《动手学》公益课打卡笔记02-CNN、RNN进阶
CNN
CNN中的卷积核:其实是“3维”的而不是2维,多出来的那个维度对应图像的多个通道。
作者:仿星器
本卷积层中卷积核的个数即为下个卷积层中卷积前输入数据的通道数。
卷积时不使用padding的坏处:
(1 每次做卷积操作,你的图像就会缩小,从 6×6 缩小到 4×4,你可能做了几次之后,你的图像就会变得很小了,可能会缩小到只有 1×1 的大小。
(2 边缘像素信息丢失:
如果你注意角落边缘的像素,这个像素点(绿色阴影标记)只被一个输出所触碰或者使用,因为它位于这个 3×3 的区域的一角。但如果是在中间的像素点,比如这个(红色方框标记),就会有许多 3×3 的区域与之重叠。所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息。
卷积层的两个主要优势在于参数共享和稀疏连接.
RNN进阶各种RNN架构:
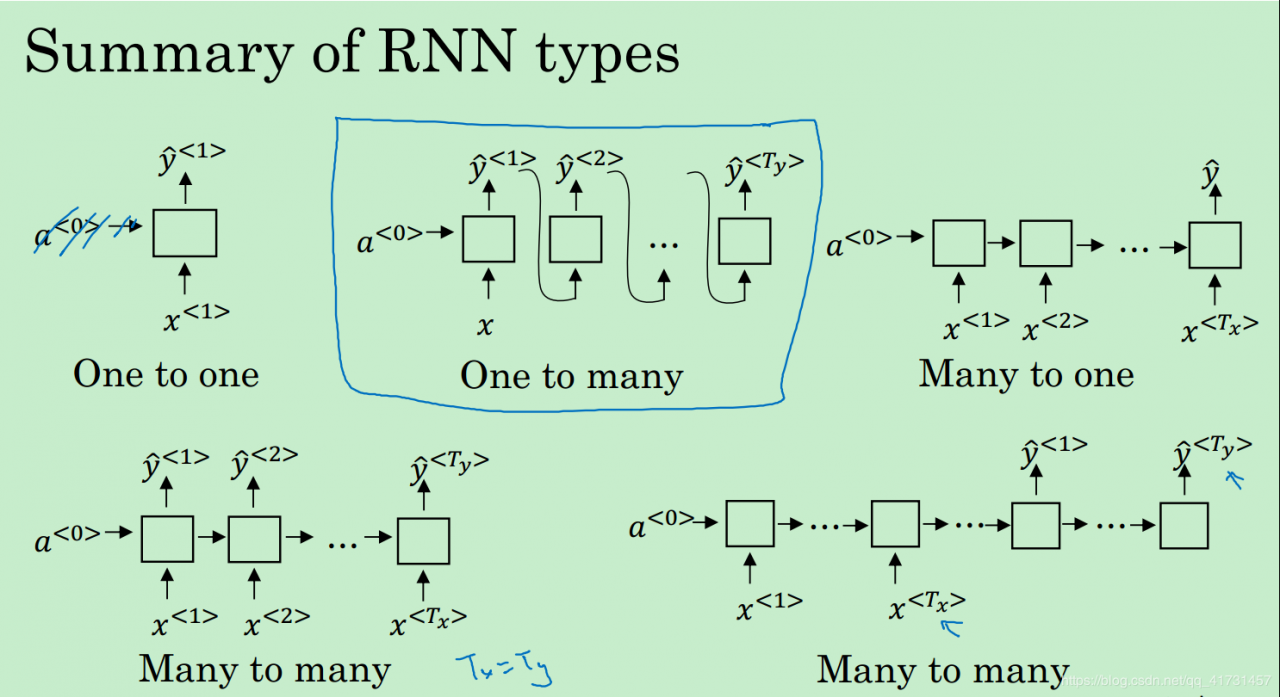
一对一:可以说不是RNN,就是经典的感知机
一对多:只有一个输入值。例子:序列的生成,如音乐生成
多对一:只在最后输出单个值。例子:电影情感分类
多对多(Tx = Ty):就是前面所讲的网络。
多对多(Tx != Ty):先处理全部的输入值,然后再逐一输出各个y值!而不是边处理x边生成y.
GRU和LSTM:用来解决梯度消失和爆炸带来的长期依赖问题,通过显式存储必要信息的方式!
GRU:Gated Recurrent Unit,简化版的LSTM
仅有Reset(Relevance)门和Update门: a = c
 c值就是显式存储的信息,为多维向量,其中每个位都存储信息。update门决定c值更新的情况,relevance门决定生成当前的候选c值时,上一个c值的影响力。
c值就是显式存储的信息,为多维向量,其中每个位都存储信息。update门决定c值更新的情况,relevance门决定生成当前的候选c值时,上一个c值的影响力。
LSTM:Long-Short Term Memory,有update门,forget门,output门。


标准LSTM的架构如上图。
作者:仿星器