原始数据集(共15张图片)展示如下:

实现数据集中每张图片的SIFT特征提取,并展示特征点如下:

对数据集中某些图片的SIFT特征提取,并用圆圈表示SIFT特征尺度,结果如下:
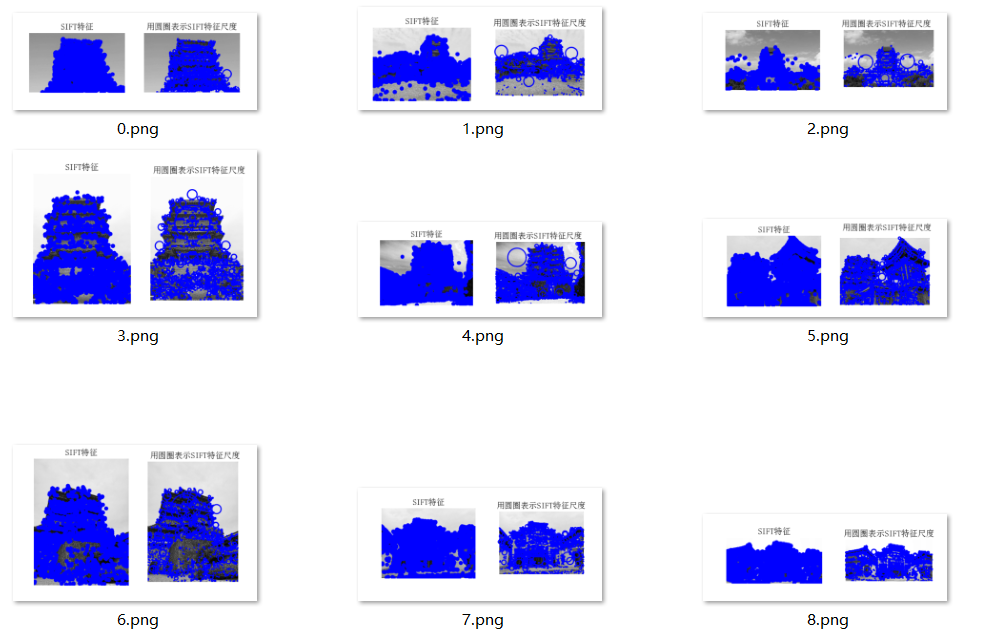
小结:用圆点和圆圈的特征点识别对比可以发现,圆点的效果会更好一点,圆圈对于一些特征点并不能检测出来。
2.SIFT特征匹配
2.1算法步骤
SIFT特征匹配主要包括2个阶段:
(1)SIFT特征的生成,即从多幅图像中提取对尺度缩放、旋转、亮度变化无关的特征向量。
1. 构建尺度空间,检测极值点,获得尺度不变性。
2. 特征点过滤并进行精确定位。
3. 为特征点分配方向值。
4. 生成特征描述子。
(2)SIFT特征向量的匹配。
2.2算法实现
SIFT特征提取给定两张图片,计算其SIFT特征匹配结果,算法如下示:
# -*- coding: utf-8 -*-
from PIL import Image
from pylab import *
import sys
from PCV.localdescriptors import sift
if len(sys.argv) >= 3:
im1f, im2f = sys.argv[1], sys.argv[2]
else:
im1f = 'data/pic1/9.jpg'
im2f = 'data/pic1/10.jpg'
im1 = array(Image.open(im1f))
im2 = array(Image.open(im2f))
sift.process_image(im1f, 'out_sift_9.txt')
l1, d1 = sift.read_features_from_file('out_sift_9.txt')
figure()
gray()
subplot(121)
sift.plot_features(im1, l1, circle=False)
sift.process_image(im2f, 'out_sift_10.txt')
l2, d2 = sift.read_features_from_file('out_sift_10.txt')
subplot(122)
sift.plot_features(im2, l2, circle=False)
matches = sift.match_twosided(d1, d2)
print '{} matches'.format(len(matches.nonzero()[0]))
figure()
gray()
sift.plot_matches(im1, im2, l1, l2, matches, show_below=True)
show()
两张图的匹配度为676个匹配点,匹配结果:
processed tmp.pgm to out_sift_9.txt
processed tmp.pgm to out_sift_10.txt
676 matches

3.数据集内检索匹配
给定一张输入的图片,在数据集内部进行检索,输出与其匹配最多的三张图片,算法代码如下:
# -*- coding: utf-8 -*-
from PIL import Image
from pylab import *
from PCV.localdescriptors import sift
import os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
counts1 = []
counts2 = []
# 输入图片
im1f = 'data/pic1/2.jpg'
im1 = array(Image.open(im1f))
sift.process_image(im1f, 'out_sift_2.txt')
l1, d1 = sift.read_features_from_file('out_sift_2.txt')
# 数据集图片,一一比对
path = "data\\pic1\\"
filelist = os.listdir(path)
total_num = len(filelist)
for i in range(total_num):
im2f = path + str(i) + '.jpg'
im2 = array(Image.open(im2f))
sift.process_image(im2f, 'out_sift.txt')
l2, d2 = sift.read_features_from_file('out_sift.txt')
matches = sift.match_twosided(d1, d2)
counts1.append(len(matches.nonzero()[0]))
counts2.append(len(matches.nonzero()[0]))
# 打印匹配结果
print counts1
counts2.sort(reverse=True)
# 打印降序排列结果
print counts2
# 匹配度前三个图片的展示,如要展示多个图片,可以直接写个循环
# 这里为了方便将所有图片显示在同一个平面上就直接是一个个显示了
img0 = mpimg.imread(im1f)
plt.subplot(2, 3, 2)
plt.imshow(img0)
plt.axis('off')
img1 = mpimg.imread(path + str(counts1.index(counts2[0])) + '.jpg')
plt.subplot(2, 3, 4)
plt.imshow(img1)
plt.axis('off')
img2 = mpimg.imread(path + str(counts1.index(counts2[1])) + '.jpg')
plt.subplot(2, 3, 5)
plt.imshow(img2)
plt.axis('off')
img3 = mpimg.imread(path + str(counts1.index(counts2[2])) + '.jpg')
plt.subplot(2, 3, 6)
plt.imshow(img3)
plt.axis('off')
plt.show()
输入图片与数据集内各图片一一匹配,并将结果存入数组counts1和counts2(ps:counts1和counts2是一样的,存放的都是匹配结果,这里用了两个counts是为了下面做降序排序的结果区分开来)中:
[5, 8, 1, 57, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0]
将counts2也即上述数据进行降序排序,此时counts1中的数据仍为上述数据,而counts2则为下述降序数据,如下示:
[57, 8, 5, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0]
然后 利用counts1.index(counts2[i])按序索引寻找原始数据所在位置,即为获得该数据对应图片序号名称,把图片显示出来。
最上面的是原图(即输入要匹配的图片),下面三个依次为数据集里匹配度最高的三幅图片,分别是匹配点为57,8,5,结果展示如下:

小结:SIFT在图像的不变特征提取方面拥有一定的优势,但是对模糊的图像检测出的特征点过少,还有就是对角度差别较大的同一图像检测出的特征点过少。
八、总结
1.此次试验利用SIFT算法实现了对图片的特征提取及图片的特征匹配, SIFT的不变特征提取相对于harris算法来说是具有一定优势的,我选取的图片是一组建筑物,通过输入图片与数据集中图片两两进行特征匹配的结果来说,精确度还是很高的,由此说明SIFT特征对旋转、尺度缩放、亮度变化等保持不变的特性性是一种非常稳定的局部特征。
2.SIFT小结
DoG尺度空间的极值检测。 首先是构造DoG尺度空间,在SIFT中使用不同参数的高斯模糊来表示不同的尺度空间。
删除不稳定的极值点。即低对比度的极值点以及不稳定的边缘响应点。
特征点的定位及确定特征点的主方向。
生成特征点的描述子进行关键点匹配。
九、错误
代码一开始运行的时候出现了 IOError:empire.sift not found ,就是empire.sift无法生成。

百度说是vlfeat的版本问题,因为我用的是最新的版本0.9.21-bin.tar.gz,要vlfeat-0.9.20-bin.tar.gz版本的才行VLFeat官网 ,vifeat安装可参考教程,但是又出现一个新错误 IndexError:too many indices for array 。

解决方法:把sift.exe,vl.dll和vl.lib三个复制到你现在所做的项目目录下就可以。
总结步骤:
1.首先从官网下载vlfeat-0.9.20-bin.tar.gz安装包,解压后找到bin文件夹里的win64文件夹,将整个文件夹拷贝放到电脑中的某个目录下,建议和之前下载的PCV放到一起(ps:我是都放在python目录下,还将win64更名为win64VLfeat)。
2.进入PCV文件夹里的localdescriptors找到sift.py文件,并打开将cmmd中的目录修改为刚才放置VLfeat文件中sift.exe的路径即可
需要注意的是,如果python版本在3.0以上的需要在print后面加括号。
2.把vlfeat文件夹bin下win64中的sift.exe和vl.dll这两个文件复制到项目的文件夹中。
作者:w.wyue