文本情感分析:去停用词
原文地址
分类目录——情感识别
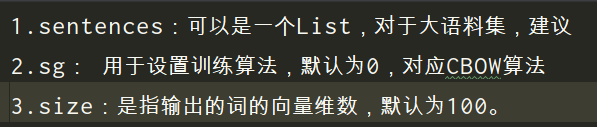
随便构造了一份测试数据如下,内容是gensim下的词向量生成模型word2vec的属性说明
import re
# 通过正则表达式筛除string中的标点符号
def clearn_str(string):
# 筛除掉中文标点
string = re.sub(r'["#$%&'()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、 、〃〈〉《》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏﹑﹔·!?。。 ]', '', string)
# 筛除掉英文标点
string = re.sub(r'[!"#$%&\'()*+,-./:;?@[\]^_`{|}~]', '', string)
return string
# 读取一份测试文件
with open('data.txt', encoding='utf8') as f:
sentenceslist = f.read().splitlines() # 每行作为一个元素封装成列表
# ['1.sentences:可以是一个List,对于大语料集,建议', '2.sg: 用于设置训练算法,默认为0,对应CBOW算法', '3.size:是指输出的词的向量维数,默认为100。']
preprocessed = [clearn_str(x) for x in sentenceslist]
# ['1sentences可以是一个List对于大语料集建议', '2sg用于设置训练算法默认为0对应CBOW算法', '3size是指输出的词的向量维数默认为100']
一种方式,分词之后去掉词列表中的停用词
对于一份停用词列表,在nltk模块包下封装了英文的停用词表,我从网上找了一份中文的,大概是这样的
链接:https://pan.baidu.com/s/1shrhd-Kg9U1n9WXSOFdwow
提取码:q3me
from nltk.corpus import stopwords
import jieba
# 从nltk中获取英文停用词
stopwords1 = stopwords.words('english')
# ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', ...]
#
with open('../data/stopwords.txt', encoding='utf8') as f:
stopwords2 = f.read().splitlines()
# 读取一份测试文件
with open('data.txt', encoding='utf8') as f:
sentenceslist = f.read().splitlines() # 每行作为一个元素封装成列表
# ['1.sentences:可以是一个List,对于大语料集,建议', '2.sg: 用于设置训练算法,默认为0,对应CBOW算法', '3.size:是指输出的词的向量维数,默认为100。']
res = [list(jieba.cut(sent)) for sent in sentenceslist] # 用jieba分词
# [['1', '.', 'sentences', ':', '可以', '是', '一个', 'List', ',', '对于', '大', '语料', '集', ',', '建议'], ['2', '.', 'sg', ':', ' ', '用于', '设置', '训练', '算法', ',', '默认', '为', '0', ',', '对应', 'CBOW', '算法'], ['3', '.', 'size', ':', '是', '指', '输出', '的', '词', '的', '向量', '维数', ',', '默认', '为', '100', '。']]
# 去停用词
for line in res:
for cell in line[:]: # line[:],深copy,避免因为循环删除跳过对某些想的筛选
if cell in stopwords2:
line.remove(cell)
# [['sentences', 'List', '语料', '集', '建议'], ['sg', ' ', '用于', '设置', '训练', '算法', '默认', 'CBOW', '算法'], ['size', '指', '输出', '词', '向量', '维数', '默认', '100']]
作者:BBJG_001