过拟合、梯度消失、RNN进阶
训练误差:指模型在训练数据集上表现出的误差。
泛化误差:指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似。(ML应关注此项)
如何计算训练误差或者泛化误差,可以用损失函数。【损失函数:均方误差(线性回归)、交叉熵损失函数(softmax回归)】
验证集的作用:进行模型选择。
K折交叉验证:由于验证数据集不参与模型训练,当训练数据不够用时,预留大量的验证数据显得太奢侈。一种改善的方法是K折交叉验证(K-fold cross-validation)。在K折交叉验证中,我们把原始训练数据集分割成K个不重合的子数据集,然后我们做K次模型训练和验证。每一次,我们使用一个子数据集验证模型,并使用其他K-1个子数据集来训练模型。在这K次训练和验证中,每次用来验证模型的子数据集都不同。最后,我们对这K次训练误差和验证误差分别求平均。
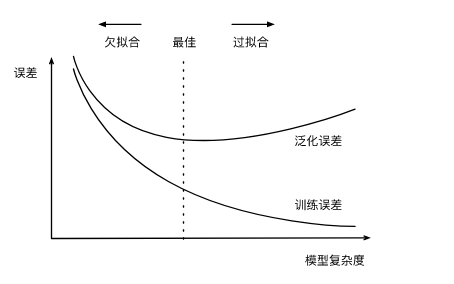
过拟合:模型的训练误差远小于它在测试数据集上的误差。(解决方法:权重衰减、丢弃法)
欠拟合:模型无法得到较低的训练误差。
造成这两种拟合问题的因素有很多,其中两种分别是:模型复杂度和训练数据集大小。
权重衰减:等价于L2范数正则化。(应对过拟合的手段)
L2范数惩罚项指的是模型权重参数每个元素的平方和与一个正的常数的乘积。
权重衰减通过惩罚绝对值较大的模型参数为需要学习的模型增加了限制。
二、梯度消失、梯度爆炸当神经网络的层数较多时,模型的数值稳定性容易变差。
随机初始化模型参数:
为什么在神经网络中通常需要随机初始化模型参数?
假设输出层只保留一个输出单元o1(删去o2和o3以及指向它们的箭头),且隐藏层使用相同的激活函数。如果将每个隐藏单元的参数都初始化为相等的值,那么在正向传播时每个隐藏单元将根据相同的输入计算出相同的值,并传递至输出层。在反向传播中,每个隐藏单元的参数梯度值相等。因此,这些参数在使用基于梯度的优化算法迭代后值依然相等。之后的迭代也是如此。在这种情况下,无论隐藏单元有多少,隐藏层本质上只有1个隐藏单元在发挥作用。因此,正如在前面的实验中所做的那样,我们通常将神经网络的模型参数,特别是权重参数,进行随机初始化。
环境因素:协变量偏移、标签偏移、概念偏移。
三、RNN进阶RNN:
RNN存在的问题:梯度较容易出现衰减或爆炸(BPTT)。
⻔控循环神经⽹络:捕捉时间序列中时间步距离较⼤的依赖关系。

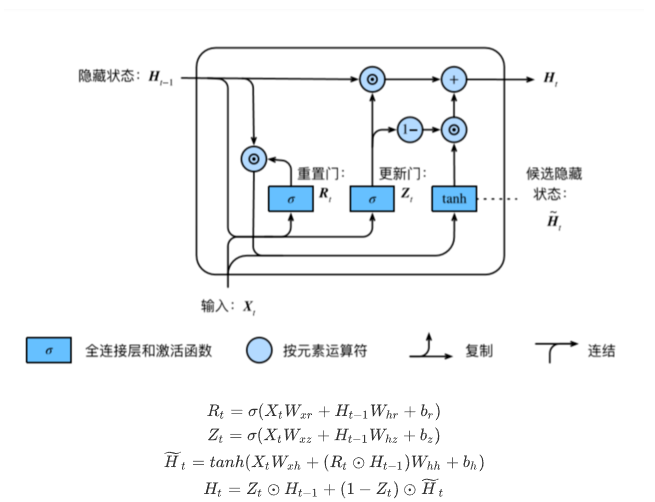
GRU:
重置⻔有助于捕捉时间序列⾥短期的依赖关系;
更新⻔有助于捕捉时间序列⾥⻓期的依赖关系。
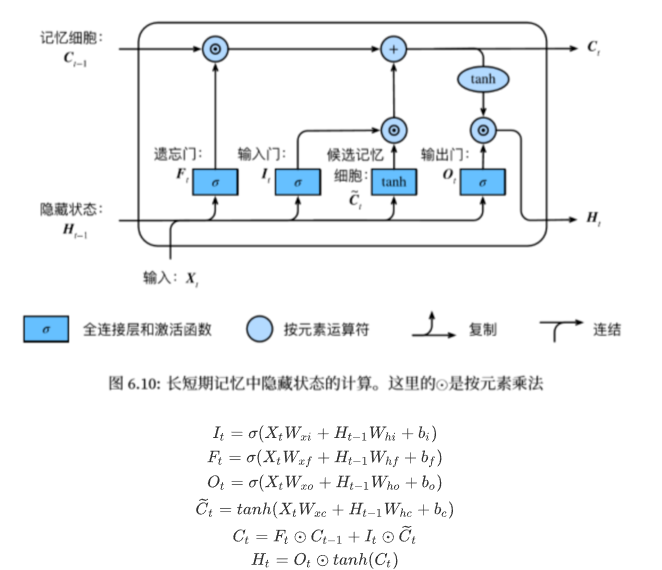
LSTM:
遗忘门:控制上一时间步的记忆细胞;
输入门:控制当前时间步的输入;
输出门:控制从记忆细胞到隐藏状态;
记忆细胞:⼀种特殊的隐藏状态的信息的流动 。
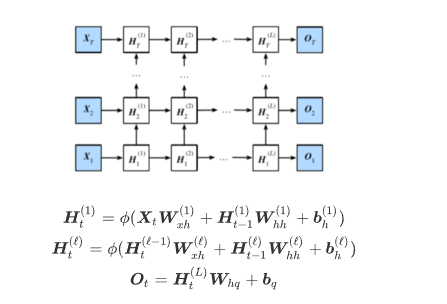
深度循环神经网络:
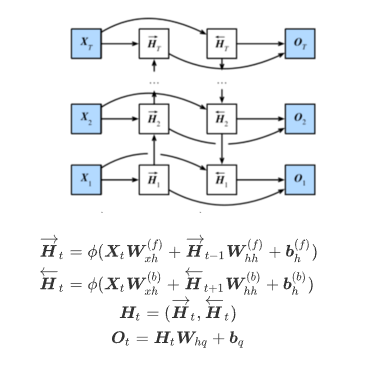
双向循环神经网络:
作者:Phtomhive