CosFace[2018-CVPR]
Motivation
极大化类间differences ,极小化类内variations !!!
Novelty
L2-normalizing both features and weight vectors to remove radial variation.
Cosine Loss
作者:_ReLU_
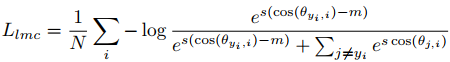
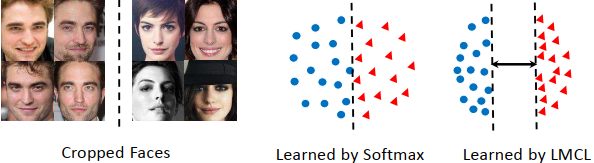
Margin
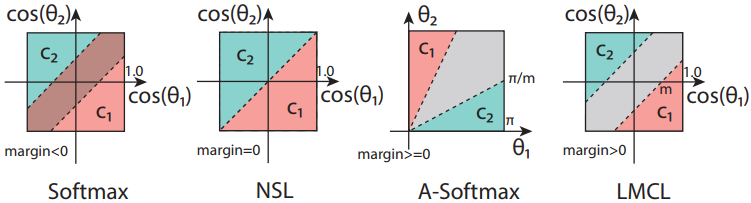
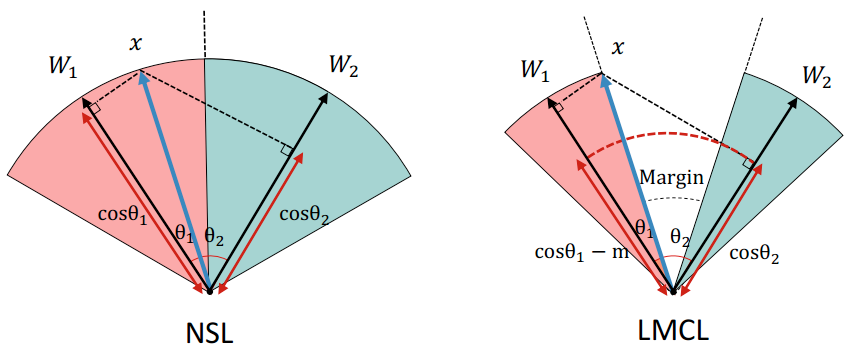
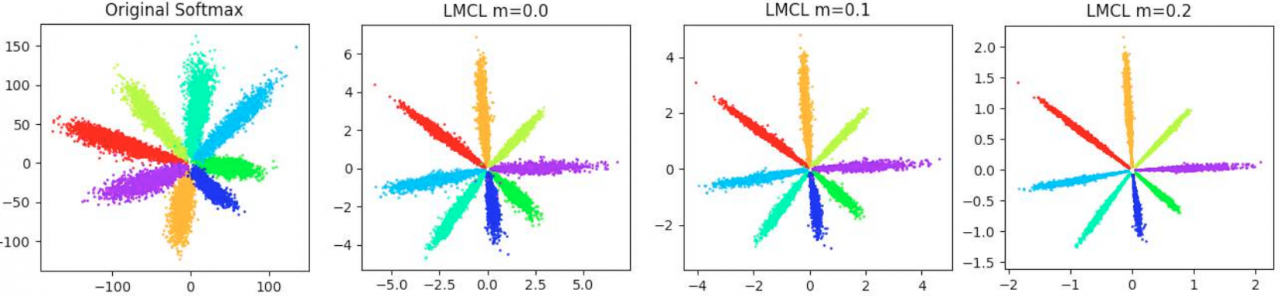
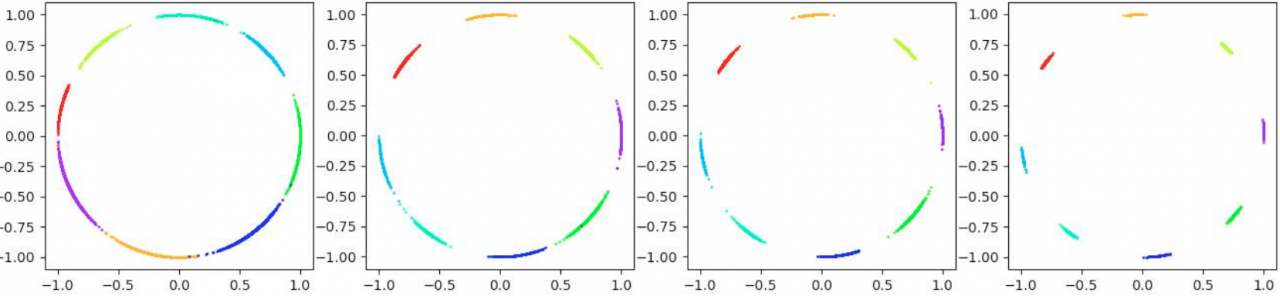
备注:前4幅小图是从loss-boundary的视角呈现的;后2幅图是从feature-boundary的视角呈现的.
Normalization on Features 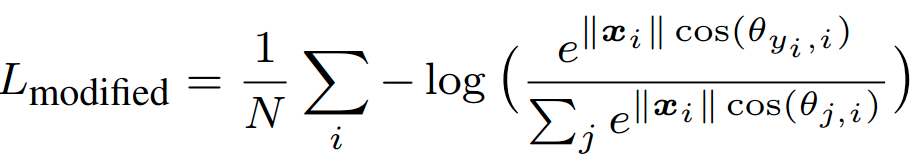 ,
,

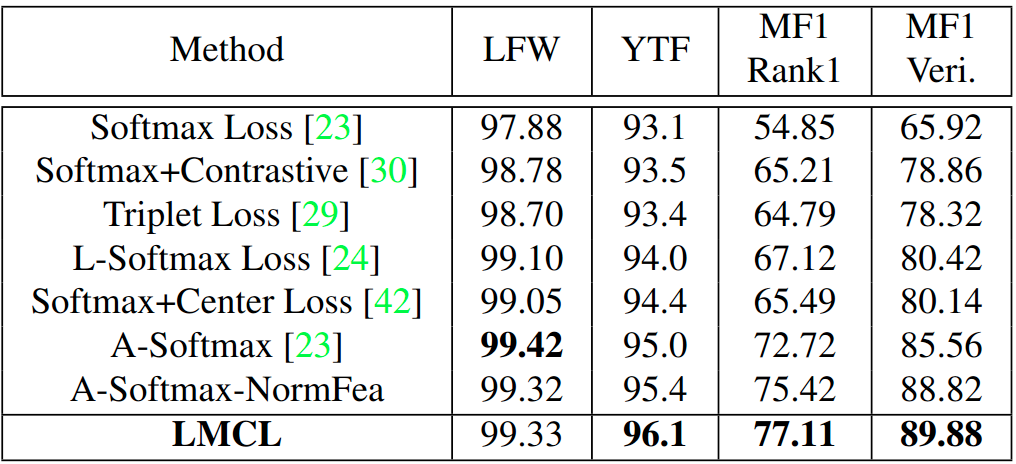
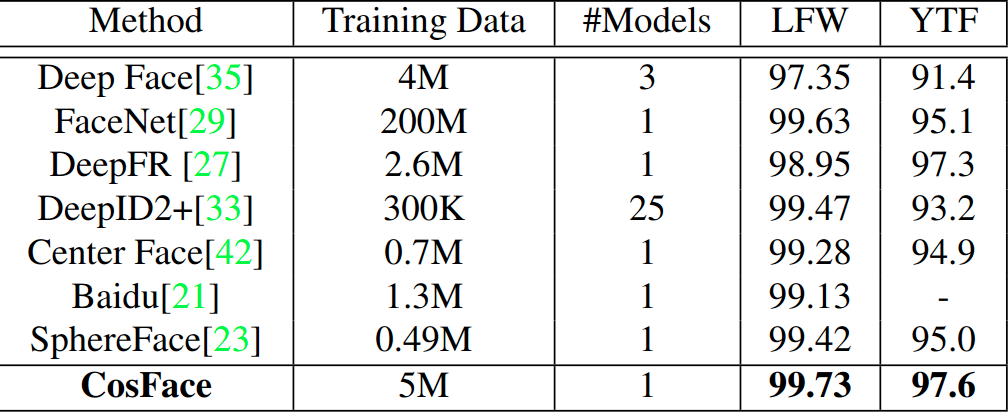
[1]. CosFace: Large Margin Cosine Loss for Deep Face Recognition
作者:_ReLU_