OLAP红与黑 | 也许你应该考虑一下Druid

By 大数据技术与架构
场景描述:Druid是一个专为大型数据集上的高性能切片和OLAP分析而设计的数据存储。Druid最常用作为GUI分析应用程序提供动力的数据存储,或者用作需要快速聚合的高度并发API的后端。
关键词:Druid 大数据
OLAP 和 OLTP 经常被拿到一起来讨论。其中 OLAP 的全称是 On-Line Analytical Processing,OLTP 的全称是 On-Line Transaction Processing。网上分析对比这两种系统的讨论很多都是长篇累牍,其实从系统角度来看 OLAP 和 OLTP 的最大区别无非是下面几点:
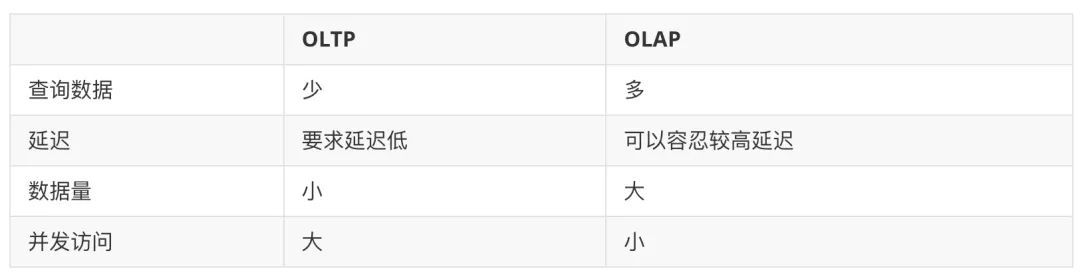
OLTP 对应常见的关系型数据库,比如 MySQL 等。OLAP 又分实时 OLAP 和离线 OLAP。大数据的一些架构,比如常见 Hive + Hadoop,SparkSQL + HDFS,Kylin 等就是离线 OLAP,而一些监控告警系统这种对实时性要求比较高的系统就是实时 OLAP。
Druid 就属于实时 OLAP。我们是从去年的差不多这个时间开始使用 Druid 从 0 到 1 搭建了我们的实时 OLAP 系统,这套系统目前在线上运行半年,单个 DataSource 摄入的数据在百亿级别。在这个过程中遇到很多问题,也发现了 Druid 的一些局限性。
特性
Druid 很早就进入了 Apache 孵化器,但是现在还没有毕业。官网:druid.apache.org,Github: apache/incubator-druid
根据官方文档,Druid 的核心特性主要包括:
列式存储。列式存储的优势在于查询的时候可以只返回指定的列的数据,其次同一列数据往往具有很多共性,这带来另一个好处就是存储的时候压缩效果比较好。
可扩展的分布式架构。
并行计算。
数据摄入支持实时和批量。这里的实时的意思是输入摄入即可查。如果大家看过我之前关于实时计算的文章,应该猜到了这就是典型的 lambda 架构,后面再细说。
运维友好。
云原生架构,高容错性。
支持索引,便于快速查询。
基于时间的分区
自动聚合。
不知道官方是不是为了刻意凑数,正好十条。其中很多特性其实应该算是 OLAP 系统的共同特性,比如列式存储等。当时我选型使用 Druid 的时候,其实最吸引我的主要是下面三条:
实时摄取可查询。换句话说就是数据查询无延迟,这个在一些对实时性要求比较高的场景下,比如监控告警,还是很重要的。
自动实时聚合。
高效的索引结构便于查询。
架构
Druid 的架构在我看来还是比较复杂的,包含 6 个不同的组件。
Coordinator:顾名思义,Coordinator 就是协调器,主要负责 segment 的分发等。比如我们只保存 30 天的数据,这个规则就是由 Coordinator 来定时执行的。
Overlord:处理数据摄入的 task,将 task 提交到 MiddleManager。比如使用 Tranquility 做数据摄入的时候,每个 segment 都会生成一个对应的 task。
Broker : 处理外部请求,并对结果进行汇总。
Router : Router 相当于多个 Broker 前面的路由,不是必须的。
Historical :Historical 可以理解为将 segment 存储到本地,相当于 cache。相比于 Deep Storage 的,Historical 将 segment 直接存储到本地磁盘,只有 segment 存储到本地才能被查询。其实这个地方是有点异于直观感受的。正常我们可能会认为查询先查本地,如果本地没有数据才去 查 Deep Storage,但是实际上如果本地没有相应的 segment,则查询是无法查询的。Historical 处理那些 segment 是由 Coordinator 指定的,但是 Historical 并不会和 Coordinator 直接交互,而是通过 Zookeeper 来解耦。
MiddleManager : MiddleManager 可以认为是一个任务调度进程,主要用来处理 Overload 提交过来的 task。每个 task 会以一个 JVM 进程启动。
各个组件之间的交互如下:
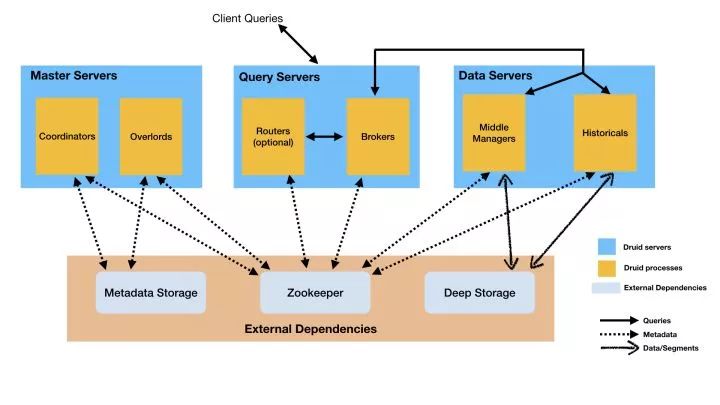
根据线条,上图主要关注三个部分:
Queries: Routers 将请求路由到 Broker,Broker 向 MiddleManager 和 Historical 进行数据查询。这里 MiddleManager 主要负责查询正在进行摄入的数据查询,比如现在正在摄入 12:00 ~ 13:00 的数据,那么我们要查询就去查询 MiddleManager,MiddleManager 再将请求分发到具体的 peon,也就是 task 的运行实体上。而历史数据的查询是通过 Historical 查询的,然后数据返回到 Broker 进行汇总。这里需要注意的时候数据查询并不会落到 Deep Storage 上去,也就是查询的数据一定是 cache 到本地磁盘的。很多人一个直观理解查询的过程应该是先查询 Historical,Historical 没有这部分数据则去查 Deep Storage。Druid 并不是这么设计的。
Data/Segment: 这里包括两个部分,MiddleManager 的 task 在结束的时候会将数据写入到 Deep Storage,这个过程一般称作 Segment Handoff。然后 Historical 定期的去下载 Deep Storage 中的 segment 数据到本地。
Metadata: Druid 的元数据主要存储到两个部分,一个是 Metadata Storage,这个一般是 MySQL 等关系型数据库;另一个是 Zookeeper。下图是 Druid 在 Zookeeper 中的 znode。zk 的作用主要是用来给各个组件进行解耦。

数据存储
Druid 的数据存储单位是 segment,segment 按时间粒度(可以通过参数 segmentGranularity 指定)划分。每个 segment 会被存储到 Deep Storage 和 Historical 进程所在的节点上,当然 segment 可以是有多个备份的,这样查询的时候就可以实现并行查询,并不是为了高可用,高可用通过 Deep Storage 保证。
Druid 的数据格式如下:
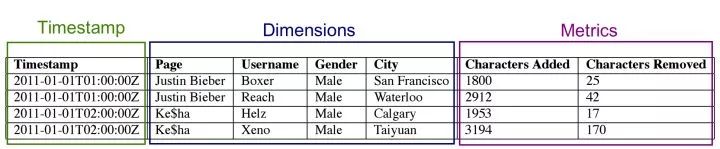
分成三个部分:
Timestamp:时间戳信息
Dimension:维度信息
Metrics: 一般是数值型
Druid 会自动对数据进行 Rollup,也就是聚合。如果时间粒度是一小时,那么在这一个小时内维度相同的数据会被合并为一条,Timestamp 都变成整点,metrics 会根据聚合函数进行聚合,比如 sum, max, min 等,注意是没有平均 avg 的。Timestamp 和 Metrics 直接压缩存储即可,比较简单。下面重点说一下维度的存储。
Druid 的一大亮点就是支持多维度实时聚合查询,简单来说就是 filter 和 group。而实现这个特性的关键技术主要两点:bitmap + 倒排。
首先,Druid 会将维度值编码映射成数字 ID,类似数据仓库中的维度表,主要是为了存储节省空间。比如上面图中的 Page 维度:Justin Bieber 被编码成 0,Ke$ha 被编码成 1。对于 Username 维度:Boxer -> 0,Reach -> 1,Helz -> 0,Xeno -> 1。
然后 Page 这列数据就会被存储为 [0,0,1,1]。
最后是位图,用来表示对于某个维度的某个值,有哪些列包含了这个值,比如:
Justin Bieber: [1,1,0 ,0]
Boxer: [1,0,0,0]
那么 filter 查询 Page='Justin Bieber' and Username='Boxer',直接将 1100 和 1000 做位运算 and 即可。group 也是类似。
上面的位图,其实也是一种倒排,常规的倒排后面的 list 中直接包含的是 Document ID,这里直接表示成位图,其实是异曲同工。
数据摄入
前面简单提到 Druid 的数据摄入支持实时流模式和批模式,也就是典型的 Lambda 架构。Lambda 架构简单来说就两点:
通过实时处理保证实时性
通过批处理保证数据完整性和准确性
如果看过我之前的关于 Google DataFlow 的文章,当时作者就大肆批评了 lambda 架构,然后在 Google 内部是通过 MillWheel 支持 exactly-once 语义来避免了 lambda 架构。在 druid 中的数据摄入官方支持了多种方式,关于各种方式的对比可以用如下一个图来概括。
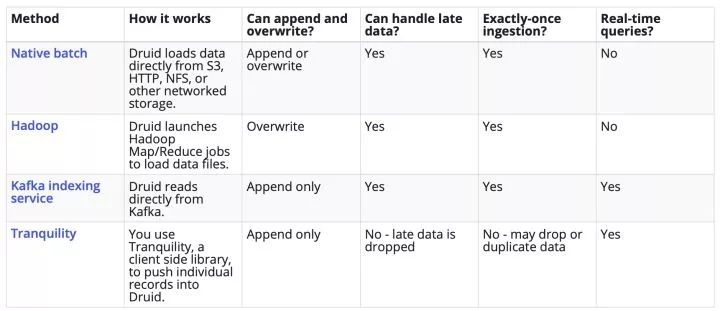
关于上图中的 ”Can handle late data“ 做一下简单说明,我们上面在数据存储一节有说到 Druid 的底层存储使用了 segment 结构。举个例子,如果时间粒度是 1 个小时,那么 12:00 ~ 13:00 的数据就会存储到一个 segment 里面。但是这里有一个小问题需要考虑一下,就是这个 segment 的数据什么时候 ready 我怎么知道呢?这个在流处理中一种常规的做法是 watermark,简单来说就设置一个可以接受的时间延迟,比如 5 分钟,那么 12:00 ~ 13:00 会一直接受数据直到 13:05,然后之后这个 segment 就会被 handoff 掉,12:00 ~ 13:00 之间的数据就不再接受了。这个过程就叫做 ”handle late data“。然后我们发现上图中 Tranquility 是不支持 late data 处理的,这个是需要特别注意的。
从上图我们可以看到 Native batch 和 Hadoop 都对应了 Lambda 架构中的批处理,而 Tranquility 则对应了 Lambda 架构中实时处理,是一种 push 的方式。然后这里还有一种方式叫 Kafka Indexing Service,这种方式通过 pull 的方式来摄取数据,我们也可以看到通过 Kafka Indexing Service 这一种服务其实就可以完成数据摄取并满足所有需求,不然就要通过两种方式联合使用。但是使用 Kafka Indexing Service 的最大问题就是和 Kafka 强耦合。
因为我们的业务是在阿里云公有云上,然后所有数据采集都使用了阿里云的日志服务(SLS)来处理的,所以这里我们并不能使用 Kafka index。这里我们使用的方式是 Tranquility + Hadoop 的方式来进行数据摄取。单个 DataSource 的数据摄入量达到百亿级别。
查询
NatvieDruid 最开始的时候是不支持 SQL 查询的,原生查询是通过查询 Broker 提供的 http server 来实现的,如下:
curl -X POST ':/druid/v2/?pretty' -H 'Content-Type:application/json' -H 'Accept:application/json' -d @下面是一个简单的 json 查询示例。
{ "queryType": "timeseries", "dataSource": "sample_datasource", "intervals": [ "2012-01-01T00:00:00.000/2012-01-03T00:00:00.000" ], "granularity": "day", "aggregations": [ { "type": "longSum", "name": "sample_name1", "fieldName": "sample_fieldName1" }, { "type": "doubleSum", "name": "sample_name2", "fieldName": "sample_fieldName2" } ], "context": { "grandTotal": true } }同时社区也提供了很多种语言的 client 用来做 Druid 的查询,比如我们使用的 Java 的 client zapr/druidry ,关于更多语言的 client,可以参考这里 client libraries 。
Druid 的查询类型有下面几种:
聚合查询(Aggregation Queries):
Timeseries : 可以简单理解为性能更好的 select。
TopN : TopN 相当于 GroupBy 加 Ordering,相同的查询我们正常也可以通过 GroupBy 查询来实现,但是 TopN 的性能更好。TopN 的底层实现也是比较直观的,将并行查询的每个查询的结果的 TopK 结果返回给 Broker,由 Broker 进行聚合汇总。注意这里返回的结果是 K 条记录,而不是 N 条记录,K 默认值为 max(1000, threshold) 决定(threshold 由用户指定,就相当于 TopN 中的 N)。
GroupBy : GroupBy。
元数据查询(Metadata Queries)
Druid 的元数据一般是存储到 MySQL 中,包含一些 dataSource,segment 的元信息。
Druid 提供的元数据查询有下面三种
Time Boundary: 用来查询查询指定模式的数据第一次出现和最近一次出现的时间。
Segment Metadata:返回 segment 的元信息,包括维度信息等。
Datasource Metadata:返回 dataSource 的元信息。
搜索查询(Search Queries)
Search
范围查询 (Scan):scan 的结果是以流模式返回的,也就是 client 真正读取的时候才会占用内存。
Select: 官方已经不建议使用 Select 查询。这里就不在介绍了。
Druid 的底层存储由于是使用时间来做分片的,所以查询的时候一定需要带上时间区间。
我在上面说过一次 Druid 的 Rollup 不支持 average,也就是平均值,那么如果我查询的时候要查询平均值应该怎么做呢?(其实查询平均值是一个非常常见的需求,关于为了 Druid 的 Rollup 不支持 average,欢迎留言讨论。)
答案是 postaggregate,druid 在查询的时候可以定义聚合操作,是查询的时候直接计算的。同时 druid 还提供了针对聚合后的值的聚合操作,叫做 postaggregate。一个简单的查询 json 文件示例。
{ "queryType": "timeseries", "dataSource": "sample_datasource", "granularity": "day", "descending": "true", "filter": { "type": "and", "fields": [ { "type": "selector", "dimension": "sample_dimension1", "value": "sample_value1" }, { "type": "or", "fields": [ { "type": "selector", "dimension": "sample_dimension2", "value": "sample_value2" }, { "type": "selector", "dimension": "sample_dimension3", "value": "sample_value3" } ] } ] }, "aggregations": [ { "type": "longSum", "name": "sample_name1", "fieldName": "sample_fieldName1" }, { "type": "doubleSum", "name": "sample_name2", "fieldName": "sample_fieldName2" } ], "postAggregations": [ { "type": "arithmetic", "name": "sample_divide", "fn": "/", "fields": [ { "type": "fieldAccess", "name": "postAgg__sample_name1", "fieldName": "sample_name1" }, { "type": "fieldAccess", "name": "postAgg__sample_name2", "fieldName": "sample_name2" } ] } ], "intervals": [ "2012-01-01T00:00:00.000/2012-01-03T00:00:00.000" ] }SQLSQL 在大数据系统,尤其是 OLAP 中的重要性是不言而喻的。所以早期看到 Druid 不支持 SQL 查询,我是非常诧异的,后面果不其然,Druid 还是推出了 SQL 查询。这一层构建与 Native 请求之上,也就是说 SQL 会被解释成 Native 的查询,然后去请求 Broker。
Druid SQL 解析基于 Apache Calcite,说起 Apache Calcite 是一个业界使用非常广泛的 SQL 语法解析模块,如果没有记错, Hive 使用的好像也是它。
Druid SQL 值得一提的是提供了非常多的 function,包括数值计算,字符串操作,时间操作等。举个例子,其中一个字符串操作函数叫做
REGEXP_EXTRACT(expr, pattern, [index])对 expr 做正则匹配,并提取特定的字段。使用这个函数可以做非常多的事情。但是 function 有的时候对于 SQL 的执行计划优化并不是非常友好,不知道这里 Druid 团队是如何权衡的。其他问题
明细查询
由于 Druid 会对存储的数据做 Rollup,正常情况下是不能存储明细的。但是如果是你一定需要明细的话,有个办法就是将所有所有的列,包括 metric,都设置成 dimension,同时将聚合粒度设置到可以接受的粒度,比如秒。
高基数这里的高基数指的是 Druid 的 Dimension 的值可能会有非常多的值,这样引入一个问题就是存储的时候会消耗比较大的空间,同时对于 CPU 的占用也会有一定程度的影响。
Tranqility Data Ingest
基于 Tranquility 的数据摄取虽然并不能保证数据的一致性和完整性,但是由于其可以保证实时性,我们在可以容忍一定程度的数据一致性的情况下,还是使用了 Tranquility 来做数据摄入。但是网上关于这部分的代码示例基本没有,所以这个地方打算分享一下源码。我们这里的技术栈是 Spark Streaming + Tranquility + Druid,代码主要包括三个部分:
Event 定义,指定 DataSource 的 schema
BeamFactory 定义,这个地方主要为了定义一些需要的信息。比如 :
zk 地址,用来做服务发现
dimension 指定
Rollup 的聚合算子指定:count, sum, max, min 等,注意没有 avg
segment 的时间粒度指定
窗口大小指定
Spark Streaming 的主体代码
下面这个部分就是 Event 的 schema 定义函数。
case class MetricEvent(jsonString: String) { val json = JSON.parseObject(jsonString) val ts = new DateTime(json.getLong("timestamp") * 1000) @JsonValue def toMap: Map[String, Any] = { var map = Map( "timestamp" -> json.getLong("timestamp"), "dim1" -> json.getString("dim1"), "dim2" -> json.getString("dim2"), "dim3" -> json.getString("dim3"), "metric" -> json.getString("metric"), "value" -> json.getString("msg"), "userId" -> json.getString("userid") ) return map } }下面是 BeamFactory 的定义函数。
class MetricEventBeamFactory extends BeamFactory[MetricEvent] { def makeBeam: Beam[MetricEvent] = MetricEventBeamFactory.BeamInstance } object MetricEventBeamFactory { val BeamInstance: Beam[MetricEvent] = { // Tranquility uses ZooKeeper (through Curator framework) for coordination. val curator = CuratorFrameworkFactory.newClient( //apm-druid-header-3 "zk-host-1:2181,zk-host-2:2181,zk-host-3:2181", new BoundedExponentialBackoffRetry(100, 3000, 5) ) curator.start() val indexService = "druid/overlord" // Your overlord's druid.service, with slashes replaced by colons. val discoveryPath = "/druid/discovery" // Your overlord's druid.discovery.curator.path val dataSource = "legendtkl" // dataSource Name val dimensions = IndexedSeq("dim1", "dim2", "metric", "dim3") val aggregators = Seq(new CountAggregatorFactory("count"), new DoubleSumAggregatorFactory("sum", "value"), new DoubleMinAggregatorFactory("min", "value"), new DoubleMaxAggregatorFactory("max", "value")) val isRollup = true // Expects simpleEvent.timestamp to return a Joda DateTime object. DruidBeams .builder((metricEvent: MetricEvent) => metricEvent.ts) .curator(curator) .discoveryPath(discoveryPath) .location(DruidLocation(indexService, "druid:firehose:%s", dataSource)) //.rollup(DruidRollup(SpecificDruidDimensions(dimensions), aggregators, QueryGranularities.MINUTE, isRollup)) .rollup(DruidRollup(SpecificDruidDimensions(dimensions), aggregators, QueryGranularities.MINUTE)) .tuning( ClusteredBeamTuning( segmentGranularity = Granularity.FIVE_MINUTE, windowPeriod = new Period("PT5M"), partitions = 1, replicants = 1 ) ) .timestampSpec(new TimestampSpec("timestamp", "posix", null)) //.partitioner(new customPartioner) .buildBeam() } }最后是 Streaming 中对应的代码逻辑。
loghubStream.foreachRDD(rdd => rdd.map(x => MetricEvent(new String(x))).propagate(new MetricEventBeamFactory) )冷热数据分离
Druid 的架构中有一个 Deep Storage,这里的冷数据指定的就是 Deep Storage 中存储的数据,热数据是 segment cache 中存储的数据,也就是本地文件系统。关于 Deep Storage 有一点比较反直觉的是在 Deep Storage 中的数据是不可以 Query 的,只有在 Segment cache 中的数据才是可查的。
Druid 的 Deep Storage 支持 local,HDFS, S3, Google Cloud 等。这里的 local 指的是不光是本地文件系统,还有任何可以挂载到 local 的文件系统,比如 NFS,Ceph 等(用本地文件系统用作 Deep Storage 实在不是明智之举)。关于 HDFS,又可以衍生出一系列支持 HDFS 接口的存储系统的,比如阿里云的兼容了 HDFS 协议的 OSS 对象存储,直接构建于盘古文件系统上的兼容 HDFS 协议的产品。
要设置 Deep Storage 主要涉及到两个参数:
druid.storage.type: 比如 local, hdfs, s3
druid.storage.storageDirectory: 文件存储路径
S3 存储的话还需要填写 ak 等参数。这里有一点就是不需要设置文件的生命周期,或者说 TTL。这里我也不太明白为什么 Deep Storage 存储文件的 TTL 为什么不是交由 Druid 来管理。
热数据,segment cache 设置可以通过设置 historical 的如下参数进行设置:
druid.segmentCache.locations
比如设置成 [{"path": "/mnt/disk1/druid/segments-cache", "maxSize": 850000000000}]
SegmentCache TTL
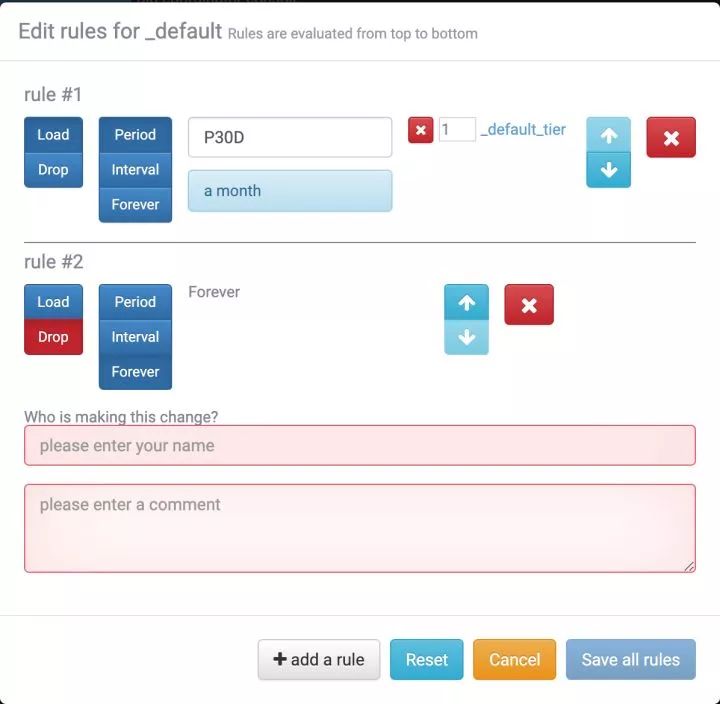
SegmentCache 决定了我们数据的可查询时间范围,这个我们可以通过 Coordinator 设置相应的 rule 来解决。Coordinator 的 Rule 分三种,Rule 可以应用到某一个 dataSource,也可以应用到所有的 dataSource:
Load Rule: 决定什么样的 segment 应该被 load 到 segmentcache。
Drop Rule: 决定什么样的 segment 应该被 drop 掉。
Broadcast Rule: 让不同 dataSource 的 segment 被共同存储到同一个 historical 上。
然后每种不同的 Rule 又细分三种类型:
Forever: 整个生命周期
Interval: 固定的某一个时间段
Period: 距离现在的某一个时间段
Rule 的顺序很重要,Coordinator 会按顺序从上到下将 segment 与 rule 进行匹配,当匹配到了之后就不再往下走了。所以 Rule 的配置一般都是 Load 和 Drop 进行配合使用。下面举个例子,我们这里使用 Coordinator 的 Console 进行 rule 设置。下图中包含两个 Rule,一个 Load Rule(第一条),一个 Drop Rule(第二条)。其中 Load Rule 是 Period 类型,Load 最近 30 天的 segment ,Drop Rule 是 Forever 类型。比如说现在有一个 segment 进行匹配,距离现在 29 天,那么就匹配到了第一条 Rule,被 load 到 segment cache,然后停止继续匹配;然后又来了一个 segment,距离现在 31 天,只能匹配到第二个 rule,直接被 Drop 掉。
Realtime Query
所谓实时 OLAP 也就是数据摄入即可查。我们知道数据在做 Realtime Ingest ,没有 handoff 之前是没有存储到 segment 中,这时候查询要通过 realtime task 来查询,也就是 peon。但是我们实践中发现这个地方查询很容易出现瓶颈。如果有人出现了类似的问题,下面几个参数可以参考:
druid.processing.numThreads
druid.processing.buffer.sizeBytes
druid.peon.xmx.gb
druid.indexer.runner.javaOpts
本文来源:https://dwz.cn/UJEylrkv
作者:尼不要逗了
作者:Spark高级玩法