【Python数据分析】文本情感分析——电影评论分析(一)
情感分析是文本分析的一种,它能够从一段文本描述中理解文本的感情色彩,是褒义、贬义还是中性。常见的情感分析的使用场景就是客户对商品或服务的评价、反馈,传统模式下的人工审核,不仅消耗大量人力,而且效率(速度和准确度)也不高。
这里使用Python对电影《哪吒之魔童降世》的评论进行文本分析,这种分析方式还可用于垃圾邮件的过滤、新闻的分类等场景。
分析步骤:
1、对文本数据进行预处理,包括文本缺失值重复值处理、分词、去除停用词、文本向量化。
2、描述性统计分析,统计词频、生成词云图。
3、验证性统计分析,通过方差分析进行特征选择。
4、统计建模,根据文本向量进行文本分类。
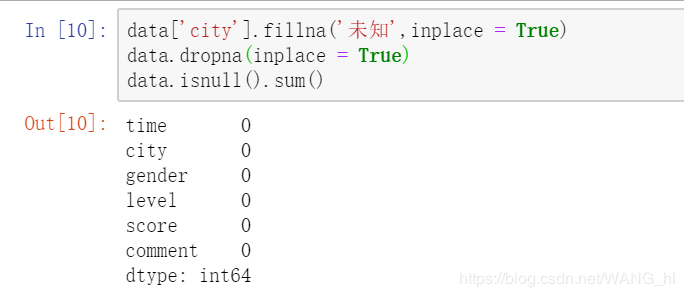
1、检查缺失值。
#查看每一列的缺失值
data.isnull().sum()

2、填充缺失值。
#填充缺失值
data['city'].fillna('未知',inplace = True)
data.dropna(inplace = True)
data.isnull().sum()
重复数据对文本分析和建模没有帮助,直接删去。
#删除重复记录
data.drop_duplicates(inplace=True)
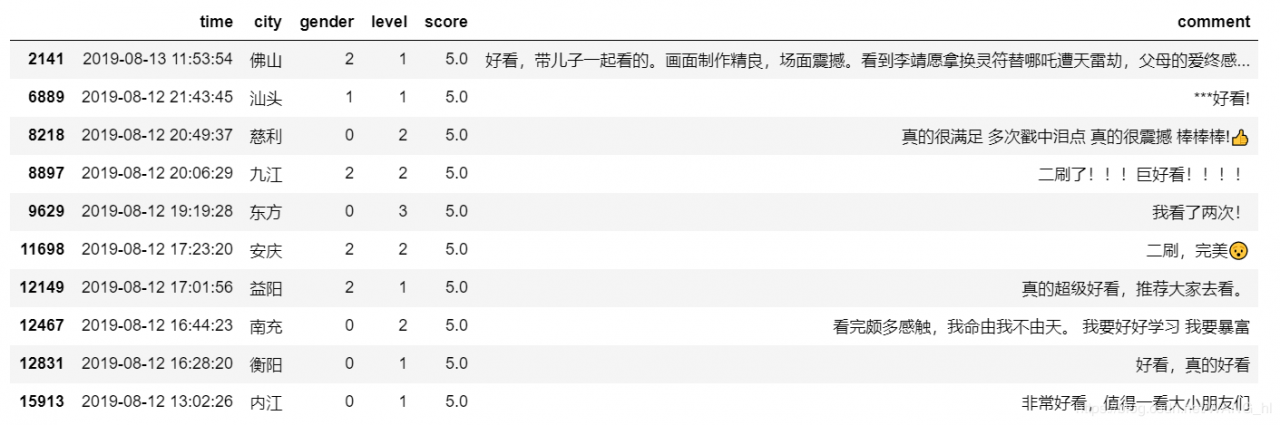
文本内容清理
文中的表达符号、特殊字符,通常对文本分析的作用不大,删除。删除文本中的指定字符用正则匹配的方式。
清洗前:
#文本内容清洗,清楚特殊符号,用正则表达式
import re
pattern = r"[!\"#$%&'()*+,-./:;?@[\\\]^_^{|}~—!,。?、¥…():【】《》‘’“”\s]+"
re_obj = re.compile(pattern)
#方案A:
def clear(text):
return re.sub(pattern,"",text)
#方案B:
def clear(text):
return re_obj.sub("",text)
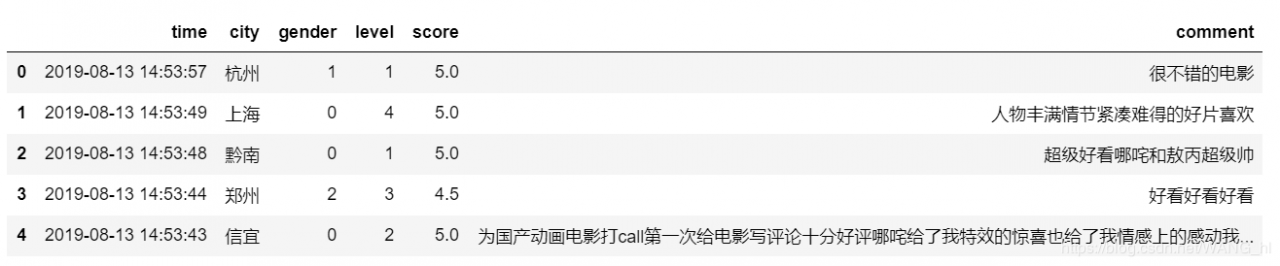
data['comment'] = data['comment'].apply(clear)
data.head()
A、B方案都是可以的,但方案B更优
原因:A方案是直接调用正则表达式的模块来实现,B方案是先建立一个正则表达式的对象,通过对象进行模式匹配,两种实现方式都能满足需求,B方案更好,因为A方案在内部也是先创建一个正则表达式进行匹配,在实现时就会频繁的调用apply,因为data[‘comment’]有很多记录,而每条记录都会调用clear方法一次,这样就会频繁创建正则表达式的对象,而B方案不会频繁创建正则表达式对象,所以B方案执行效率更高。
清洗后:
分词,是将连续的文本分割成语义合理的若干词汇序列。对英文来讲分词很容易,但是中文的分词就有难度了,但是Python有强大的工具包,这里用jieba来实现分词。
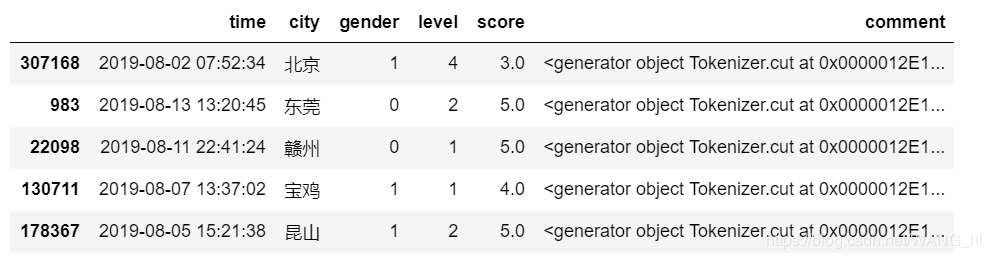
import jieba
#方案A:返回生成器
def cut_word(text):
return jieba.cut(text)
#方案B:返回列表
def cut_word(text):
return jieba.lcut(text)
data['comment'] = data['comment'].apply(cut_word)
A、B方案都是可以的,但方案A更优
原因:
生成器不占用空间,如果现在就返回list列表,而数据记录又很多,这下存储这些list就会占用很大空间,后面还要处理停用词,会剔除停用词,没必要为这些迟早会被剔除的词提前分配空间,所以没必要过早的去占用这些空间。所以这里选用生成器,需要的时候再一点点迭代展开,没必要一下就释放展开。
停用词就是在语句中大量出现,但在语义分析时并没帮助的词,比如‘了’、‘的’、‘虽然’、‘无论’等等,这些词删掉了既可以减少存储空间消耗又可以减少计算时间消耗,何乐而不呢,所以直接删掉。
#方案A:使用set
def get_stopword():
s = set()
with open('D:\stopword.txt',encoding = 'UTF-8') as f:
for line in f:
s.add(line.strip())
return s
#方案B:使用list
def get_stopword():
s = list()
with open('D:\stopword.txt',encoding = 'UTF-8') as f:
for line in f:
s.append(line.strip())
return s
def remove_stopword(words):
return [word for word in words if word not in stopword]
stopword = get_stopword()
data['comment'] = data['comment'].apply(remove_stopword)
A、B方案都是可以的,但方案A更优
原因:
set()查找速度比list()快,list()的查找需要遍历全部,其时间复杂度是o(n),而set()查找的时间复杂度是o(1),因为set()中的元素是使用哈希码来映射的,相同的元素有相同的哈希码,相同的哈希码映射到同一个位置。
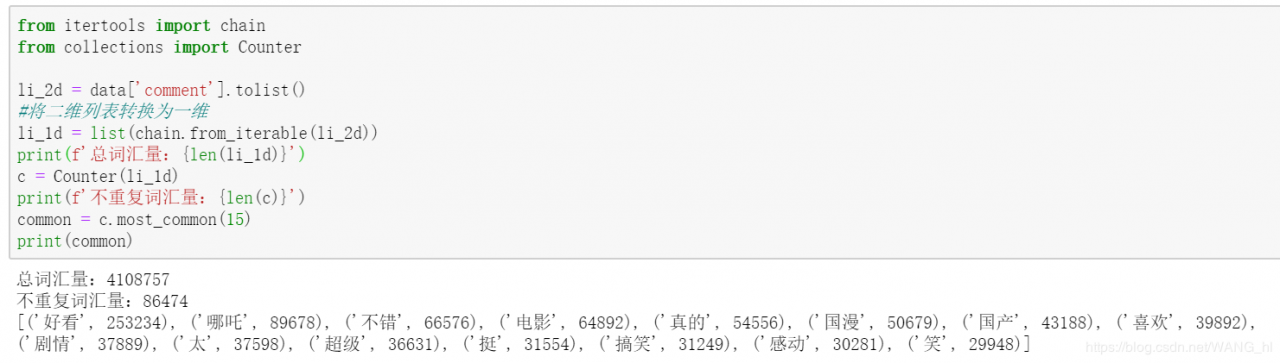
统计出现频率最多的15个词汇
from itertools import chain
from collections import Counter
li_2d = data['comment'].tolist()
#将二维列表转换为一维
li_1d = list(chain.from_iterable(li_2d))
print(f'总词汇量:{len(li_1d)}')
c = Counter(li_1d)
print(f'不重复词汇量:{len(c)}')
common = c.most_common(15)
print(common)
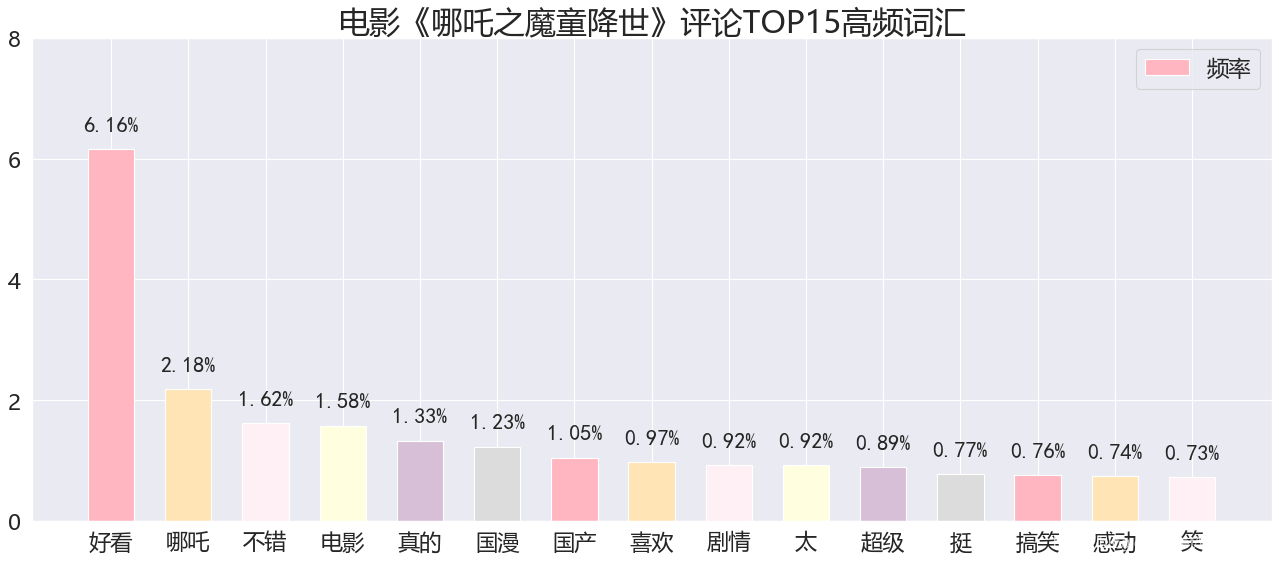
频数可视化:

转换成频率
#计算每个评论的用词数
num = [len(li) for li in li_2d]
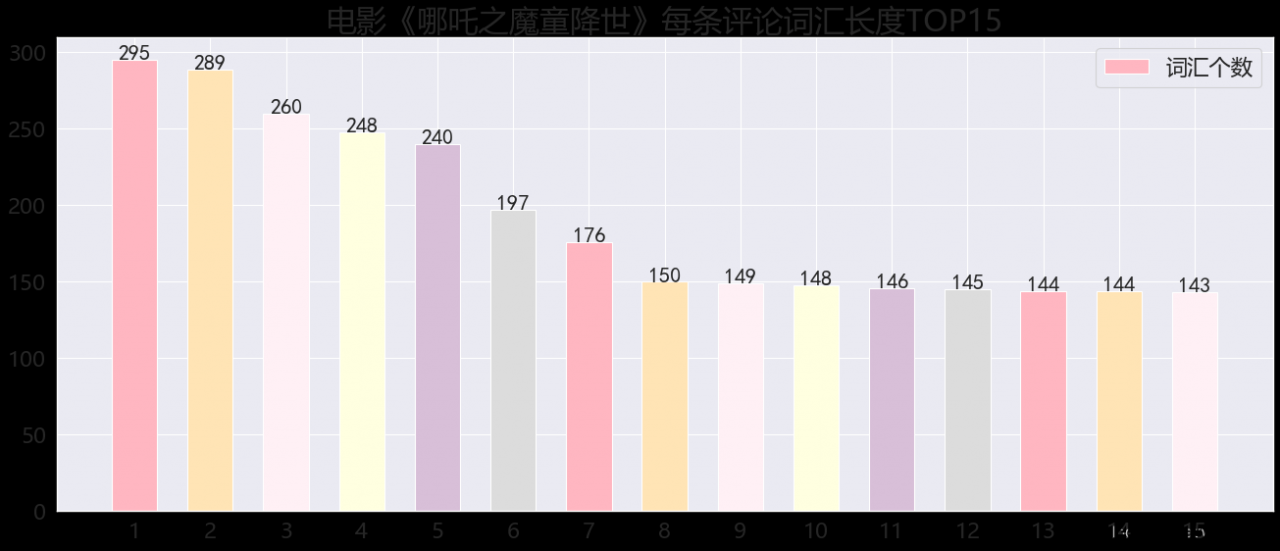
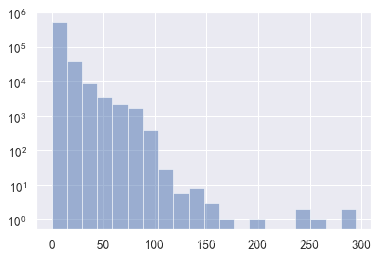
评论词汇长度统计
绘制所有用户在评论时所用词汇书,绘制直方图。
n, bins, patches = plt.hist(num,bins=20, alpha=0.5)
plt.yscale('log')
plt.show()
from wordcloud import WordCloud
wc = WordCloud(font_path=r'C:\Windows\Fonts\STKAITI.TTF',mask=plt.imread('D:\哪吒.jfif'))
img = wc.generate_from_frequencies(c)
plt.figure(figsize=(15,10))
plt.imshow(img)
plt.axis('off')

作者:紫雪凝香