PyTorch搭建CNN实现风速预测
数据集
特征构造
一维卷积
数据处理
1.数据预处理
2.数据集构造
CNN模型
1.模型搭建
2.模型训练
3.模型预测及表现
数据集
数据集为Barcelona某段时间内的气象数据,其中包括温度、湿度以及风速等。本文将利用CNN来对风速进行预测。
特征构造对于风速的预测,除了考虑历史风速数据外,还应该充分考虑其余气象因素的影响。因此,我们根据前24个时刻的风速+下一时刻的其余气象数据来预测下一时刻的风速。
一维卷积我们比较熟悉的是CNN处理图像数据时的二维卷积,此时的卷积是一种局部操作,通过一定大小的卷积核作用于局部图像区域获取图像的局部信息。图像中不同数据窗口的数据和卷积核做inner product(内积)的操作叫做卷积,其本质是提纯,即提取图像不同频段的特征。
上面这段话不是很好理解,我们举一个简单例子:
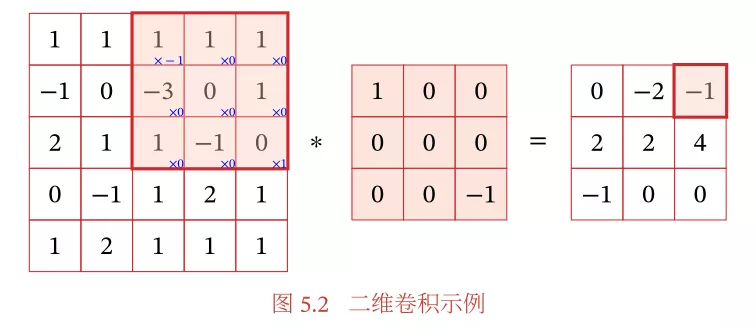
假设最左边的是一个输入图片的某一个通道,为5 × 5 5 \times55×5,中间为一个卷积核的一层,3 × 3 3 \times33×3,我们让卷积核的左上与输入的左上对齐,然后整个卷积核可以往右或者往下移动,假设每次移动一个小方格,那么卷积核实际上走过了一个3 × 3 3 \times33×3的面积,那么具体怎么卷积?比如一开始位于左上角,输入对应为(1, 1, 1;-1, 0, -3;2, 1, 1),而卷积层一直为(1, 0, 0;0, 0, 0;0, 0, -1),让二者做内积运算,即1 * 1+(-1 * 1)= 0,这个0便是结果矩阵的左上角。当卷积核扫过图中阴影部分时,相应的内积为-1,如上图所示。
因此,二维卷积是将一个特征图在width和height两个方向上进行滑动窗口操作,对应位置进行相乘求和。
相比之下,一维卷积通常用于时序预测,一维卷积则只是在width或者height方向上进行滑动窗口并相乘求和。 如下图所示:
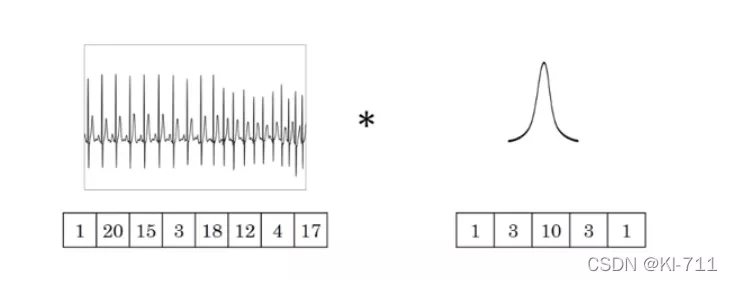
原始时序数为:(1, 20, 15, 3, 18, 12. 4, 17),维度为8。卷积核的维度为5,卷积核为:(1, 3, 10, 3, 1)。那么将卷积核作用与上述原始数据后,数据的维度将变为:8-5+1=4。即卷积核中的五个数先和原始数据中前五个数据做卷积,然后移动,和第二个到第六个数据做卷积,以此类推。
数据处理 1.数据预处理数据预处理阶段,主要将某些列上的文本数据转为数值型数据,同时对原始数据进行归一化处理。文本数据如下所示:

经过转换后,上述各个类别分别被赋予不同的数值,比如"sky is clear"为0,"few clouds"为1。
def load_data():
global Max, Min
df = pd.read_csv('Barcelona/Barcelona.csv')
df.drop_duplicates(subset=[df.columns[0]], inplace=True)
# weather_main
listType = df['weather_main'].unique()
df.fillna(method='ffill', inplace=True)
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_main'] = df['weather_main'].map(dic)
# weather_description
listType = df['weather_description'].unique()
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_description'] = df['weather_description'].map(dic)
# weather_icon
listType = df['weather_icon'].unique()
dic = dict.fromkeys(listType)
for i in range(len(listType)):
dic[listType[i]] = i
df['weather_icon'] = df['weather_icon'].map(dic)
# print(df)
columns = df.columns
Max = np.max(df['wind_speed']) # 归一化
Min = np.min(df['wind_speed'])
for i in range(2, 17):
column = columns[i]
if column == 'wind_speed':
continue
df[column] = df[column].astype('float64')
if len(df[df[column] == 0]) == len(df): # 全0
continue
mx = np.max(df[column])
mn = np.min(df[column])
df[column] = (df[column] - mn) / (mx - mn)
# print(df.isna().sum())
return df
2.数据集构造
利用当前时刻的气象数据和前24个小时的风速数据来预测当前时刻的风速:
def nn_seq():
"""
:param flag:
:param data: 待处理的数据
:return: X和Y两个数据集,X=[当前时刻的year,month, hour, day, lowtemp, hightemp, 前一天当前时刻的负荷以及前23小时负荷]
Y=[当前时刻负荷]
"""
print('处理数据:')
data = load_data()
speed = data['wind_speed']
speed = speed.tolist()
speed = torch.FloatTensor(speed).view(-1)
data = data.values.tolist()
seq = []
for i in range(len(data) - 30):
train_seq = []
train_label = []
for j in range(i, i + 24):
train_seq.append(speed[j])
# 添加温度、湿度、气压等信息
for c in range(2, 7):
train_seq.append(data[i + 24][c])
for c in range(8, 17):
train_seq.append(data[i + 24][c])
train_label.append(speed[i + 24])
train_seq = torch.FloatTensor(train_seq).view(-1)
train_label = torch.FloatTensor(train_label).view(-1)
seq.append((train_seq, train_label))
# print(seq[:5])
Dtr = seq[0:int(len(seq) * 0.5)]
Den = seq[int(len(seq) * 0.50):int(len(seq) * 0.75)]
Dte = seq[int(len(seq) * 0.75):len(seq)]
return Dtr, Den, Dte
任意输出其中一条数据:
(tensor([1.0000e+00, 1.0000e+00, 2.0000e+00, 1.0000e+00, 1.0000e+00, 1.0000e+00,
1.0000e+00, 1.0000e+00, 0.0000e+00, 1.0000e+00, 5.0000e+00, 0.0000e+00,
2.0000e+00, 0.0000e+00, 0.0000e+00, 5.0000e+00, 0.0000e+00, 2.0000e+00,
2.0000e+00, 5.0000e+00, 6.0000e+00, 5.0000e+00, 5.0000e+00, 5.0000e+00,
5.3102e-01, 5.5466e-01, 4.6885e-01, 1.0066e-03, 5.8000e-01, 6.6667e-01,
0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 9.9338e-01, 0.0000e+00,
0.0000e+00, 0.0000e+00]), tensor([5.]))
数据被划分为三部分:Dtr、Den以及Dte,Dtr用作训练集,Dte用作测试集。
CNN模型 1.模型搭建CNN模型搭建如下:
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1d = nn.Conv1d(1, 64, kernel_size=2)
self.relu = nn.ReLU(inplace=True)
self.Linear1 = nn.Linear(64 * 37, 50)
self.Linear2 = nn.Linear(50, 1)
def forward(self, x):
x = self.conv1d(x)
x = self.relu(x)
x = x.view(-1)
x = self.Linear1(x)
x = self.relu(x)
x = self.Linear2(x)
return x
卷积层定义如下:
self.conv1d = nn.Conv1d(1, 64, kernel_size=2)
一维卷积的原始定义为:
nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
这里channel的概念相当于自然语言处理中的embedding,这里输入通道数为1,表示每一个风速数据的向量维度大小为1,输出channel设置为64,卷积核大小为2。
原数数据的维度为38,即前24小时风速+14种气象数据。卷积核大小为2,根据前文公式,原始时序数据经过卷积后维度为:
38 - 2 + 1 = 37
一维卷积后是一个ReLU激活函数:
self.relu = nn.ReLU(inplace=True)
接下来是两个全连接层:
self.Linear1 = nn.Linear(64 * 37, 50)
self.Linear2 = nn.Linear(50, 1)
最后输出维度为1,即我们需要预测的风速。
2.模型训练def CNN_train():
Dtr, Den, Dte = nn_seq()
print(Dte[0])
epochs = 100
model = CNN().to(device)
loss_function = nn.MSELoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 训练
print(len(Dtr))
Dtr = Dtr[0:5000]
for epoch in range(epochs):
cnt = 0
for seq, y_train in Dtr:
cnt = cnt + 1
seq, y_train = seq.to(device), y_train.to(device)
# print(seq.size())
# print(y_train.size())
# 每次更新参数前都梯度归零和初始化
optimizer.zero_grad()
# 注意这里要对样本进行reshape,
# 转换成conv1d的input size(batch size, channel, series length)
y_pred = model(seq.reshape(1, 1, -1))
loss = loss_function(y_pred, y_train)
loss.backward()
optimizer.step()
if cnt % 500 == 0:
print(f'epoch: {epoch:3} loss: {loss.item():10.8f}')
print(f'epoch: {epoch:3} loss: {loss.item():10.10f}')
state = {'model': model.state_dict(), 'optimizer': optimizer.state_dict()}
torch.save(state, 'Barcelona' + CNN_PATH)
一共训练100轮:
def CNN_predict(cnn, test_seq):
pred = []
for seq, labels in test_seq:
seq = seq.to(device)
with torch.no_grad():
pred.append(cnn(seq.reshape(1, 1, -1)).item())
pred = np.array([pred])
return pred
测试:
def test():
Dtr, Den, Dte = nn_seq()
cnn = CNN().to(device)
cnn.load_state_dict(torch.load('Barcelona' + CNN_PATH)['model'])
cnn.eval()
pred = CNN_predict(cnn, Dte)
print(mean_absolute_error(te_y, pred2.T), np.sqrt(mean_squared_error(te_y, pred2.T)))
CNN在Dte上的表现如下表所示:
| 1.08 | 1.51 |

到此这篇关于PyTorch搭建CNN实现风速预测的文章就介绍到这了,更多相关PyTorch CNN风速预测内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!