计算机视觉之人脸学习(五)
一.TensorFlow基础介绍
(一)TensorFlow中的基础概念介绍
1.什么是TensorFlow:Google开源的基于数据流图的科学计算库,适合用于机器学习,深度学习等人工智能领域,tensorflow的源码:
https://github.com/tensorflow
https://gitub.com/tensorflow/models
Tensor:张量(数据)
Flow:计算流(数据流向)
TensorFlow架构:(1)前端:编程模型,构造计算图,Python,C++,Java (2)后端:运行计算图,C++
2.为什么选择TensorFlow:高度的灵活性/真正的可移植性/将科研和产品联系在一起/自动求微分/多语言支持/性能最优化/社区内容丰富
3.Graph:图描述了计算的过程,可以通过tensorboard图形化流程结构,下面是一个图形化的结果:包括了相应的数据和运算,箭头表示数据的流向,这里的计算图就是我们所谓的网络。
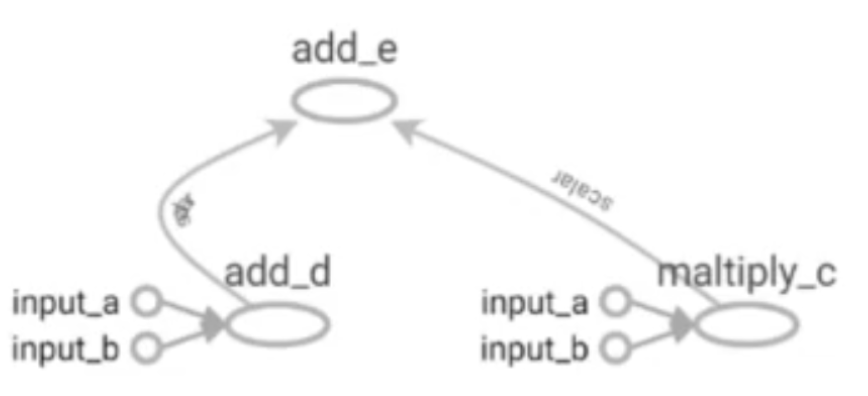
对于这样的一个计算图,包括以下操作:
(1)声明(单个图/多个图)
单个图代码:
import tensorflow as tf
g=tf.Graph()#声明一个Graph
g=tf.get_default_graph()#获取当前默认的graph
x=tf.constant(0)
g=x.graph#通过变量也可以获取当前的graph
多个图代码:
g1 = tf.Graph()
with g1.as_default():
x1 = tf.constant(1.0, name="x1")#利用with 来声明当前的变量所对应的Graph
g2 = tf.Gragh()
with g2.as_default():
x2 = tf.contant(2.0,name="x2")
with tf.Session(graph=g2) as sess1:#我们在定义Session时,也可以将Graph指代相应的图,这时session则作用在当前graph下
x1_list = tf.import_graph_def(g1.as_graph_def(),return_elements =["x1:0",name='')
print(sess1.run(x1_list[0]+x2))
(2)保存为pb文件(我们网络训练好之后,我们会进行保存)
g1 = tf.Graph()
tf.train.write_graph(g1.as_graph_def(),'.','graph.pb',False)#这时我们就可以对当前的网络的参数和结构进行保存
(3)从pb中恢复Graph
with gfile.FastGFile("graph.pb",'rb')as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
tf.import_graph_def(graph_def, name='')
sess = tf.Session()
c1_tensor = sess.graph.get_tensor_by_name("c1:0")#节点的获取
c1 = sess.run(c1_tensor)#计算当前节点的值
(4)Tensorboard可视化
import tensorflow as tf
a=tf.contant(1,name='input_a')
b=tf.contant(2,name='input_b')#所有的变量都是tensor
c=tf.multiply(a,b,name='maltiply_c')
d=tf.add(a,b,name='add_d)
e=tf.add(d,c,name='add_e')
sess=tf.Session()
sess.run(e)#获取e节点所对应的值
writer=tf.summary.FileWriter('graph',sess.graph)#将graph添加到日志模块中
4.Session:图必须在称之为“会话"的上下文中执行,会话将图的操作分发到诸如CPU或GPU之类的设备上执行。完成了前端和后端的沟通,包括的操作:
(1)创建关闭
sess =tf.Session()
sess=tf.InteractiveSession()
with tf.Session()as Sess:
...(完成数据的注入,计算图在后端的执行)
sess.close
(2)注入机制(具体完成计算图运算的过程)
sess.run(...)#在run中指定需要指定计算的节点
sess.run(tf.global_variable_initializer())#获取当前计算图中全部的变量,然后run完成变量的初始化
a=tf.placeholder(dtype=tf.float32)
b=tf.placeholder(dtype=tf.float32)#a,b两个占位符
add =a+b
add_val=sess.run(add,feed_dict={a:1,b:2})#对a,b进行赋值,run对add进行计算
(3)指定设备
a = tf.placeholder(dtype=tf.float32)
b = tf.placeholder(dtype=tf.float32)
add = a+b#定义一个计算图
with tf.Session() as sess:
with tf.device("/cpu:0):
print(sess.run(add,feed_dict={a:1,b:2}))
(4)资源分配(控制GPU资源使用率)
config =tf.ConfigProto()
config.gpu_option.allow_growth =True
sesstion = tf.Session(config=config,...)#按需分配,可以知道当前网络的一个batchsize所占用的资源是多少,就可以清楚的设置batchsize的上限。
5.Tensor:在TensorFlow中,所有在节点之间传递的数据都为Tensor对象,N维数组,图像:(batch*height*width*channel)
定义方式:tf.constant(value,dtype,shape,name.verify_shape)#常量;tf.Variable(shape,dtype,name)#变量;tf.placeholder(dtype,shape,name)#占位符;tf.SparseTensor()#稀疏的张量
6.Operation:TensorFlow Graph中计算节点,输入输出均为Tensor,调用Session.run(tensor)或者tensor.eval()方可获取该Tensor的值
7.Feed:通过feed为计算图注入值,占位符的值
8.Fech:使用Fech获取计算结果。
tf.Session.run(fetches,feed_dict=None)#feches可以是一个tensor,也可以是list
(二)TensorFlow中的核心API
1.基本运算
.tf.expand_dims(inputs,dim,name=None)#维度的扩展
.tf.split(splt_dim,num_split,value,name='split')#维度的切分
.tf.concat(concat_dim,values,name='concat')#数据的拼接
.tf.cast()#数据类型的转化
.tf.reshape()#对数据形状的变化
.tf.equal()#判断是不是相等
.tf.matmul(a,b)#乘法
.tf.argmax()#最大值所对应的索引值
.tf.squeeze()#去掉向量中维度为1的相应的坐标轴
(1)tf.nn库:
.tf.nn.conv2d(卷积层)
.tf.nn.max_pool
.tf.nn.avg_pool(池化层)
.tf.nn.relu(激活层)
.tf.nn.dropout
.tf.nn.I2_normalize(归一化层)
.tf.nn.batch_normalization
.tf.nn.I2_loss
tf.nn.softmax_cross_entropy_with_logits(交叉熵)
(2)tf.train库:
.tf.train.Saver.save(模型的存储)
.tf.train.Saver.restore(模型的恢复)
.tf.train.GradientDescentOptimizer(0.01).minimize(loss)(模型的优化)
.tf.train.exponential_decay(1e-2.global_steps=sample_size/batch,decay_rate=0.98,staircase=True)(模型的学习率)
(3)TensorFlow中的数据操作
.TensorFlow提供了TFRecord的格式来统一存储数据,TFRecord将图像数据和标签放在一起的二进制文件,能更好的利用内存,实现快速的复制,移动,读取,存储
.数据读取:tf.train.string_input_producer,tf.train.slice_input_producer
.数据解析:tf.TFRecordReader,tf.parse_single_example
.数据写入:tf.python_io.TFRecordWriter
.数据写入相关的API方法:
.write=tf.python_io.TFRecordWriter()
.example=tf.train.Example()#会存储具体的数据,可以定义一个feature
.writer.close()
writer.writer(example.SerializeToString())#将数据序列化后写入TFRecord文件中
实战:下面以cifar10为例,介绍如何使用tensorflow对图像进行数据读取和数据打包
编程环境:Ubuntu18.04,pycharm,tf1.13.1,cuda10.0,cudnn7.4.1(花了好几天安装了双系统,配好环境,呕心沥血呀)
在pycharm中创建工程:tf-rend-write
1.下载数据集:
方法一:可以到cifar10官网下载CIFAR-10 python version,另外官网上也提供了如何解析当前打包后的数据程序:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
方法二:用程序直接在项目里下载(在工程下新建文件data装数据集)
import urllib.request as ur
import os
import sys
import tarfile
def download_and_uncompress_tarball(tarball_url, dataset_dir):
"""Downloads the `tarball_url` and uncompresses it locally.
Args:
tarball_url: The URL of a tarball file.
dataset_dir: The directory where the temporary files are stored.
"""
filename = tarball_url.split('/')[-1]
filepath = os.path.join(dataset_dir, filename)
def _progress(count, block_size, total_size):
sys.stdout.write('\r>> Downloading %s %.1f%%' % (
filename, float(count * block_size) / float(total_size) * 100.0))
sys.stdout.flush()
filepath, _ = ur.urlretrieve(tarball_url, filepath, _progress)#直接将远程数据下载到本地。
print()
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
tarfile.open(filepath, 'r:gz').extractall(dataset_dir)#指定解压路径和解压方式为解压gzip
DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz'#数据下载的URL
DATA_DIR = 'data'#存储的文件夹路径
download_and_uncompress_tarball(DATA_URL, DATA_DIR)
解析:
(1)urlretrieve的使用
直接将远程数据下载到本地。
urllib.urlretrieve(url, filename, reporthook, data)
参数说明:
url:外部或者本地url(这里是DATA_URL)
filename:指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据)(这里是DATA_DIR)
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调。我们可以利用这个回调函数来显示当前的下载进度(这里是_progress)
data:指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
(2)os.stat() 方法
用于在给定的路径上执行一个系统 stat 的调用。
os.stat(path)
path -- 指定路径
返回值
stat 结构:
st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。
下载好的数据集如图:
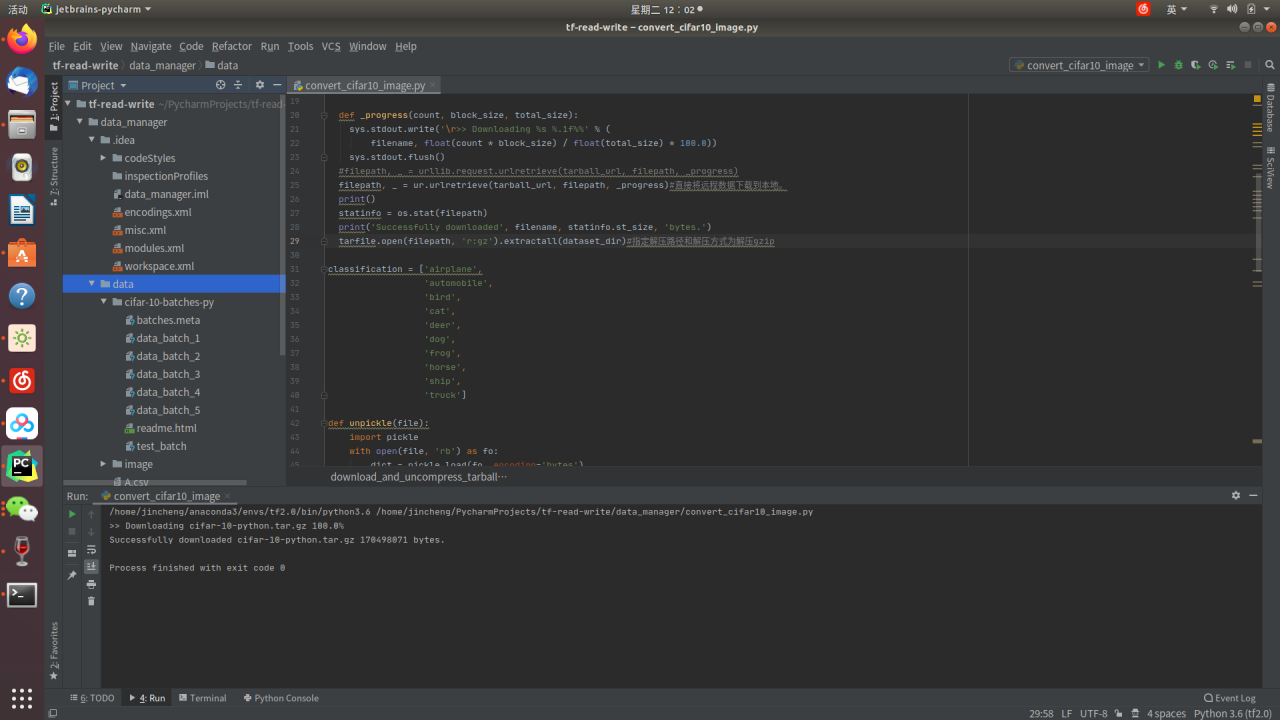
我们发现数据集是以二进制文件格式存储的,接下来我们会对二进制文件进行解析成具体图片,并存到image文件夹下的train和test文件夹里。以data_batch开头的为我们训练集,test_batch为我们测试集。
2.下面我们来解析二进制文件,首先将我们cifar10的10个分类存放在classfication这个变量中,在将官网的解析文件的脚本拷贝过来。
classification = ['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
我们可以发现这里的数据是以字典的形式进行存储的,字典的键值分别是data和label
先定义二进制文件的路径:
folders = '/home/jincheng/PycharmProjects/tf-read-write/data_manager/data/cifar-10-batches-py'
使用glob来获取当前文件夹下所有的训练样本所对应的文件:
trfiles = glob.glob(folders + "/data_batch*")
接下来对每个文件调用解析函数,获取到解析数据是一个字典,分别定义两个空list来读取字典的数据和标签。我们将标签打印出来看看。
data = []
labels = []
for file in trfiles:
dt = unpickle(file)
data += list(dt[b"data"])
labels += list(dt[b"labels"])
print(labels)
结果:(label值对应着classfication的下标)

接下来我们对数据进行解析,将图片进行存储,在cifar10中,图片的大小为32*32,我们将data转为4个纬度的数据,-1表达了当前有多少张图片,具体-1的值会根据data原始的维度来除以一张图片的大小:
imgs = np.reshape(data, [-1, 3, 32, 32])
#采用opencv对图像进行读取和存储,对所有图片进行遍历,img.shape第0个位置是当前数据的数量。由于cv对图片的存储纬度由所不同,先将
#[-1,3,32,32]转化为[-1,32,32,3],在将RGB转化为BGR
for i in range(imgs.shape[0]):
im_data = imgs[i, ...]
im_data = np.transpose(im_data, [1, 2, 0])#[-1,32,32,3]
im_data = cv2.cvtColor(im_data, cv2.COLOR_RGB2BGR)
#接下来定义数据存放的位置,图片的下一级目录为图片的类别
f = "{}/{}".format("/home/jincheng/PycharmProjects/tf-read-write/data_manager/data/image/train", classification[labels[i]])
#如果文件夹不存在,则新建
if not os.path.exists(f):
os.mkdir(f)
#向相应类别的文件夹写入当前的图片
cv2.imwrite("{}/{}.jpg".format(f, str(i)), im_data)
运行得到以下结果:
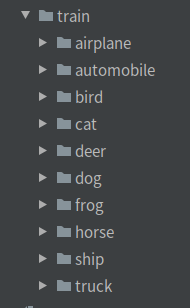
同理也可以得到测试集的数据
下面我们进行数据打包,打包成TFRecord二进制文件格式的数据,并且将这些数据用于后续的模型训练
import glob
idx = 0#idx用来指向我们当前已经遍历到了第几个类别
im_data = []
im_labels = []
for path in classification:#对10个类别进行遍历
path = "/home/jincheng/PycharmProjects/tf-read-write/data_manager/data/image/train/" + path#将train路径拼接上类别成为类别文件夹的路径
im_list = glob.glob(path + "/*")#利用glob获取类别文件夹下面的图片,返回的是图片路径list
im_label = [idx for i in range(im_list.__len__())]#定义一个和图片list长度相同的标签list,实际是当前类别遍历的ID号
idx += 1#每次遍历完一个类别,将idx+1
im_data += im_list
im_labels += im_label#这样我们就得到了训练集所有的图片数据和标签
接下来我们对这些获取得到的数据进行存储
tfrecord_file = "data/train.tfrecord"#定义用来存tfrecord文件的路径
writer = tf.python_io.TFRecordWriter(tfrecord_file)#定义tfrecord写入的实例,参数为文件的路径
index = [i for i in range(im_data.__len__())]
np.random.shuffle(index)#用来在打包数据的时候就打乱顺序
for i in range(im_data.__len__()):#遍历当前数据文件
im_d = im_data[index[i]]
im_l = im_labels[index[i]]
data = cv2.imread(im_d)#现在图片的数据是图片的路径,所以通过opencv对图片的数据进行读取
#data = tf.gfile.FastGFile(im_d, "rb").read()#和opencv一样可以读取数据,并且度出是bytes型了,并且解码方式和opencv不同
ex = tf.train.Example(#将数据写入tfrecord需要定义一个example通过feature对数据进行存储
features = tf.train.Features(
feature = {#通过字典存放数据
"image":tf.train.Feature(
bytes_list=tf.train.BytesList(#采用bytes进行存储
value=[data.tobytes()])),
"label": tf.train.Feature(
int64_list=tf.train.Int64List(#laibel用int
value=[im_l])),
}
)
)#通过example对一组图片的数据和标签进行封装
writer.write(ex.SerializeToString())#我们将example序列化后写入tfrecord中
writer.close()#写入数据后,我们将writee关闭
运行结果: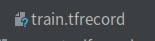
3.数据读取
方法一:采用tf.train.slice_input_producer:
import tensorflow as tf
#定义两个list分别表达了图片的路径和label
images = ['image1.jpg', 'image2.jpg', 'image3.jpg', 'image4.jpg']
labels = [1, 2, 3, 4]
[images, labels] = tf.train.slice_input_producer([images, labels],num_epochs=None,shuffle=True)
#对输入的图片list按照相应的规则生成相应的张量,输出两个张量,num_pochs表示将所有样本循环训练的次数
with tf.Session() as sess:#通过session来执行当前从文件队列中获取tensor的流程
sess.run(tf.local_variables_initializer())#对局部变量进行初始化
tf.train.start_queue_runners(sess=sess)#构造文件队列填充的线程
for i in range(10):
print(sess.run([images, labels]))#从文件队列中获取数据
结果: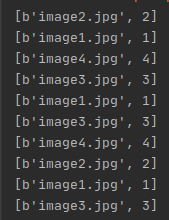
方法二:tf.train.string_input_producer从文件中读取数据
3个文件分别为(文件名和label):

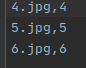
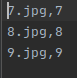
import tensorflow as tf
filename = ['data/A.csv', 'data/B.csv', 'data/C.csv']
file_queue = tf.train.string_input_producer(filename,shuffle=True,num_epochs=2)#参数为文件路径的list,输出是文件队列
reader = tf.WholeFileReader()#定义文件的读取器
key, value = reader.read(file_queue)#获取到文件的数据
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(6):
print(sess.run([key, value]))
结果: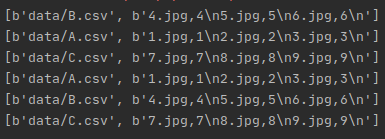
方法三:对TFRecord打包过的数据进行解析
import tensorflow as tf
filelist = ['data/train.tfrecord']#定义一个list,就是想要读取的tfrecord文件的路径
file_queue = tf.train.string_input_producer(filelist,num_epochs=None,shuffle=True)
#对于文件类的读取同样采用tf.train.string_input_producer,输出文件队列
reader = tf.TFRecordReader()#定义读取器
_, ex = reader.read(file_queue)#读取文件
feature = {
'image':tf.FixedLenFeature([], tf.string),#将bytes解码为string
'label':tf.FixedLenFeature([], tf.int64)
}#对序列化之后的数据进行解码
batchsize = 2
batch = tf.train.shuffle_batch([ex], batchsize, capacity=batchsize*10,min_after_dequeue=batchsize*5)
#通过shuffle_batch构造一个batchsize的数据
example = tf.parse_example(batch, features=feature)#对这个batch进行解码
image = example['image']
label = example['label']
image = tf.decode_raw(image, tf.uint8)#将string解码为uint8
image = tf.reshape(image, [-1, 32, 32, 3])
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(1):
image_bth, _ = sess.run([image,label])
import cv2
cv2.imshow("image", image_bth[0,...])#对第一张图片进行可视化
cv2.waitKey(0)#等待
结果:
(三)TensorFlow中的高层接口(slim)
.slim layers
.slim.arg_scope(list_ops_or_scope,**kwargs)#第一个是操作列表,第二个是这些操作共同用的参数
.在使用slim.batch_norm()函数时,我们需要定义以下两个参数
1.normalizer_fn=slim.batch_norm
2.normalizer_params=batch_norm_params:'is_training'(训练时设置为true),‘updates_collections':tf.GraphKeys.UPDATE OPS对batch_norm层进行标识
batch_norm层参数需另外更新,方法有两种:

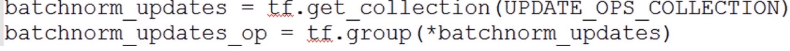
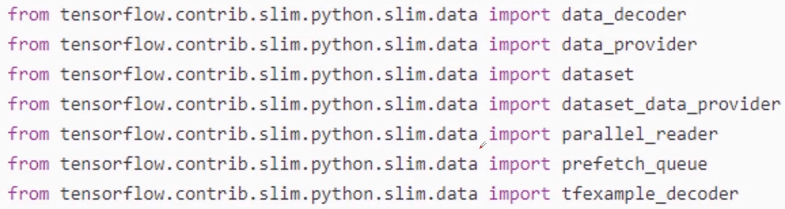
.slim.data
有很多对数据的操作方法,在slim.__init__中有如下几种:
.slim evaluation
其中包含用于使用metric_ops.py模块中的指标编写模型评估脚本的帮助函数:
1.evaluation_loop(多次评估)

2.evaluation_once(一次评估)
.slim learning
学习率:(开始大,结尾小)

优化器:

.slim losses
.slim nets(已经定义好的网络结构)
.slim variables
.slim metrics
1.value_op是一个幂等操作,返回度量的当前值
2.update_op是执行上述聚合步骤以及返回度量值的操作

(四)TensorFlow实现数据增强
数据增强是防止模型过拟合的手段
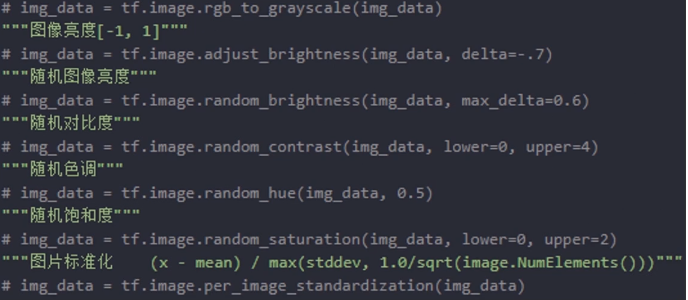
1.tf.image库进行数据增强(颜色扰动,裁剪/Pad,噪声/模糊,翻转/旋转,Draw Boxes,标准化)
2.其他数据增强的方法:

扩大样本,增加图像的扰动性以及模型的鲁棒性
3.TensorFlow常见数据增强方法:
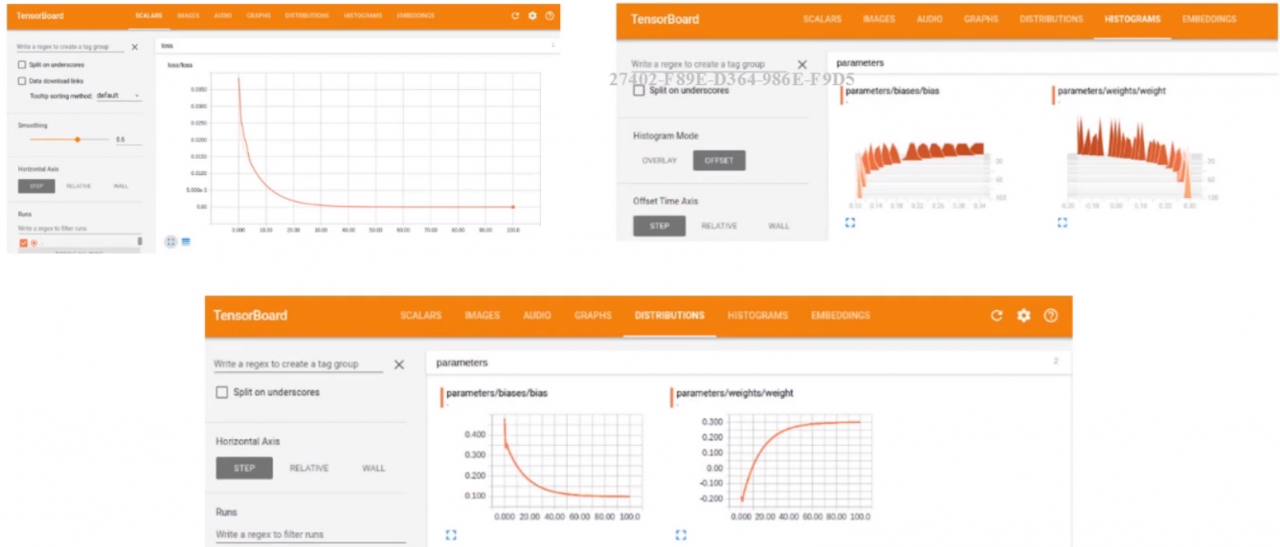
(五)Tensorboard调试技巧
1.Tensorboard可以进行网络可视化/训练中间结果可视化
pip3 install tensorboard
tensorboard --logdir logs
在浏览器中输入localhost:6060
配合tf.summary的使用:
记录可视化的值,将这些值添加到log中,比如sess.graph,bias,loss,image然后通过sess.run将合并后的中间结果存放到log中,我们在存放的时候是按照step(一个计数器,从0开始),最后tensorboard会将我们存好的log按照step进行绘制。

一些结果图:
下一期:TensorFlow挑战Cifar-10图像分类任务
 金乘
金乘
 原创文章 9获赞 11访问量 1812
关注
私信
展开阅读全文
原创文章 9获赞 11访问量 1812
关注
私信
展开阅读全文
作者:金乘