ES使用热词 停用词注意事项
在使用elasticsearch进行搜索业务的时候,发现一篇和搜索关键字完全不匹配的文章排在最前面.打开它发现原来是这篇文章含有非常多的"的"这个无意义的词.而我的搜索关键字假设为"历史上的
今天",它可能就被ik_max_word分词后,刚好就有"的"这个词.所以会造成一篇含有很多"的"的文章,即使跟搜索关键字无关,也可能得分很高,排在前面.
那么我们需要做的就是如何对这些无意义的词——停用词进行屏蔽.
解决方案其实这个问题很好解决,如果你使用ik分词器,其实都为你解决了.但是它默认设置的停用词都是英文的,比如AND,OR等等
那么在哪里配置呢?找到你的es安装插件的文件夹,进入ik分词器的配置文件中,比如我的是
elasticsearch-xxx\plugins\ik\config
打开它发现会有stopword.dic和extra_stopword.dic
打开会发现stopword.dic里面的都为配置的英文停用词,而extra_stopword.dic里面的都为配置的中文停用词
但是我发现在extra_stopword.dic中是有"的"啊.怎么没有效果呢?
原来我们还需要在IKAnalyzer.cfg.xml中进行配置
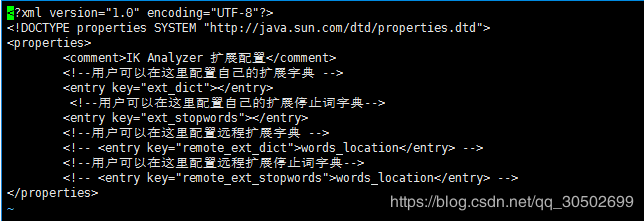
如此便配置好了
我们再次搜索就会惊喜的发现,那篇含有无意义的词的文章便搜索不到了.
更新停用词注意事项想要更新分析器的停用词列表有多种方式, 分析器在创建索引时,当集群节点重启时候,或者关闭的索引重新打开的时候。
如果你使用 stopwords 参数以内联方式指定停用词,那么你只能通过关闭索引,更新分析器的配置update index settings API,然后在重新打开索引才能更新停用词。
如果你使用 stopwords_path 参数指定停用词的文件路径 ,那么更新停用词就简单了。你只需更新文件(在每一个集群节点上),然后通过两者之中的任何一个操作来强制重新创建分析器:
关闭和重新打开索引 (参考 索引的开与关),
一一重启集群下的每个节点。
当然,更新的停用词不会改变任何已经存在的索引。这些停用词的只适用于新的搜索或更新文档。如果要改变现有的文档,则需要重新索引数据。参加 重新索引你的数据 。
作者:qq_30502699