Druid知识点及踩坑总结
1. Druid中的intervals参数
"spec" : {
"ioConfig" : {
"type" : "hadoop",
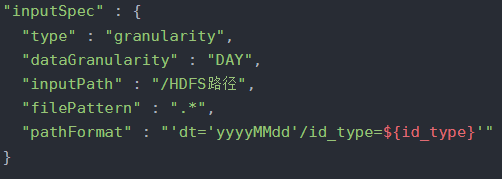
"inputSpec" : {
"type" : "granularity",
"dataGranularity" : "DAY",
"inputPath" : "/HDFS路径",
"filePattern" : ".*",
"pathFormat" : "'dt='yyyyMMdd'/id_type=${id_type}'"
}
},
"dataSchema" : {
"dataSource" : "da_wanxiang_tag_analysis__metric",
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "DAY",
"queryGranularity" : "DAY",
"intervals" : ["${sday}T00:00:00.000+08:00/${eday}T00:00:00.000+08:00"]
},
"parser" : {
"type" : "hadoopyString",
"parseSpec" : {
"format" : "tsv",
"delimiter" : "\u0001",
"timestampSpec" : {
"format" : "yyyy-MM-dd HH:mm:ss",
"column" : "dt_time"
}
}
},
},
GranularitySpec中的intervals参数,指定过滤的时间范围,有两个用途:
一是对于ioConfig里的inputPath下的pathFormat的dt=yyyyMMdd,指定了分区日期,为${sday}。
二是对于输入路径下的所有数据,有一个timeStamp列,这一列存储了每一行数据对应的时间戳,不符合intervals范围的时间戳对应的行会被丢弃。
例如:指定了分区日期为dt=2020-02-16,但是输入路径的文件数据中,时间戳列全是2020-01-16,会报错

报错信息如下:
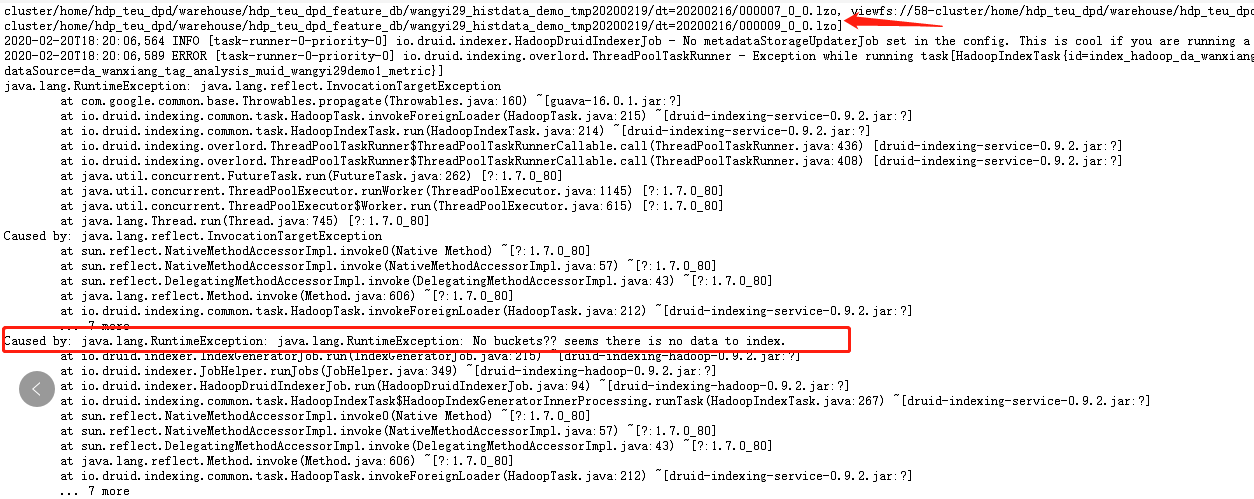
上面显示已经读取了输入路径下的分区数据,但是下面又报错No buckets? seems there is no data to index
报错原因在于找不到符合intervals的行
也就是说,intervals指定的dt=2020-02-16这个分区下的文件虽然被读取到了,但是时间戳列都是2020-01-16,所以没有符合过滤条件的数据,也即没有data能够进入Druid的segment中,所以会报以上错误。
2. Druid中的hadoop数据源的粒度
粒度有两种,查询粒度queryGranularity和存储粒度segmentGranularity。
区别是,存储粒度的粒度更细,比如存储粒度为hour,查询粒度可以是hour和day
但是如果存储粒度是day,查询粒度就不能是hour了。
3. Druid中inputSpec参数
若type指定为static,为明确指定输入路径,路径指定到文件夹。
若type指定为granularity,则需要在输入路径目录中,指定日期格式,如上面所示。

参考文档:druid上传数据index文件配置
作者:攻城狮Kevin