Fast R-CNN论文理解
在之前对目标检测开山论文R-CNN有了理解,接下来我们继续对R-CNN系列中的Fast R-CNN做一个理解。
在此之前,需要了解的是论文方法产生的前提:
Fast R-CNN的产生并不是仅仅直接来源与R-CNN,而是在SPP-NET的基础上对R-CNN的改进。
这里简单介绍一下SPP-NET同时对它和R-CNN的缺点做一个复习。
我们都知道R-CNN的方法是,首先对一张特定尺度的图片通过Search Selective的方法产生2K个区域,然后将这些区域分别输入到CNN当中去,然后将产生特征向量保存到硬盘当中,最后将其输入到SVM分类器当中进行训练并输出。
这里我们很容易就知道它的几个缺点:
(1)训练分为多个阶段。首先要使用search selective算法从输入图像提取约2000个候选区域,其次要训练CNN网络,最后还要训练SVM进行分类、训练bbox回归器进行更为精确的位置定位。
(2)训练需要花费大量的时间和空间。因为是分阶段的,CNN将候选区域的特征提取出来以后要都存入硬盘中,之后取出用于训练SVM和bbox回归器,存储特征需要耗费大量的硬盘空间,而且读写过程会造成时间的损耗。
(3)检测阶段特别耗时。因为检测时也是对带检测图像中的候选区域进行检测,每个候选区域都要进行前向传播,所以检测一张图像特别耗时。
而SPP-NET,SPP是spatial pyramid pooling,即空间金字塔池化。
也就是,它在R-CNN的基础上添加了一个共享池化层。即,在其共享卷积层结束之后,引入了一个SPP层,也就是多个不同大小的池化层相叠加。
总结而言,SPP-NET最大的改变就是**能够一次性的将所有特征向量输入CNN中,而不是在逐一输入,其输入的图片大小也可以是任一尺度的。**当网络输入的是一张任意大小的图片,这个时候我们可以一直进行卷积、池化,直到网络的倒数几层的时候,也就是我们即将与全连接层连接的时候,就要使用金字塔池化,使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的意义(多尺度特征提取出固定大小的特征向量)。
当然它也带来了新的问题:
在fune-tuning阶段不能对SPP层下面所有的卷积层进行后向传播(如下图所示)
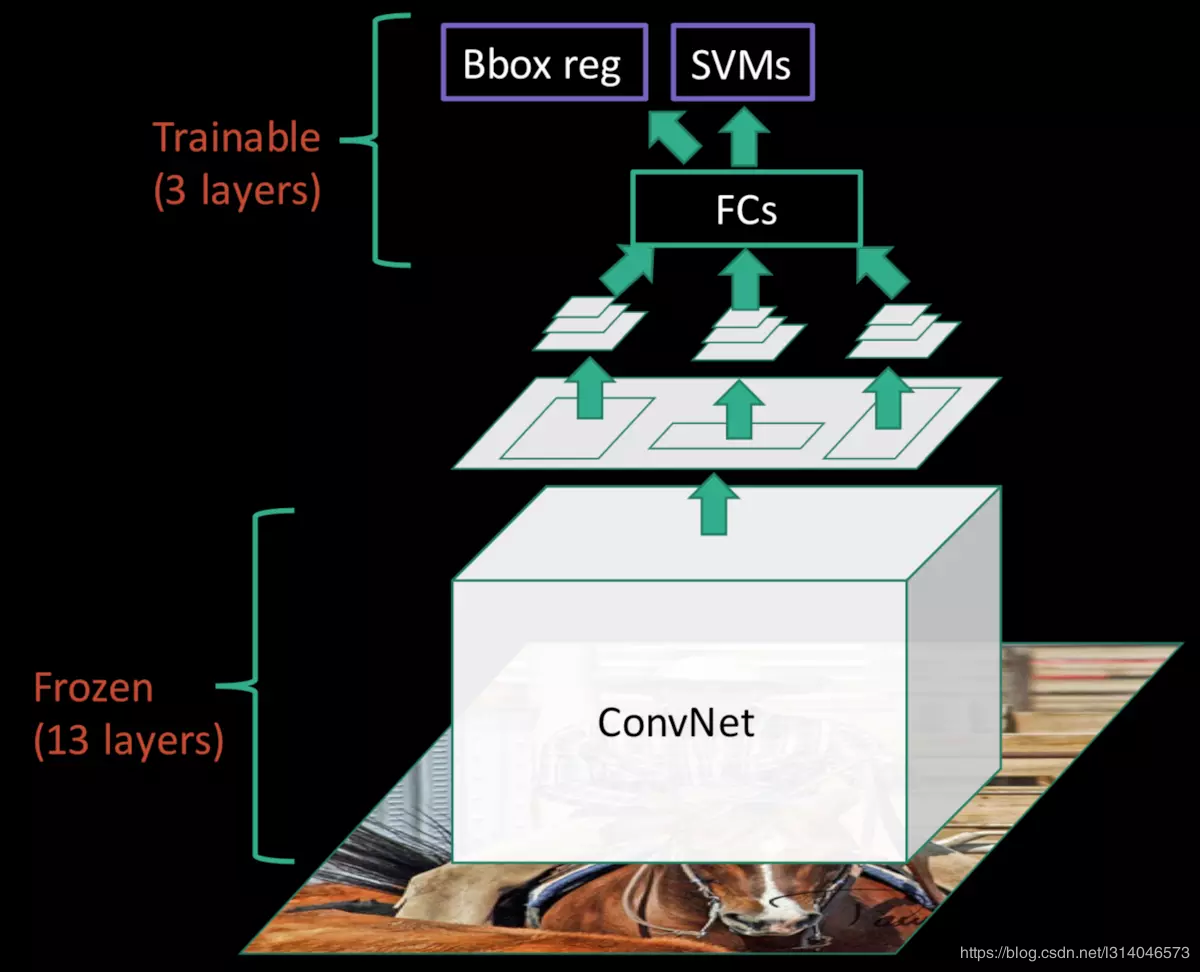
因为在fine-tuning的时候,R-CNN和SPP-net都是取mini-batch为128,其中32个正样本,96个负样本,而这些正负样本通常来自不同的图片。在这样的fine-tuning策略下,当训练样本不是同一个图片的时候,SPP层的更新效率会非常低,效率低的根本原因是每个RoI区域的感受野可能会非常大,从而导致,在一批数据已经训练完之后,下一批数据的训练又要重新计算整张图片的feature map,从而增加了计算量。
针对以上的问题,Fast R-CNN应运而生。
先来看一看Fast R-CNN的系统架构。
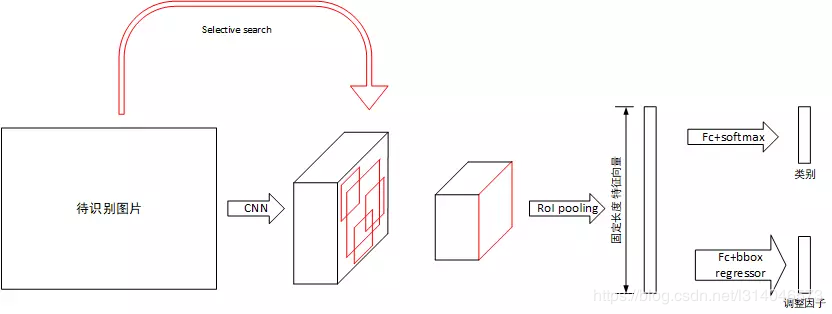
Fast R-CNN对于待识别图片,首先将其使用Selective Search处理获得一系列候选框,随后将其归一化到固定大小,送入CNN网络中提取特征。对于提取出的特征张量,假设其保留了原图片的空间位置信息,将候选框做对应变换后映射到特征张量上,提取出大小不同的候选区域的特征张量。对于每个候选区域的特征张量,使用RoI pooling层将其大小归一化,随后使用全连接层提取固定长度的特征向量。对于该特征向量,分别使用全连接层+softmax和全连接层+回归判断类别并计算当前感兴趣区域的类别及坐标包围框。最后通过NMS得到最后的结果。
需要提到的是,Fast R-CNN和R-CNN相同,都是先用SS算法得到候选框,然后再输入到网络中,这样一来速度是非常慢的,这个也是该论文一直以来的瓶颈。
下面我们分模块来一一理解。
Fast R-CNN的基本网络框架为VGG-16,对于初始网络做了一下调整:
(1)最后一个最大值池化层用RoI池化层代替,该池化层可将不同大小的输入池化为统一大小输出。
(2)最后一层全连接层使用两个分裂的全连接层代替,一个用于计算分类,一个用于计算候选框的调整因子.。
(3)输入改为两个,分别为原图和Selective Search产生的候选框坐标
RoI池化层用于将不同大小的输入张量池化为固定大小。
RoI池化层指定池化窗口的数量为W x H,每个池化窗口的大小是根据池化区域变化的,例如一张图片的尺寸为w x h,则每个窗口的大小为 w/W x h/H,假设W=4,H=4,有以下例子:
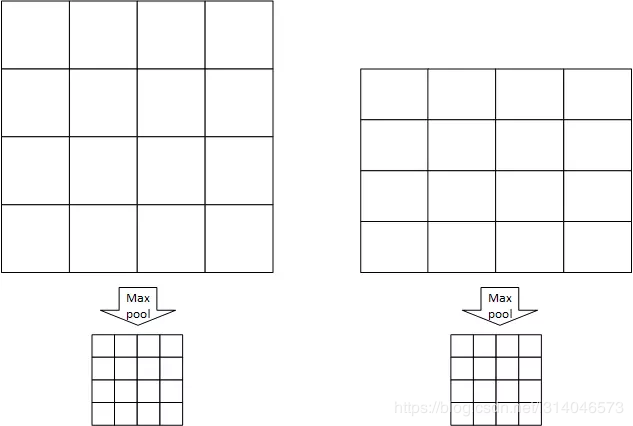
如图左右各有一个大小不同的RoI区域,划分为W x H个池化窗口,每个池化窗口的大小因原RoI区域尺寸不同而不同,经过RoI池化尺寸变为相同的W x H。
模型的训练过程与RCNN不同,Fast-RCNN将分类器和回归器的训练统一到深度学习的框架下,在Selective Search提取出候选区域RoI后,所有的训练均在深度学习框架下进行。(R-CNN则是要分别训练)
批处理训练使用SGD算法,因此需要提取batch进行训练。batch的提取基于N张图片,每个batch共R个数据,每个batch提取R / N个区域。当N较小时,这种提取方法充分的使用了数据局部性,能提高训练速度。在本论文中,有R=128,N=2,即每个batch的数据来自两张图片,共128个RoI数据,其中要求25%的RoI为包含物体的(IoU>0.5),这些RoI被标记为对应类别,剩下的75%的RoI要求IoU在0.1~0.5之间,标记为背景。
多任务损失函数在FC层后接入了两个分支:
一个是softmax用于对每个RoI区域做分类,假如有K类待分(加上背景总共K+1类),输出结果为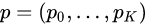
另一个是bbox,用于更精确的定位RoI的区域,输出结果为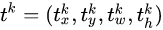
多任务损失函数定义为:
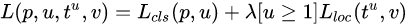
其中,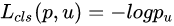
是一个log形式的损失函数,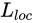 中
中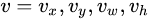 是类别U的真实框的位置,而,
是类别U的真实框的位置,而,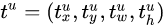 是类别U的预测框的位置。
是类别U的预测框的位置。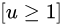 表示当
表示当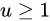 时,该值为1。反之,则为0。实验中,
时,该值为1。反之,则为0。实验中,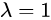 上式中,
上式中, 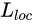 定义为:
定义为: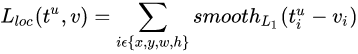 其中,
其中,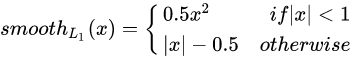
文中认为,L1 对于噪点相比于 L2更不敏感,所以使用L1正则是的模型更为鲁棒。
这里简单来介绍一下Fast R-CNN的训练过程。
1、获取预训练模型。
2、取N=2张图片前向传播,按批处理部分所述进行前向传播,并计算代价函数。
3、根据代价函数反向传播更新权值跳转到2。
其中,RoI pooling层的反向传播与Pooling层相同,不同RoI的反向传播结果对应位置相加后再反向传播到前一层。为了达成尺寸不变性,还在训练中使用了图像金字塔和数据增强的方法。
作者:年轻无极限zx