Edge-Labeling Graph Neural Network for Few-shot Learning--CVPR2019--论文笔记
记录一下自己看的文章,和一些自己的见解。
这次看的文章是《基于边标签图神经网络的少样本学习》
Abstract
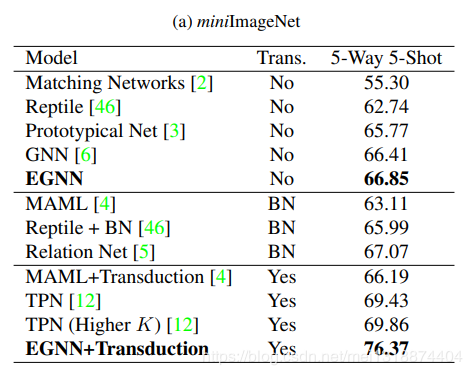
在本文之中,我们提出了一个新的基于边标签的图神经网络(EGNN),适用于一些少样本学习(few-shot learning),以往的图卷积神经网络只是基于节点标签的框架,然而提出的EGNN通过利用类内的相似性和类间的不相似行不断地更新迭代,不仅仅只是学习预测节点标签,而且会预测变得标签。更加适用于各种不同类别之间的且不需要重新训练。在目前的两种数据集之中EGNN体现出更好的效果相较于现在的GNNs
总结一下本文的贡献
1.EGNN是第一个利用类内的相似性和类间的不相似行不断地更新迭代边标签的模型,而且适用于多种不同类别之间的迁移,且不需要retraining。
2.EGNN由很多层组成,每一层都有对应的节点更新快,和边更新快,其相应的参数是在episodic training framework下进行估算的。
3.在现存的2个少样本学习的数据集之下,EGNN比GNN有更好的效果。 Related works
1.图神经网络(Graph Neural Network):图神经网络就是每个节点的更新是基于不同邻居节点的不同聚合方式进行更新。说简单点就是说,经过图神经网络之后的每个节点里面的信息都包含了其邻居节点的相关信息。
2.Edge-Labeling Graph
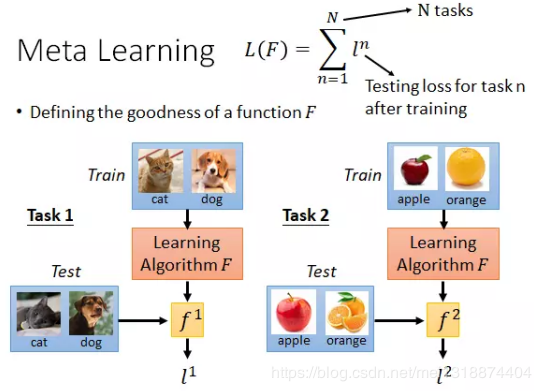
3.Few-Shot Learning:few-shot的训练集包含很多类别,每个类别有多个样本,在训练阶段,会在训练集中随机抽取K个类别,每个类别q个样本(供qK个数据构成一个meta-task),作为Support Set(支撑集),再从K个类中剩余的数据中抽取一批样本作为模型的预测对象。即要求以qK个数据学会如何区分这K个类别,这样的任务称为K-way,q-shot问题。K个类别k-way,q个样本q-shot。Few-Shot Learning一般都是用一个叫做meta learning的思想。meta learning:希望在不同任务上机器都能自己学会一个模型。所以其适用于少样本学习。在few-shot learning的常用数据集中,会有很多不同的类别,meta learning希望对于每一个类别都学会出一个模型。例如:
.3. Method
3.1. Problem definition: Few-shot classification
就像上面说的一样每一个少样本分类器都包括一个支持集S合一个查询机Q,然后这个支持集S里面包括N个样本,K个类,那么就叫做其为,N-way,k-shot。利用meta learning来训练少样本分类器。具体的说,N-way,k-shot问题的话。如文中所说。既是。
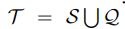
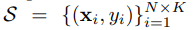
![]()
解释一下含义:
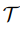
:指 few-shot classification task,任务数。
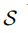
:指支持集support set
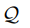
: 指查询集query set
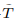
:指查询集的数量。
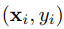
:指其输入的数据和其对应得标签。
3.2. Model
如图:
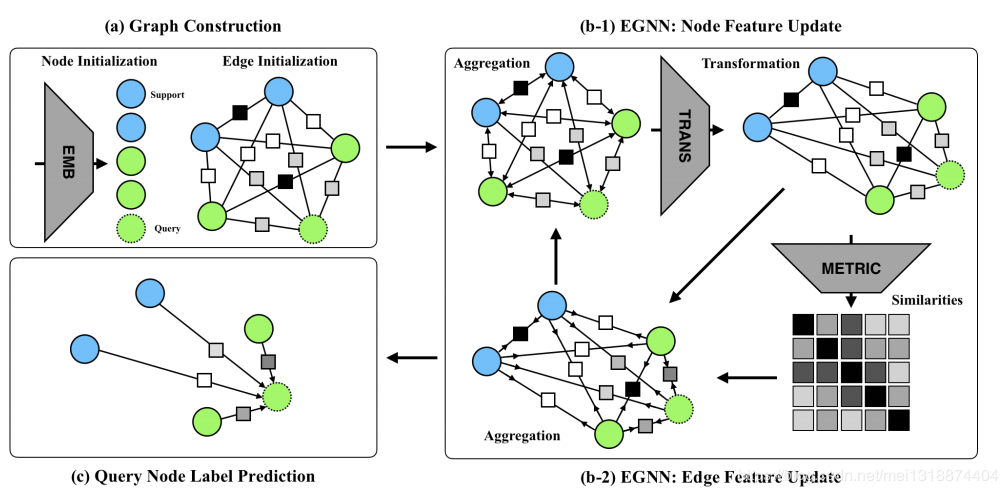
每一个节点代表一个样本,每一条边代表连接节点的关系。如图所示描述了一个2-way,2-shot的实例。不同颜色的小圆代表不同类别的样本,然后边的标签用正方形的颜色来表示。
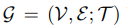
代表在任务T中的节点集合和边集
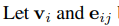
代表其节点的特征和边的特征。

边标签的定义是:
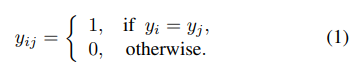
如果输入样本的Xi和Xj的标签相同那么定义其边为1,否则为0
![]()
每个边的特征都有2个维度。一个代表其类内的特征,一个代表其类间的特征。其值在0~1之间,在后面可以用来表示两个节点之前有无关系的概率。
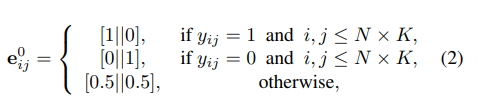
很好理解,如果其是同一类,或者其不是同一类,或者其相邻节点不属于支持集。
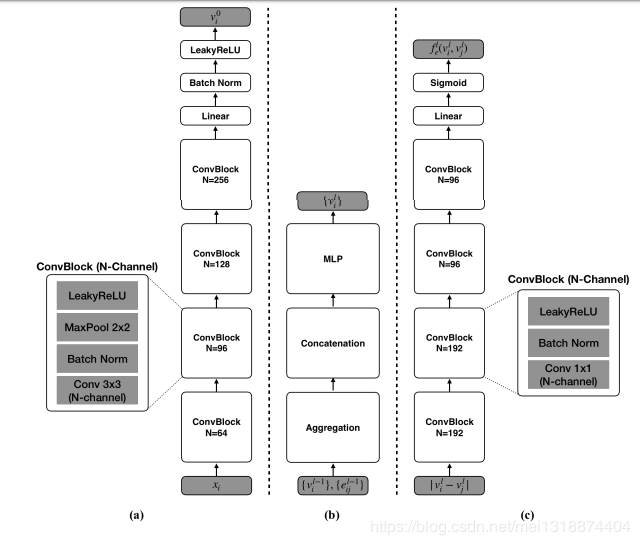
如图(a):是一个卷积神经网络,节点特征的初始化是有卷积神经网络得到的,通过输入xi,然后得到vi。
公式如下:
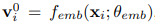
其中:f是卷积神经网络,θ是参数
如图(b):是一个节点更新的神经网络,输入是边的特征和节点的特征,公式如下:
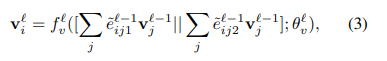
这个其实还好理解,就是把边的不同维数的特征(分别代表类内,和类间(相似性和不相似性))和节点特征相乘,因为都是向量嘛,然后2个结果做连接操作,作为参数传入神经网络,得到更新之后的节点特征,这个时候的节点特征就是包含了相应的边的语意信息了。信息更加饱满。可以看到图中就是先进行算法,然后连接操作,然后进入一个多层感知机,最后得到更新之后的节点信息。
其中:eijd是做了归一化操作,f是卷积神经网络,θ是参数
如图(c):是一个更新边特征的神经网络,相应的更新边特征的公式如下:
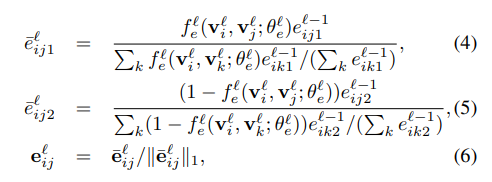
其中f就是图c的神经网络,f代表的是类内之间的相似性的神经网络,用(1-f)来代替类间之间的不相似性的神经网络。我们可以看到如图C的是网络,在最后经过了一个sigmod函数,所以的话它的输出应该是一个0或者1,就是代表2节点之间是否有关系吧,就是说我现在通过之前更新的节点特征来确定2各节点是否有关系,然后再和边特征结合起来,再来更新下一层的边的特征。然后在公式中可以看到分母其中的2个除号就是乘,既归一化的处理,就是化简之后其实就是说,得到的eij的特征之后在除以一个类之间有关联的个数,那个f连加之后得到的不就是类之间有关联的个数嘛。所以得到的新的eij1或者eij2就是相当于一个权重的东西。然后,之后看第3个公式,结合3个公式化简,得到其实就是把eij的值根据目前节点的特征重新更新。得到的是一个趋于0~1之间的数。因为公式6是除以它的范数嘛,化简之后就是了。
然后接下来 就是有:
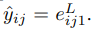
意思就是把我们之前得到的eij1的值当做是yij的值,就是说把eij1得到的1个0~1之间的这个数值,当做是yij两个节点之间属于同一类的概率。
然后文中把某一个节点属于某一个类的概率当做是这个节点相临边的权重的和既是文中的公式:
![]()
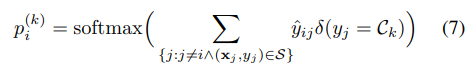
其中这个 δ(yj = Ck)函数是Kronecker delta函数,他的意思是当内容相等时为1,不相等时为0.也好理解啊,就是说一个节点的边有可能相连的节点不是一个类的那么这种边肯定就不能用来加权求和,所以我们就要让其为0卅。所以这个函数的意思就是把一个节点上的边的概率相加之后,然后用softmax函数将其映射到0~1的区间,用来当做节点的概率,既是预测该节点是属于某个类的概率。
下面是文中整体所用的算法:

理解了上面说的,这个算法其实也就很好理解了,就不过多阐述了。
下面是损失函数了:
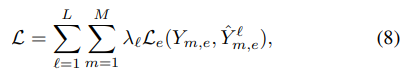
L代表第L层,M代表M个任务,因为之前说了嘛,这个是episodic training可以理解为多任务。λ是学习率,L是二元交叉滴损失,Y是真实的标签,Yˆ是预测的标签。就是说损失函数是所有M个任务L层的所有损失的和。
2020.2.20
作者:阿0是