逻辑回归(Logistic Regression)
首先,逻辑回归的输出值只有两个,通常记为0和1 ,因而逻辑回归又是一种分类算法。
其次,逻辑回归有一个广义的线性模型。线性模型通常记为
 逻辑回归的模型为 :
逻辑回归的模型为 :
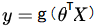
这里的g通常取如下形式:g(x) = 1/(1+exp(-x)) 。当x–>正无穷时,g(x)–>1, 当x–>负无穷时,g(x)–>0 。
于是逻辑回归的模型函数为:
![]()
 是输入的特征值向量,
是输入的特征值向量,
 是模型参数向量。当
是模型参数向量。当
>0.5时,模型输出值为1 ,当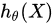
<0.5时,模型输出值为0 。
最后,说一下 LogisticRegression的用法和参数:
LogisticRegression是一个类,定义在 Sklearn.linear_model模块中,使用时先引入该模块。之后,实例化一个对象,并且训练它。训练之后的实例就可以拿来做预测了。代码如下:
#coding:utf-8
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
iris = load_iris() #使用sklearn 自带的鸢尾花数据
X = iris.data[:, 2:]
y = iris.target
y_idx = ((y==0) | (y==1)) #取setosa 和 versicolor
X = X[y_idx]
y = y[y_idx]
lg_reg = LogisticRegression()
lg_reg.fit(X,y)
y_pred = lg_reg.predict([[2.3,1.5]]) #[2.3,1.5]是构造的测试数据
print(y_pred)
输出结果:[0]
参数:
1、penalty参数可选择的值为"l1"和"l2".分别对应L1的正则化和L2的正则化,默认是L2的正则化。如果我们主要的目的是解决过度拟合,选L2正则化就够了。但是如果选择L2正则化发现还是过度拟合,即预测效果差,这时选择L1正则化。其次,如果模型的特征非常多,希望一些不重要的特征系数归零,可以选择L1正则化。
2、solver,损失函数优化算法的选择:如果penalty=L2, solver可以为{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}其中任一个,如果penalty=L1,solver只能选liblinear 。
3、multi_class,ovr和multinomial是可选项
4、class_weight 类权重参数
5、sample_weight 样本权重参数
2、3、4、5,这些参数的具体含义,详细参阅官方文档。
作者:C/C++/C#/Pathon