编译原理复习第一篇
1.编译原理的“前端”和“后端”
“前端”指的是编译器对程序代码的分析和理解过程。它通常只跟语言的语法有关,跟目标机器无关。而与之对应的“后端”则是生成目标代码的过程,跟目标机器有关。整个编译过程简要,如图:
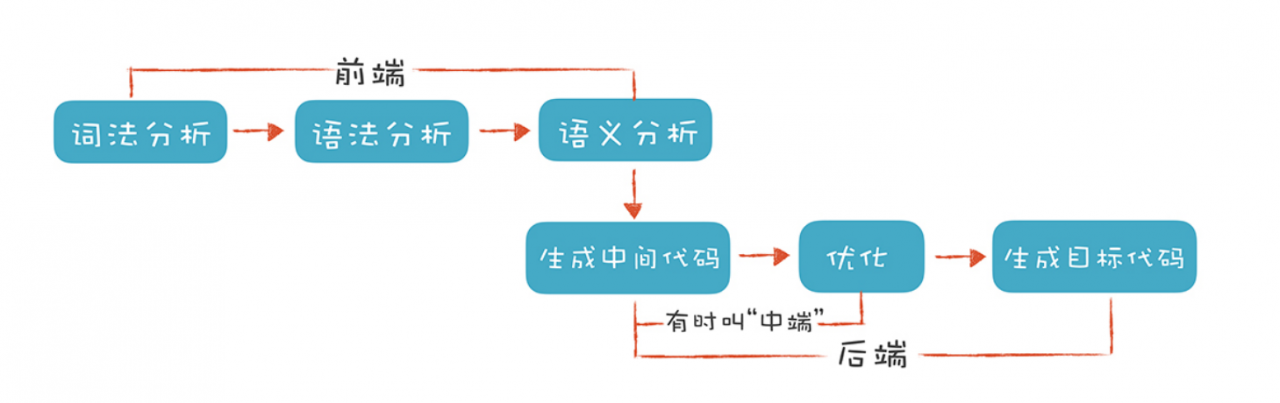
2.词法分析
用一套定义好的词法正则来解析程序字符串,最终得到单词。
3.语法分析:
用定义好的语法规则,生成AST语法树。这样计算机就知道如何执行一句一句的程序语句了。
4.demo:
查看以下网址,看看js代码生成的AST语法树。
https://resources.jointjs.com/demos/javascript-ast
5.常用的快速生成AST语法树的工具
https://blog.csdn.net/gongwx/article/details/99645305
6.语义分析:
对AST语法树的各个节点增加属性。具体做的事情是,比如:
某个表达式的计算结果是什么数据类型?如果有数据类型不匹配的情况,是否要做自动转换?
如果在一个代码块的内部和外部有相同名称的变量,我在执行的时候到底用哪个? 就像“我喜欢又聪明又勇敢的你”中的“你”,到底指的是谁,需要明确。
在同一个作用域内,不允许有两个名称相同的变量,这是唯一性检查。你不能刚声明一个变量 a,紧接着又声明同样名称的一个变量 a,这就不允许了。
7.总结:
词法分析是把程序分割成一个个 Token 的过程,可以通过构造有限自动机来实现。
语法分析是把程序的结构识别出来,并形成一棵便于由计算机处理的抽象语法树。可以用递归下降的算法来实现。
语义分析是消除语义模糊,生成一些属性信息,让计算机能够依据这些信息生成目标代码。
 SunShinessx
SunShinessx
 原创文章 47获赞 14访问量 2万+
关注
私信
展开阅读全文
原创文章 47获赞 14访问量 2万+
关注
私信
展开阅读全文
作者:SunShinessx