R-CNN、SPPNet、Fast Rcnn、Faster R-CNN 原理以及区别
R-CNN原理:
R-CNN遵循传统目标检测的思路,同样采取提取框,对每个框提取特征,图像分类,非极大值抑制等四个步骤,只不过在提取特征这一步将传统的特征换成了深度卷积网络提取的特征。
对于原始图像, 首先使用Selective Search 搜寻可能存在物体的区域。Selective Search 可以从图像中启发式地搜索出可能包含物体的区域。相比穷举而言, Selective Search 可以减少一部分计算量。下一步,将取出的可能含高物体的区域送入CNN 中提取特征。CNN 通常是接受一个固定大小的图像,而取出的区域大小却各有不同。对此, R-CNN的做法是将区域缩放到统一大小, 再使用CNN提取特征。提取出特征后使用SVM 进行分类,最后通过非极大值抑制抑制输出结果。
R-CNN的过程可以分为四步:
在数据集上训练CNN 。R-CNN 论文中使用的CNN 网络是AlexNet 1,数据集为ImageNet 。
在目标检测的数据集上,对训练好的CNN做微调 。
用Selective Search 搜索候选区域,统一使用微调后的CNN对这些区域提取特征,并将提取到的特征存储起来。
使用存储起来的特征,训练SVM 分类器。
SPPNet原理
SPPNet原理就是利用ROI池化层将CNN的输入从固定尺寸改为任意尺寸,通过最大池化层,可以将任意宽度的、高度的卷积特征转换成固定长度的向量,原始图像中的候选框,实际也可以对应到卷积特征中相同位置的框。利用ROI池化层可以将不同形状的特征对应到相同长度的向量特征。与R-CNN相比比,SPPNet具有更快的速度。
Fast RCNN原理
Fast RCNN与SPPNet相比,不再使用SVM分类,而是利用神经网络分类,直接使用全连接层,全连接层有两个输出,一个负责分类,另一个负责框回归。同一个网络完成提取特征、判断类别、框回归三项工作。
Faster RCNN原理
与Fast RCNN相比,Faster RCNN用RPN网络代替了Selective search,RPN网络结构为:
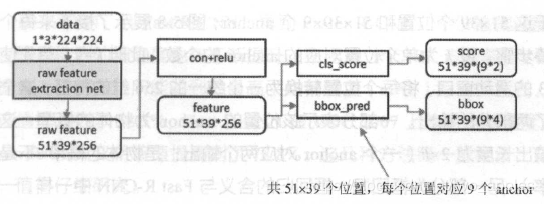
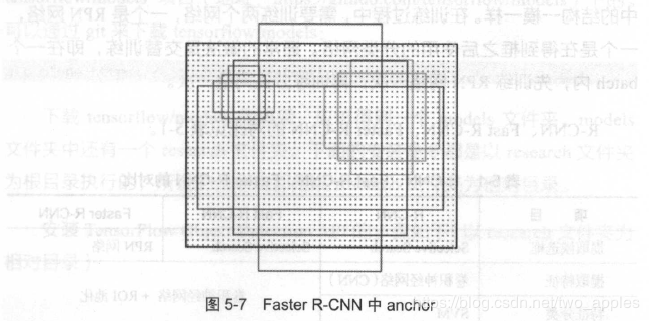
RPN还是需要先使用一个CNN网络对原始图片进行提取特征,对应一个5139256的卷积特征,称它一共有5139个位置,让新的卷积特征的每一个“位置”都负责原图中对应位置9种尺寸的框的检测,检测的目标是判断框中是否存在一个物体,因此共有51399个框,在论文中,将这些框分别称为anchor。
anchor的9中尺寸如小图所示,它们的面积分别是1282128^21282、2562256^22562、5122512^25122。每种面积又分3种长宽比,分别为2:1、1:2、1:1。
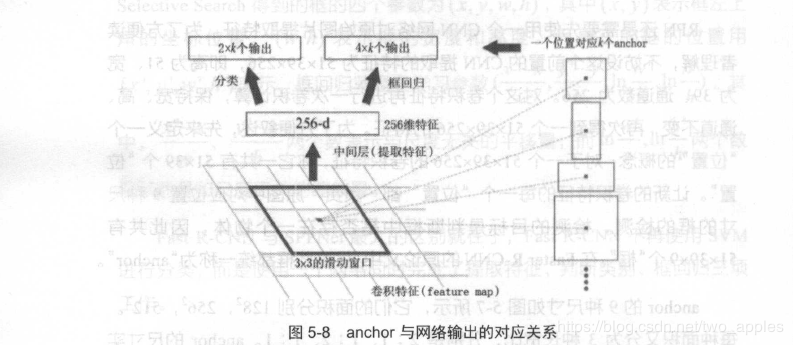
对于这5139ge1weizhi1he151399个anchor,下图展示了接下来每个位置的计算步骤,设k为每个位置对应的anchor的个数,此时,K=9。首先使用一个33的滑动窗口,将每个位置转换成一个统一的256维特征,这个特征对应了两部分的输出,一部分表示该位置的anchor诶物体的概率,这部分总输出为长度为2k,(一个anchor对应两个输出,是物体的概率和不是物体的概率)。另一部分为框回归,框回归有4个参数,(x,y,w,h)。所以框回归部分的总输出长度为4k。
 对比示意图
对比示意图

作者:two_apples