零基础/小白/python萌新也能学 爬取静态网页信息并解析后存储在excel中/爬虫
下面是笔者的一段废话 嘿嘿。
记得我才开始接触python的时候,天天听网上这个公开课那个公开课让报班学爬虫,说爬虫有多赚钱多厉害(但是他们的课贵啊QAQ)。我那时候就想不掏钱自己学,折腾了一段时间,也有一些小的经验。当时我学的时候就经常会面临看代码一脸懵逼的状态,于是今天就像做一个简单的爬虫并且具体解释一下代码,看完应该就能学会。做一个萌新友好型文章
( ̄▽ ̄)~*
import urllib.request,re #urllib 包 re正则表达式python3自带包不需要导入 urlib.request模块 re正则表达式
import xlwt #需要PIP安装导入包
'''def getdata():#请求网页内容 拿到静态网站源代码 函数不调用就无法print出数据 原始版本是这样
url = 'http://www.risfond.com/case/fmcg/47977'
html = urllib.request.urlopen(url).read()
print(html)'''
def getdata():#请求网页内容 拿到静态网站源代码 我想一次获得多个网页 就将47977改为变量 并进行字符串格式化 % format都是可以字符串格式化的
url_list = []
for i in range(47977,47997):
url = 'http://www.risfond.com/case/fmcg/{}'.format(i) #字符串格式化.format
html = urllib.request.urlopen(url).read().decode('utf-8')
print(html)
#接下来用正则表达式解析源代码
page_list = re.findall(r'.*?:(.*?)',html)#html表示源码
print(page_list)
url_list.append(page_list)
return url_list
#存储数据 excel. 创建excel 数据的存储
#创建excel表格
def excel_write(items):#将上一个函数的数据进行一个传递
newTable = 'text2020.xls'
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('sheet1')#保存这个表格 实际是保存wb
headData = ['职位名称', '职位低点', '时间', '行业','招聘时间','人数','顾问']
for colnum in range(0,7):
ws.write(0,colnum,headData[colnum],xlwt.easyxf('font:bold on'))# 0代表第一列 colnum代表有七列数据 headData【colnum】列表取值效果字体加粗
index = 1
for j in range(0,len(items)):#len计算长度
for i in range(0,7): #往sheet1写入
ws.write(index,i,items[j][i])#j行i列
index +=1
wb.save(newTable)
items = getdata()
excel_write(items)
写一个爬虫的基本思路
对网站发起请求,获取网页源代码
通过一定手段解析网站(获取你所需的)
保存到你的电脑上(本文是保存到excel)
数据分析(发挥数据价值)
环境与包的准备
(看到这里我就默认你安装过python3.X了嘿嘿)如果你的电脑没有xlwt包,那么打开命令行(windows用户) 输入:pip install xlwt
import urllib.request,re#这两个都是自带的包 是urlllib.request模块和 re正则表达式
import xlwt #需pip一下
请求网页内容
请求网页内容拿到静态网站源码(这次爬取的网站是个难度低的猎头网站 网址:http://www.risfond.com/case/fmcg/47977)
def getdata():#请求网页内容 拿到静态网站源代码/ 原始版本是这样
url = 'http://www.risfond.com/case/fmcg/47977'
html = urllib.request.urlopen(url).read()
print(html)
url是统一资源定位符,我们将网站的网址填入即可,然后利用urllib.request.urlopen(url).read()读取并将源码存储在变量html,但是很明显这样一个一个网页爬取效率太低,我们就像一次爬取多个网站。于是便做了如下优化
请求网页内容(优化)首先我们发现这个猎头公司的职务和人员介绍页面,每点击一次下一条网址的最后一个数字就+1,每点一次上一条网址的最后一个数字就-1.(说明它不反爬)。也就是说如果我们要批量获取网页信息只要让末尾数字变化就行了。
def getdata():#请求网页内容 拿到静态网站源代码 我想一次获得多个网页 就将47977改为变量 并进行字符串格式化 % format都是可以字符串格式化的
url_list = []
for i in range(47977,47997):
url = 'http://www.risfond.com/case/fmcg/{}'.format(i) #字符串格式化.format
html = urllib.
我们采用 for循环一次性获取了而是个网页,但有一点要注意在url中我们不能直接就把原来那个数字的位置改成i,而是要把字符串格式化,例子里使用的是format的格式化方法,同样的%也可以实现格式化功能。这样我们就实现了批量获取网页。(这些网页是猎头公司不同岗位和人员的信息并非是无意义网页)
使用正则表达式解析源代码现在我们补写这个函数,把获取的网页解析只拿我们想要的
def getdata():#请求网页内容 拿到静态网站源代码 我想一次获得多个网页 就将47977改为变量 并进行字符串格式化 % format都是可以字符串格式化的
url_list = []
for i in range(47977,47997):
url = 'http://www.risfond.com/case/fmcg/{}'.format(i) #字符串格式化.format
html = urllib.request.urlopen(url).read().decode('utf-8')
print(html)
#接下来用正则表达式解析源代码
page_list = re.findall(r'.*?:(.*?)',html)#html表示源码因为我们前面用html当了变量存储了网页源代码
print(page_list)
url_list.append(page_list)
return url_list
下面我们开始对解析部分源码逐行解释,利用re.findall方法 我们开始解析代码,我们只需要我们想要的信息,这个例子中我们想要提取的是职位名称,职位地点 时间 行业 招聘时间 人数 顾问 的信息 而这些信息都在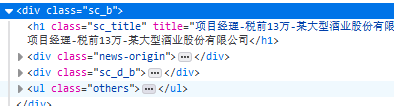 所以我们复制第一个标签`
所以我们复制第一个标签`
职位名称:项目经理(13万)
然后我们删除汉字部分只留下代码 在用正则表达式进行匹配贪婪匹配。就成了这样也就是
> page_list = re.findall(r'.*?: class="sc_d_con">(.*?)',html)#html表示源码
这就完成了对源码的解析
存数据入excel
```python
#存储数据 excel. 创建excel 数据的存储
#创建excel表格
items = getdata()
def excel_write(items):#将上一个函数的数据进行一个传递
newTable = 'text2020.xls'
wb = xlwt.Workbook(encoding='utf-8')
ws = wb.add_sheet('sheet1')#保存这个表格 实际是保存wb
headData = ['职位名称', '职位低点', '时间', '行业','招聘时间','人数','顾问']
for colnum in range(0,7):
ws.write(0,colnum,headData[colnum],xlwt.easyxf('font:bold on'))# 0代表第一列 colnum代表有七列数据 headData【colnum】列表取值效果字体加粗
index = 1
for j in range(0,len(items)):#len计算长度
for i in range(0,7): #往sheet1写入
ws.write(index,i,items[j][i])#j行i列
index +=1
wb.save(newTable)
我们创建了一个新函数,并把上面的数据传入这个函数,然后我们开始创建excel,首先对其命名为text2020,然后我们创建了一个Workbook采用utf-8编码方式并命名为wb,之后我们让将wb的第一个表格(sheet1)命名成ws之后我们将数据写入第一个sheet中,然后我们将表的各个模块名称写入headData。
for colnum in range(0,7):
ws.write(0,colnum,headData[colnum],xlwt.easyxf('font:bold on'))# 0代表第一列 colnum代表有七列数据 headData【colnum】列表取值效果字体加粗
index = 1
for j in range(0,len(items)):#len计算长度
for i in range(0,7): #往sheet1写入
ws.write(index,i,items[j][i])#j行i列
index +=1
wb.save(newTable)
接下来对这段代码的功能进行讲解,首先第一个for循环我们将headData中的各个模块写入了表头。然后我们利用了后面两个循环实际是将数据分块并分别写入了一个七列和len(items)行的表格中的表格中,这是这一块的功能 。(写入的是sheet1也就是ws)。写入表格之后呢,我们保存一下表格并命名为text2020(因为我们前面让 newTable=‘text2020’了)
到这里我们的两个函数的书写讲完了,写完函数我们一定不能忘记调用啊,就有人写完函数之后直接就run了,run完还来找我问,你看看为什么不行呢…(╬ ̄皿 ̄)下面我们调用函数
items = getdata()
excel_write(items)
好了,看到这里我们这个项目就结束了,在运行之后你的python文件的文件夹里应该会出现一个excel表格内容是这样的: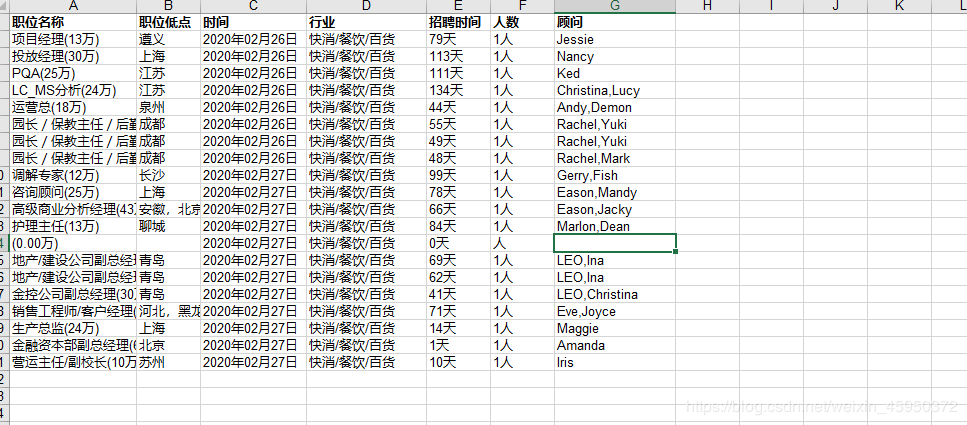 Congratulation ✧。٩(ˊᗜˋ)و✧。
Congratulation ✧。٩(ˊᗜˋ)و✧。
整个项目的源码在开头,我是分开讲的可能看着不方便。另外看完了的各位大爷,能不能赏小的个赞呢ღ( ´・ᴗ・` )。嘿嘿谢谢您。
作者:XContributeX