【人工智能学习】【十五】残差网络
理论上来说深层网络一定包含了浅层网络能拟合出的映射,但并不是层数越多越好。深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,准确率也变得更差。
残差网络网络随着深度的变深,映射出来的特征越抽象,包含的信息越少(信息论的角度讲,由于DPI(数据处理不等式)的存在,在前向传输的过程中,随着层数的加深,Feature Map包含的图像信息会逐层减少),那么如果使每一层的信息都变得比前面一层多,就解决这个问题了,这个就是残差网络的核心思想。据说残差的思想是来自于LSTM门控的思想。总的来说是打破了网络的对称性,提升了网络的表征能力1。
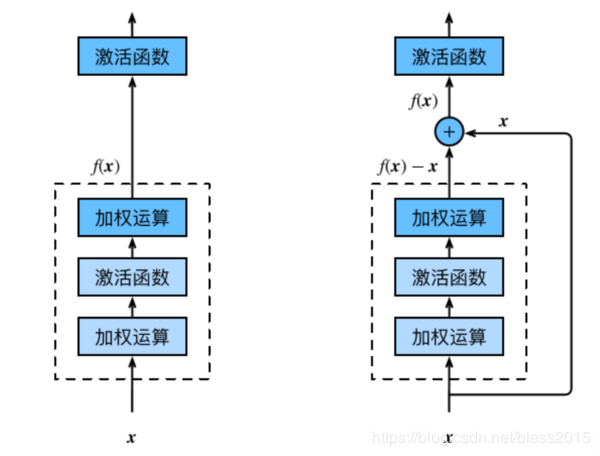
残差网络和传统网络模型对比,就是多了右边一条线
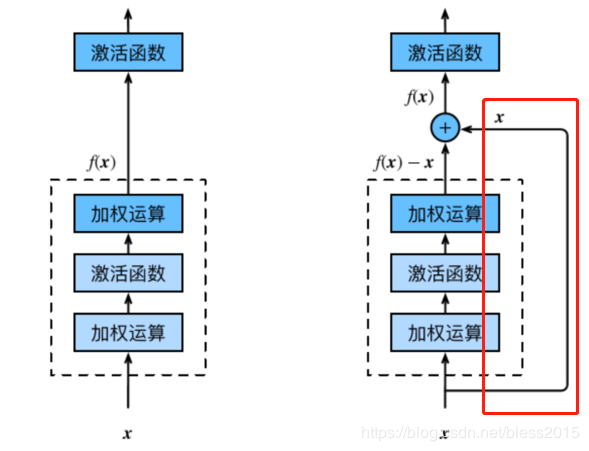
xix_ixi经过网络运算后得到f(x)f(x)f(x),输入到下一层的xi+1x_{i+1}xi+1变成
xi+1=f(xi)+xix_{i+1}=f(x_i)+x_ixi+1=f(xi)+xi
这里要保证f(xi)f(x_i)f(xi)和xix_ixi的形状保持一致。这是最简单的残差skip思想,关于如何skip都是一直在研究的方向。这里只介绍最简单的这种情况。
为什么叫残差呢,我的理解是,对于xi+1x_{i+1}xi+1,那么第iii层训练出来的WWW和bbb是一个与xix_ixi差值有关的信息。
残差块
class Residual(nn.Module): # 本类已保存在d2lzh_pytorch包中方便以后使用
#可以设定输出通道数、是否使用额外的1x1卷积层来修改通道数以及卷积层的步幅。
def __init__(self, in_channels, out_channels, use_1x1conv=False, stride=1):
super(Residual, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
# 这句是精髓
return F.relu(Y + X)
测试
blk = Residual(3, 3)
X = torch.rand((4, 3, 6, 6))
blk(X).shape # torch.Size([4, 3, 6, 6])
torch.Size([4, 3, 6, 6])
blk = Residual(3, 6, use_1x1conv=True, stride=2)
blk(X).shape # torch.Size([4, 6, 3, 3])
torch.Size([4, 6, 3, 3])
torch模型实现网络结构定义
net = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
残差块
def resnet_block(in_channels, out_channels, num_residuals, first_block=False):
if first_block:
assert in_channels == out_channels # 第一个模块的通道数同输入通道数一致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels, use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
# 全连接层 做分类
net.add_module("global_avg_pool", d2l.GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(), nn.Linear(512, 10)))
测试
X = torch.rand((1, 1, 224, 224))
for name, layer in net.named_children():
X = layer(X)
print(name, ' output shape:\t', X.shape)
0 output shape: torch.Size([1, 64, 112, 112])
1 output shape: torch.Size([1, 64, 112, 112])
2 output shape: torch.Size([1, 64, 112, 112])
3 output shape: torch.Size([1, 64, 56, 56])
resnet_block1 output shape: torch.Size([1, 64, 56, 56])
resnet_block2 output shape: torch.Size([1, 128, 28, 28])
resnet_block3 output shape: torch.Size([1, 256, 14, 14])
resnet_block4 output shape: torch.Size([1, 512, 7, 7])
global_avg_pool output shape: torch.Size([1, 512, 1, 1])
fc output shape: torch.Size([1, 10])
调用
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
DenseNet
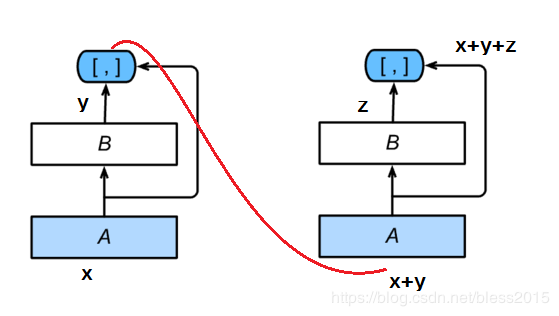
DenseNet是一个ResNet的引申设计,主要区别就是在于skip部分是如何计算的。
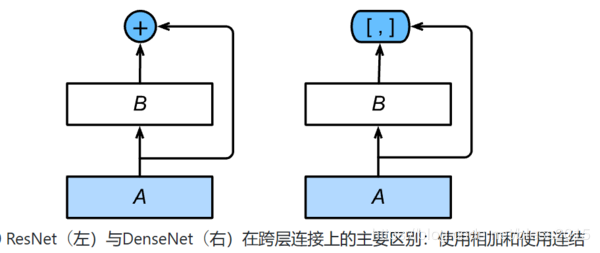
左侧的ResNet是xi+1=f(xi)+xix_{i+1}=f(x_i)+x_ixi+1=f(xi)+xi做的加法。
右侧DenseNet是做的concat连接,f(xi)f(x_i)f(xi)和xix_ixi的形状不要求一样。
DenseNet的结构分为稠密块(dense block): 定义了输入和输出是如何连结的。过渡层(transition layer):用来控制通道数,使之不过大。
稠密块:
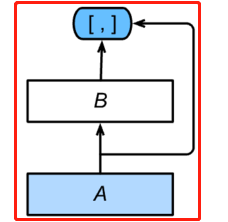
过渡块:
因为skip是一个连接操作,那么要防止维数(通道)数量不要太大。
# 把归一化BN层、ReLU层、卷积层打个包
def conv_block(in_channels, out_channels):
blk = nn.Sequential(nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
return blk
class DenseBlock(nn.Module):
def __init__(self, num_convs, in_channels, out_channels):
super(DenseBlock, self).__init__()
net = []
for i in range(num_convs):
in_c = in_channels + i * out_channels
net.append(conv_block(in_c, out_channels))
self.net = nn.ModuleList(net)
self.out_channels = in_channels + num_convs * out_channels # 计算输出通道数
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X, Y), dim=1) # 在通道维上将输入和输出连结
return X
卷积层:1×11×11×1来减小通道数
步幅为2的平均池化层:减半高和宽
def transition_block(in_channels, out_channels):
blk = nn.Sequential(
nn.BatchNorm2d(in_channels),
nn.ReLU(),
nn.Conv2d(in_channels, out_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
return blk
blk = transition_block(23, 10)
blk(Y).shape # torch.Size([4, 10, 4, 4])
DenseNet模型
net = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
模型定义
net.add_module("BN", nn.BatchNorm2d(num_channels))
net.add_module("relu", nn.ReLU())
net.add_module("global_avg_pool", d2l.GlobalAvgPool2d()) # GlobalAvgPool2d的输出: (Batch, num_channels, 1, 1)
net.add_module("fc", nn.Sequential(d2l.FlattenLayer(), nn.Linear(num_channels, 10)))
X = torch.rand((1, 1, 96, 96))
for name, layer in net.named_children():
X = layer(X)
print(name, ' output shape:\t', X.shape)
0 output shape: torch.Size([1, 64, 48, 48])
1 output shape: torch.Size([1, 64, 48, 48])
2 output shape: torch.Size([1, 64, 48, 48])
3 output shape: torch.Size([1, 64, 24, 24])
DenseBlosk_0 output shape: torch.Size([1, 192, 24, 24])
transition_block_0 output shape: torch.Size([1, 96, 12, 12])
DenseBlosk_1 output shape: torch.Size([1, 224, 12, 12])
transition_block_1 output shape: torch.Size([1, 112, 6, 6])
DenseBlosk_2 output shape: torch.Size([1, 240, 6, 6])
transition_block_2 output shape: torch.Size([1, 120, 3, 3])
DenseBlosk_3 output shape: torch.Size([1, 248, 3, 3])
BN output shape: torch.Size([1, 248, 3, 3])
relu output shape: torch.Size([1, 248, 3, 3])
global_avg_pool output shape: torch.Size([1, 248, 1, 1])
fc output shape: torch.Size([1, 10])
模型训练
#batch_size = 256
batch_size=16
# 如出现“out of memory”的报错信息,可减小batch_size或resize
train_iter, test_iter =load_data_fashion_mnist(batch_size, resize=96)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
d2l.train_ch5(net, train_iter, test_iter, batch_size, optimizer, device, num_epochs)
Shang W, Sohn K, Almeida D, et al. Understanding and Improving Convolutional Neural Networks via Concatenated Rectified Linear Units[J]. 2016:2217-2225. ↩︎
作者:番茄发烧了