对于 ResNet 残差网络的理解
最近用神经网络学习 已知一个结构来预测光谱 ,发现目前 Marin 提出的 4 层全链接得到的结果不能拟合好光谱中的一些 fano 共振峰。
对于这个问题,自己最近有一些思考,最后发现有些想法和 2015 年 何凯明 大神在论文(Deep residual learning for image recognition)中提出的残差网络 ResNet 不谋而合。由于 何凯明 大神已经早在 2015 年就已近提出这个想法啦。所以 我只能跟着大神写一写自己对此的思考,以及自己的一些理解。希望能加深一下自己对于神经网络的理解。
1.问题:2019 年 Marin 在论文(Nanophotonic particle simulation and inverse design using artificial neural networks)中指出,可以通过神经网络学习 Maxwell 方程。在这篇论文中, Marin 构建了 4 层全链接网络学习了 8 层的纳米小球的结构与光谱的对应关系。
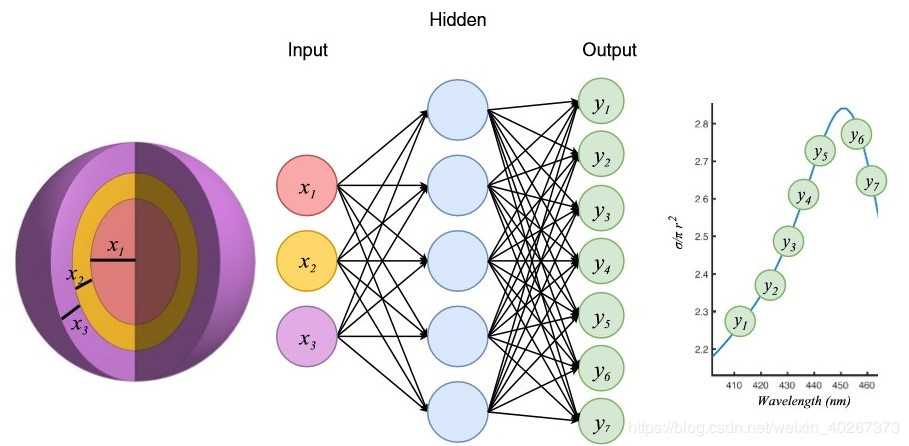
但是在重复 Marin 工作时,我们发现 4 层神经网络对于薄膜干涉等变化平缓的光谱拟合效果很好,但是对于像 guided resonance 之类的光谱上的 fano 共振峰。神经网络的拟合效果并不好。
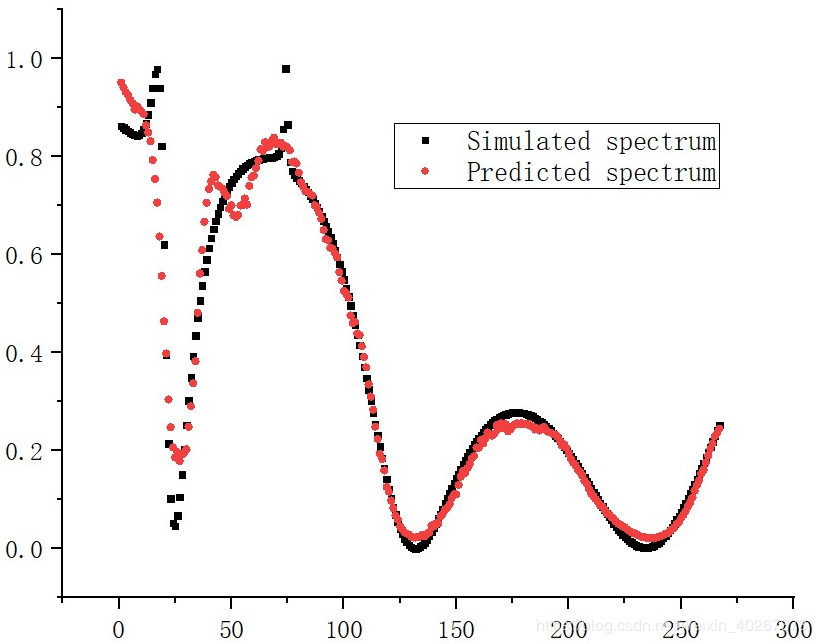
我们需要思考的问题便是:如何使得神经网络能够将这些 fano 共振峰也匹配的较好?
2.我的思考:对此我进行了许多的尝试,其中的一个尝试如下:
使用 Marin 提出的 4 层全链接网络 输入结构参数要求网络输出对应的光谱,对 Maxwell 方程进行学习,如下图所示。
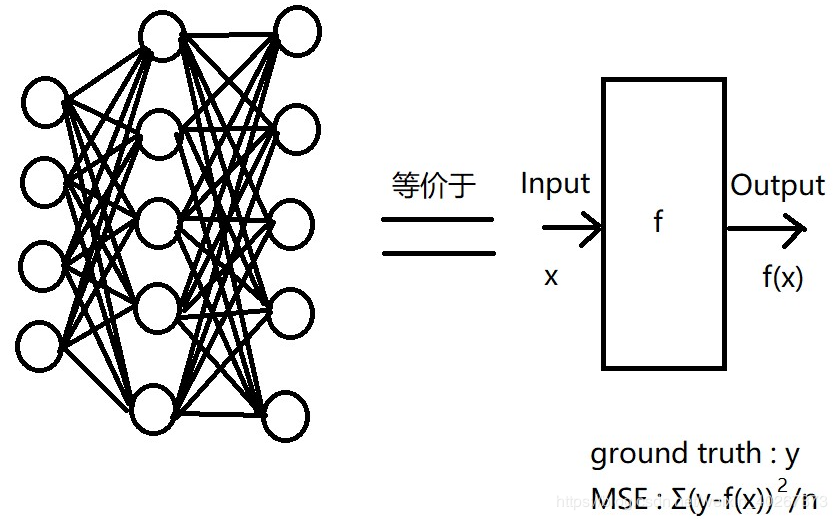
其中 Marin 提出的网络可以看成等价于右边的一个黑箱子函数。黑箱子函数输入 xxx 输出 f(x)f(x)f(x),但是实际电磁场数值求解解出的解为 yyy。所以我们可以将两者的 MSEMSEMSE 作为 LossLossLoss 函数来进行训练。最后得到的结果,虽然上面有但我再展示一遍吧,薄膜干涉部分的拟合效果很好,而在 fano 共振峰处拟合效果不好。
紧接着,我想这个网络学不会 fano 却把薄膜干涉学的很好?这是因为薄膜干涉在整个图中占有的比例太大了。导致网络会忽略一些小细节。而它忽略的小细节 fano 共振峰在物理中却非常重要。
那么将 f(x)f(x)f(x) 和 yyy 做差值得到的结果不就只有 fano 的峰了吗?
我将 y−f(x)y-f(x)y−f(x) 作为 ground truth ,同样将结构作为输入值要求网络输出的结果与只有 fano 的 y−f(x)y-f(x)y−f(x) 尽可能的匹配不就可以学会 fano 了吗?
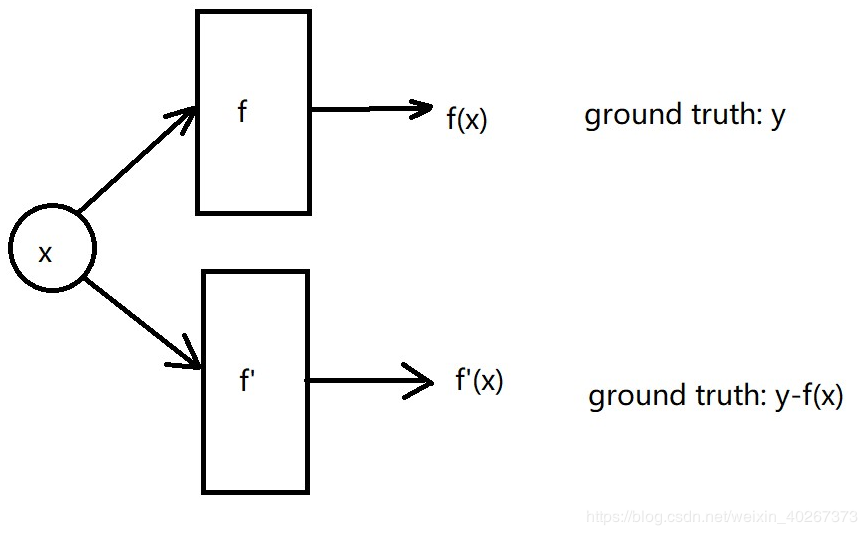
当时想法很朴实,但是被证明是没有效果的。第二个网络仍然不能学会 fano 共振峰,随后我便没再深入继续向这个方向思考了。
直到后面我看到了 2015 年 何凯明 大神提出的残差网络,才发现我的这个想法和残差网络的思想不谋而合,其实上图中的网络已经是一个残差网络了,虽然长的和 ResNet 残差网络的结构有点不同。
3.残差网络下面将从上面我的思考出发,证明上图中的结构和 ResNet 残差网络是一个东西。不过 何凯明 大神比我想得更多。
上面,我构想的网络是一种并联结构,而 ResNet 是一种串联结构。为了证明两者的等价性。要么把 ResNet 改成并联结构,要么把上图中的网络改成串联结构。由于 ResNet 已经是一种很经典的结构了。于是下面我们把上图中的网络改成串联结构。
思考:什么样的网络和上图中的并联网络是等价的?
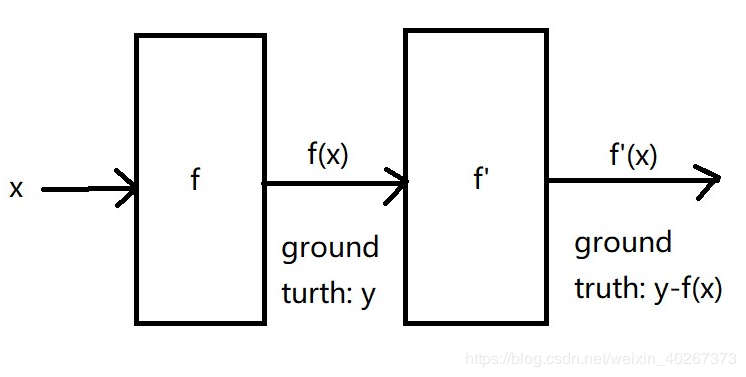
一个很简单的想法如上图所示,直接将两个网络连接在一起,但是会有一个问题。最后需要比较的是 y−f(x)y-f(x)y−f(x) 和 f′(x)f'(x)f′(x) 而且网络最后输出的结果也不是我们想要的尽可能接近 yyy 的光谱结果 f′(x)+f(x)f'(x)+f(x)f′(x)+f(x)。
如果我们要求 最终串联网络输出的结果为 f′(x)+f(x)f'(x)+f(x)f′(x)+f(x),那么我们需要将串联网络第一部分的输出结果 f(x)f(x)f(x) 与第二部分的输出结果 f′(x)f'(x)f′(x) 相加。由此我们可以得到 2015 年 何凯明 大神在论文中提出的 ResNet 残差网络中一个残差模块的结构。
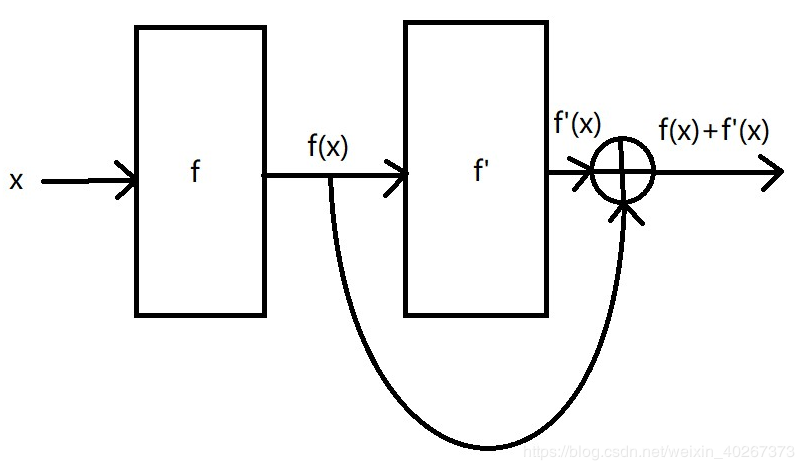
从这个角度上来讲,由于是在原本的网络上叠加残差模块,故最终得到的叠加了很多层的残差网络的性能不会低于原本的网络。对于一个很浅的网络来说,在每一层后面都加上很多残差模块可以将网络变深,且拟合效果远远优于原来的网络。
上面仅仅是对残差网络为什么效果比原本浅层网络效果好的一个理解。但残差网络还有许许多多优秀的性质,如形成 shortcut 大大降低了运算量,残差模块加入恒等映射层 y=xy=xy=x 使得网络随深度的增加不会产生权重衰减,梯度衰减或消失的问题。
下面我用 Tensorflow 2.0 在一个原来很浅的全链接网络上面叠加残差模块,使它变得很深且能解决之前我遇到的 fano 共振峰拟合效果不好的问题。
input = tf.keras.Input(shape=(4), name='Input')
dense1 = tf.keras.layers.Dense(4, activation='relu', name='ResidualBlock1')(input)
out = tf.keras.layers.Add()([dense1,input])
out = tf.nn.relu(out)
dense2 = tf.keras.layers.Dense(4, activation='relu', name='ResidualBlock2')(out)
out = tf.keras.layers.Add()([dense2,out])
out = tf.nn.relu(out)
dense3 = tf.keras.layers.Dense(4, activation='relu', name='ResidualBlock3')(out)
out = tf.keras.layers.Add()([dense3,out])
out = tf.nn.relu(out)
out = tf.keras.layers.Dense(500, activation='relu', name='Transform_1')(out)
dense4 = tf.keras.layers.Dense(500, activation='relu', name='ResidualBlock4')(out)
out = tf.keras.layers.Add()([dense4,out])
out = tf.nn.relu(out)
dense5 = tf.keras.layers.Dense(500, activation='relu', name='ResidualBlock5')(out)
out = tf.keras.layers.Add()([dense5,out])
out = tf.nn.relu(out)
dense6 = tf.keras.layers.Dense(500, activation='relu', name='ResidualBlock6')(out)
out = tf.keras.layers.Add()([dense6,out])
out = tf.nn.relu(out)
out = tf.keras.layers.Dense(267, activation='relu', name='Transform_2')(out)
dense7 = tf.keras.layers.Dense(267, activation='relu', name='ResidualBlock7')(out)
out = tf.keras.layers.Add()([dense7,out])
out = tf.nn.relu(out)
dense8 = tf.keras.layers.Dense(267, activation='relu', name='ResidualBlock8')(out)
out = tf.keras.layers.Add()([dense8,out])
out = tf.nn.relu(out)
dense9 = tf.keras.layers.Dense(267, activation='relu', name='ResidualBlock9')(out)
out = tf.keras.layers.Add()([dense9,out])
out = tf.nn.relu(out)
output = tf.keras.layers.Dense(267, activation='linear', name='Output')(out)
model = tf.keras.Model(inputs=input, outputs=output)
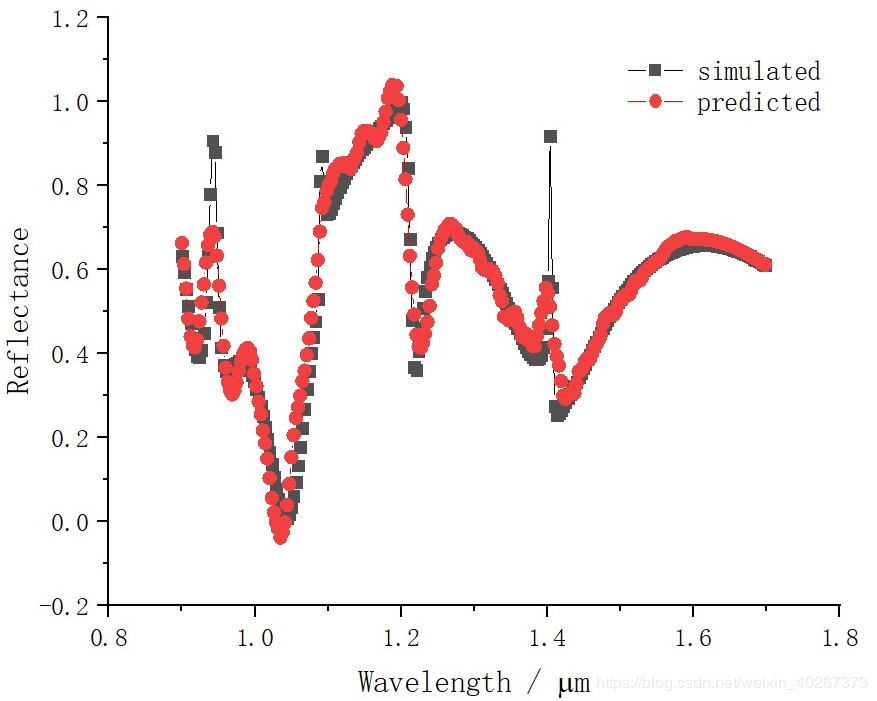
最后得到的拟合结果,可以看到即使对于一些很小的 fano 共振峰也能有较好的匹配。
作者:Lingjie Fan