编译原理入门——什么是编译器?
什么是编译器?
作者:青花磁盘
编译器告诉计算机该怎么去理解我们编写的代码。我们编写的高级语言大致分为两种:
解释型:像Python,可以写一句执行一句;
编译型:像C,需要经过编译成.exe文件才能运行。
因此,编译器又分两种:
interpreter,解释器,不用将源代码翻译成机器语言,而是直接处理和运行源代码。 compiler,编译器,将源代码翻译成机器语言然后运行,一般运行速度比解释器运行速度快一点。 编译器示例举一个最简单的编译器例子:只接收正整数和“+”“-”,完成加减法,解释运行,计算机最后给出结果。
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, EOF = 'INTEGER', 'PLUS', 'MINUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, MINUS, or EOF
self.type = type
# token value: non-negative integer value, '+', '-', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3 + 5", "12 - 5 + 3", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
self.current_char = self.text[self.pos]
##########################################################
# Lexer code #
##########################################################
def error(self):
raise Exception('Invalid syntax')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
self.error()
return Token(EOF, None)
##########################################################
# Parser / Interpreter code #
##########################################################
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def term(self):
"""Return an INTEGER token value."""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter."""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
运行结果:
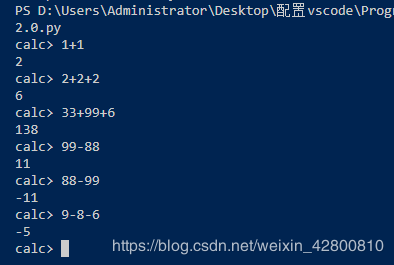
https://ruslanspivak.com/lsbasi-part1/
中国科技大学《编译原理》,华保健
作者:青花磁盘