编辑距离(Levenshtein Distance)
是用来度量两个序列相似程度的指标。通俗地来讲,编辑距离指的是在两个单词w1,w2之间,由其中一个单词w1变为w2所需要的最少单字符编辑操作次数。
当两个字符串都为空串,那么编辑距离为0;
当其中一个字符串为空串时,那么编辑距离为另一个非空字符串的长度;
当两个字符串均为非空时(长度分别为 i 和 j ),取以下三种情况最小值即可:
1、长度分别为 i-1 和 j 的字符串的编辑距离已知,那么加1即可;
2、长度分别为 i 和 j-1 的字符串的编辑距离已知,那么加1即可;
3、长度分别为 i-1 和 j-1 的字符串的编辑距离已知,此时考虑两种情况,若第i个字符和第j个字符不同,那么 加1即可;如果不同,那么不需要加1。
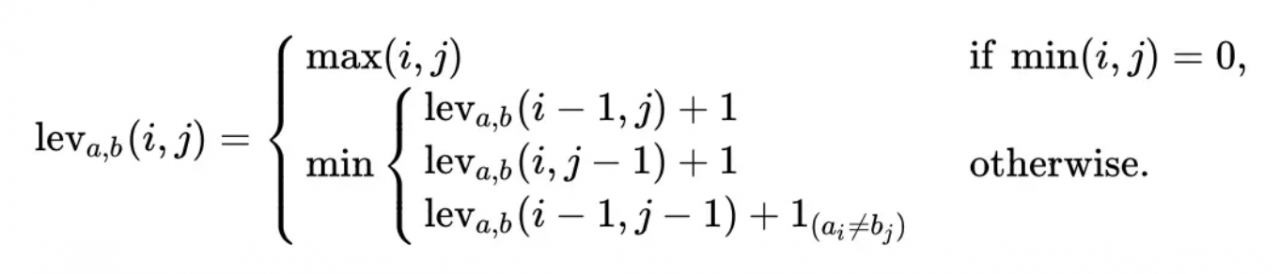
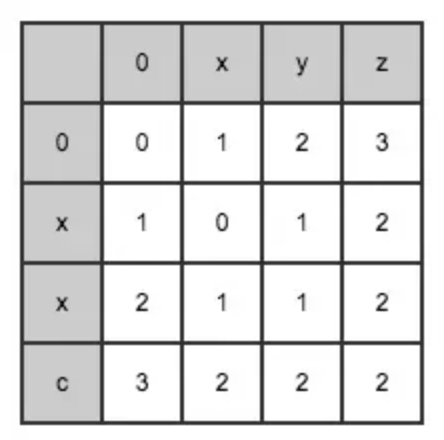
以 xxc 和 xyz 为例,建立一个矩阵,通过矩阵记录计算好的距离,当min(i,j)==0时,levab(i,j)=max(i , j),根据此初始化矩阵的第一行和第一列,然后依据上面的公式可以继续推导出后面的几行。
// 编辑距离
template
int levenshtein_distance(const T &s1, const T &s2) {
int m = s1.size();
int n = s2.size();
// 如果有一方长度为零则结束
if (m == 0 || n == 0)
return 0;
// 长度从1开始,需要两个0来初始化
m += 1;
n += 1;
// 申请内存空间,并强制转为int类型
int *dp = reinterpret_cast(malloc(m * n * sizeof(int)));
int i, j;
// 初始化矩阵 第一行 第一列
for (i = 0; i < m; i++) {
dp[i * n] = i;
}
for (j = 0; j < n; j++) {
dp[j] = j;
}
for (i = 1; i < m; i++) {
for (j = 1; j < n; j++) {
if (s1[i - 1] == s2[j - 1]) { // 如果相等 距离为上一格的距离
dp[i * n + j] = dp[(i - 1) * n + j - 1];
} else { // 如果不等,去插入删除和交换的最小距离
dp[i * n + j] = 1 + min({dp[i * n + j - 1], dp[(i - 1) * n + j], dp[(i - 1) * n + j - 1]});
}
}
}
int result = dp[m * n - 1];
free(dp); // 释放空间
return result;
}
作者:我是一只程序⚪