中国大学排名
v1.0
作者:喝醉酒的小白
import requests
import bs4
from bs4 import BeautifulSoup
# 获取大学排名网页内容
def getHTMLText(url):
try:
headers = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, timeout=30, headers=headers) #请求URL超时,产生超时异常
r.raise_for_status() #如果转态不是200,引发HTTPError错误
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 提取信息到合适的数据结构
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string])
# 利用数据结构数据展示并输出结果
def printUnivList(ulist, num):
# tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}\t{3:^10}"
# print(tplt.format("排名", "学校名称", "省份", "总分", chr(12288))) #采用中文字符的空格填空 chr(12288)
# for i in range(num):
# u = ulist[i]
# print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
tplt = "{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}"
print(tplt.format("排名", "学校名称", "省份", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
# 主函数
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 10) #10 univs
main()

import requests
import bs4
from bs4 import BeautifulSoup
# 获取大学排名网页内容
def getHTMLText(url):
try:
headers = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, timeout=30, headers=headers) #请求URL超时,产生超时异常
r.raise_for_status() #如果转态不是200,引发HTTPError错误
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 提取信息到合适的数据结构
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string])
# 利用数据结构数据展示并输出结果
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}"
print(tplt.format("排名", "学校名称", "省份", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
# 保存数据
def saveUnivList(ulist, num):
import pandas as pd
for i in range(num):
u = ulist[i]
# print(u)
df = pd.DataFrame([u]) # [u]
try:
df.to_csv("univRangking.csv", mode="a+", header=None, index=None, encoding="gbk")
# print("成功")
except:
print("当前行数据写入失败")
# 主函数
def main():
uinfo = []
url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html"
html = getHTMLText(url)
fillUnivList(uinfo, html)
# printUnivList(uinfo, 10) #10 univs
saveUnivList(uinfo, 300) #前三百
main()
读取数据
df = pd.read_csv("univRangking.csv", engine="python", header=None, encoding="gbk")
df.columns = ["排名", "学校名称", "省份", "总分"]
df
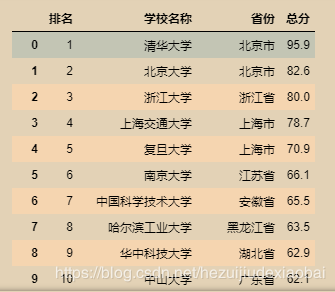
爬取中国大学排名并以csv格式存储
import requests
import bs4
from bs4 import BeautifulSoup
# 获取大学排名网页内容
def getHTMLText(url):
try:
headers = {'user-agent': 'Mozilla/5.0'}
r = requests.get(url, timeout=30, headers=headers) #请求URL超时,产生超时异常
r.raise_for_status() #如果转态不是200,引发HTTPError错误
r.encoding = r.apparent_encoding
return r.text
except:
return ""
# 提取信息到合适的数据结构
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string])
# 利用数据结构数据展示并输出结果
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{4}^10}\t{2:^10}\t{3:^10}"
print(tplt.format("排名", "学校名称", "省份", "总分", chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0], u[1], u[2], u[3], chr(12288)))
# 保存数据
def saveUnivList(ulist, num, year):
import pandas as pd
for i in range(num):
u = ulist[i]
# print(u)
df = pd.DataFrame([u]) # [u]
try:
df.to_csv("univRangking-%s.csv"%(year), mode="a+", header=None, index=None, encoding="gbk")
# print("成功")
except:
print("当前行数据写入失败")
# 主函数
def main():
year = int(input("爬取的年份:"))
url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming%s.html" %(year)
uinfo = []
html = getHTMLText(url)
fillUnivList(uinfo, html)
saveUnivList(uinfo, 300, year) #前三百
main()

作者:喝醉酒的小白