三维点云语义分割【综述】 ——Deep Learning for 3D Point Clouds: A Survey
3D点云分割需要了解全局几何结构和每个点的细粒度细节。根据分割粒度,可以将3D点云分割方法分为三类:语义分割(场景级别),实例分割(对象级别)和部件分割(部件级别)。 3D Semantic Segmentation
给定一个点云,语义分割的目标是根据它们的语义将点云分为几个子集。类似于3D形状分类的分类法,存在两种语义分割范例,即基于投影的方法和基于点的方法。我们在图8中显示了几种代表性方法。
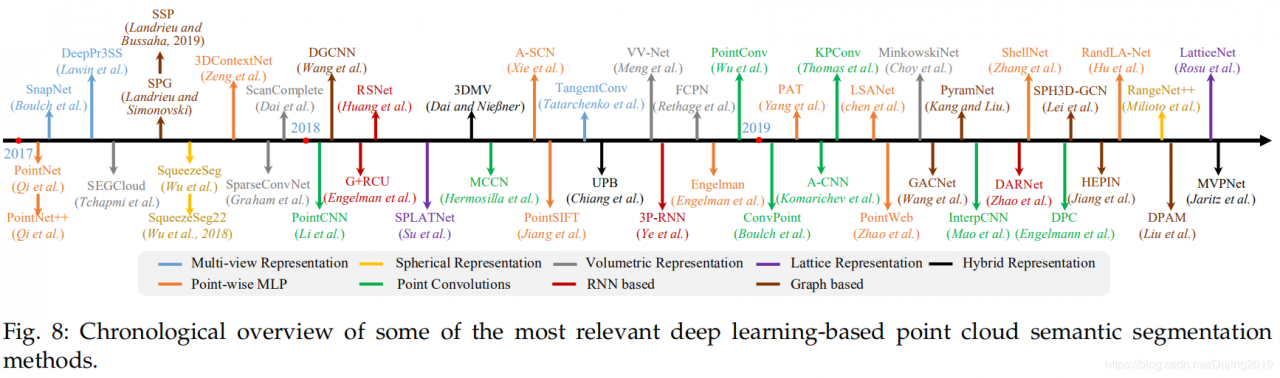
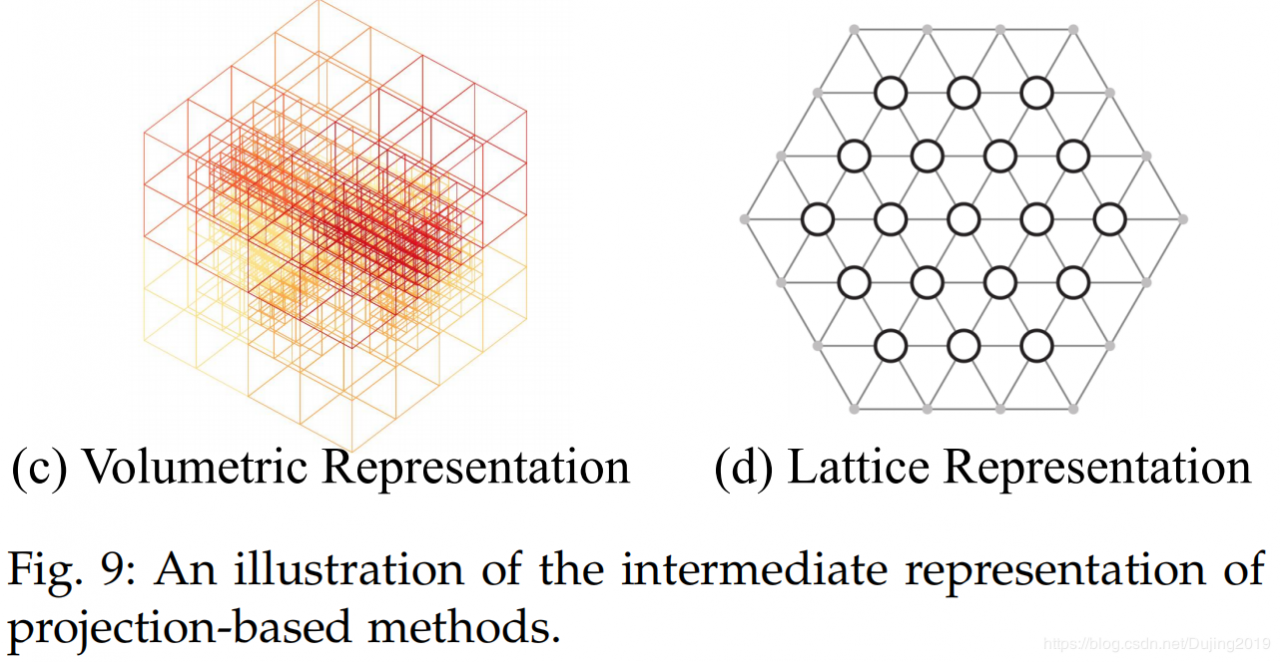
中间正则表示可以组织或分类为多视图表示[148],[149],球形表示[150],[151],[152],体积表示[153],[154],[155],多面体如图9所示,可以使用点阵表示[156],[157]和混合表示[158],[159]。
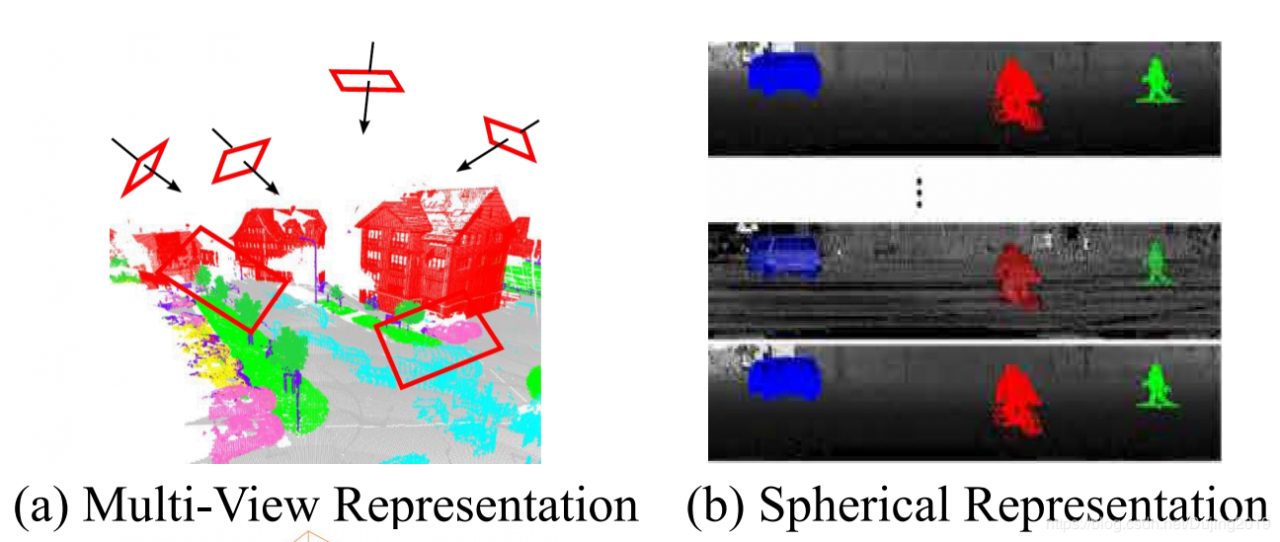
Multi-view Representation. Felix等[148]首先从多个虚拟相机视图将3D点云投影到2D平面上。然后,将多流FCN用于预测合成图像上的逐像素得分。每个点的最终语义标签是通过将重新投影的分数融合到不同的视图上而获得的。同样,Boulch等[149]首先使用多个相机位置生成了点云的几个RGB和深度快照。然后使用2D分割网络对这些快照执行逐像素标记。从RGB和深度图像预测的分数将使用残差校正进一步融合[160]。 Tatarchenko等人基于点云是从局部欧几里得表面采样的假设。 [161]介绍了切线卷积的密集点云分割。该方法首先将围绕每个点的局部曲面几何投影到虚拟切线平面。然后,切线卷积直接在曲面几何上进行运算。该方法显示了出色的可伸缩性,并且能够处理具有数百万个点的大规模点云。总体而言,多视图分割方法的性能对视点选择和遮挡很敏感。此外,这些方法还没有充分利用基础的几何和结构信息,因为投影步骤不可避免地会导致信息丢失。
Spherical Representation. 为了实现3D点云的快速准确分割,Wu等[150]提出了一个基于SqueezeNet [162]和条件随机场(CRF)的端到端网络。为了进一步提高分割精度,引入了SqueezeSegV2 [151],以利用无监督的域自适应流水线解决域移位问题。 Milioto等。 [152]提出了RangeNet ++用于LiDAR点云的实时语义分割。首先将2D范围图像的语义标签传输到3D点云,然后使用有效的基于GPU的KNN基于后处理的步骤来减轻离散化错误和推理输出模糊的问题。与单视图投影相比,球形投影保留了更多信息,并且适合于LiDAR点云的标记。但是,这种中间表示不可避免地带来了一些问题,例如离散化误差和遮挡。
Volumetric Representation. Huang等[163]首先将点云划分为一组占用体素。然后,他们将这些中间数据输入到全3D卷积神经网络中,以进行体素分割。最后,为体素内的所有点分配与体素相同的语义标签。该方法的性能受到体素的粒度和由点云分区引起的边界伪像的严重限制。此外,Tchapmi等。 [164]提出了SEGCloud来实现细粒度和全局一致的语义分割。这种方法引入了确定性三线性插值,将3D-FCNN [165]生成的粗体素预测映射回点云,然后使用完全连接CRF(FCCRF)来增强这些推断的点标签的空间一致性。孟等[153]引入了基于内核的内插变分自动编码器架构,以编码每个体素内的局部几何结构。代替二进制占用表示,对每个体素采用RBF以获得连续表示并捕获每个体素中点的分布。 VAE进一步用于将每个体素内的点分布映射到紧凑的潜在空间。然后,对称组和等效CNN均用于实现鲁棒的特征学习。
良好的可伸缩性是体积表示的显着优点之一。具体来说,基于体积的网络可以自由地在具有不同空间大小的点云中进行训练和测试。在全卷积点网络(FCPN)[154]中,首先从点云中分层提取不同级别的几何关系,然后使用3D卷积和加权平均池来提取特征并合并远程依赖项。该方法可以处理大规模的点云,并且在推理过程中具有良好的可伸缩性。Angela等[166]提出了ScanComplete,以实现3D扫描完成和逐像素语义标注。该方法利用了全卷积神经网络的可伸缩性,可以在训练和测试期间适应不同的输入数据大小。从粗到精策略用于分层提高预测结果的分辨率。体积表示自然是稀疏的,因为非零值的数量只占很小的百分比。因此,在空间稀疏数据上应用密集卷积神经网络效率低下。为此,Graham等[155]提出了子流形稀疏卷积网络。该方法通过将卷积的输出限制为仅与占用的体素有关,从而大大减少了内存和计算成本。同时,其稀疏卷积还可以控制所提取特征的稀疏性。该子流形稀疏卷积适用于高维和空间稀疏数据的有效处理。此外,Choy等 [167]提出了一种称为MinkowskiNet的4D时空卷积神经网络,用于3D视频感知。为了有效处理高维数据,提出了一种广义的稀疏卷积算法。三边平稳条件随机字段被进一步应用以增强一致性。
总体而言,体积表示自然保留了3D点云的邻域结构。它的常规数据格式还允许直接应用标准3D卷积。这些因素导致了该领域性能的稳步提高。然而,体素化步骤固有地引入了离散化伪像和信息丢失。通常,高分辨率会导致较高的内存和计算成本,而低分辨率会导致细节丢失。在实践中选择合适的网格分辨率并非易事。
Permutohedral Lattice Representation. Su等[156]提出了基于双边卷积层(BCL)的稀疏格子网络(SPLATNet)。该方法首先将原始点云插值到四面体的稀疏晶格,然后将BCL应用于在稀疏填充的晶格的占据部分进行卷积。然后将滤波后的输出内插回原始点云。另外,该方法允许灵活地联合处理多视图图像和点云。此外,Rosu等 [157]提出了LatticeNet来实现大点云的有效处理。还引入了称为DeformsSlice的与数据相关的插值模块,以将晶格特征反投影到点云。
Hybrid Representation. 为了进一步利用所有可用信息,已经提出了几种方法来从3D扫描中学习多模式特征。 Angela和Matthias [158]提出了一个联合3D多视图网络,以结合RGB特征和几何特征。使用3D CNN流和几个2D流来提取特征,并提出了一个可微的反投影层,以联合融合学习到的2D嵌入和3D几何特征。此外,洪等。 [168]提出了一个基于点的统一框架,以从点云中学习2D纹理外观,3D结构和全局上下文特征。该方法直接应用基于点的网络从稀疏采样的点集中提取局部几何特征和全局上下文,而无需任何体素化。 Jaritz等[159]提出了Multiview PointNet(MVPNet)来聚合2D多视图图像的外观特征和规范点云空间中的空间几何特征。
Point-based Networks基于点的网络直接在不规则点云上工作。但是,点云是无序的且没有结构,因此直接应用标准CNN并不可行。为此,提出了开拓性的工作PointNet [5]以使用共享MLP学习每点特征,并使用对称池功能学习全局特征。基于PointNet,最近提出了一系列基于点的网络。总体而言,这些方法可以粗略地分为pointwise MLP methods, point convolution methods, RNN-based methods, and graph-based methods.
Pointwise MLP Methods. 这些方法通常使用共享MLP作为其网络中的基本单位,以提高效率。然而,由共享的MLP提取的逐点特征不能捕获点云中的局部几何以及点之间的交互[5]。为了捕获每个点的更广泛的上下文并学习更丰富的局部结构,已引入了几个专用网络,包括基于相邻特征池,基于注意力的聚合以及局部全局特征串联的方法。
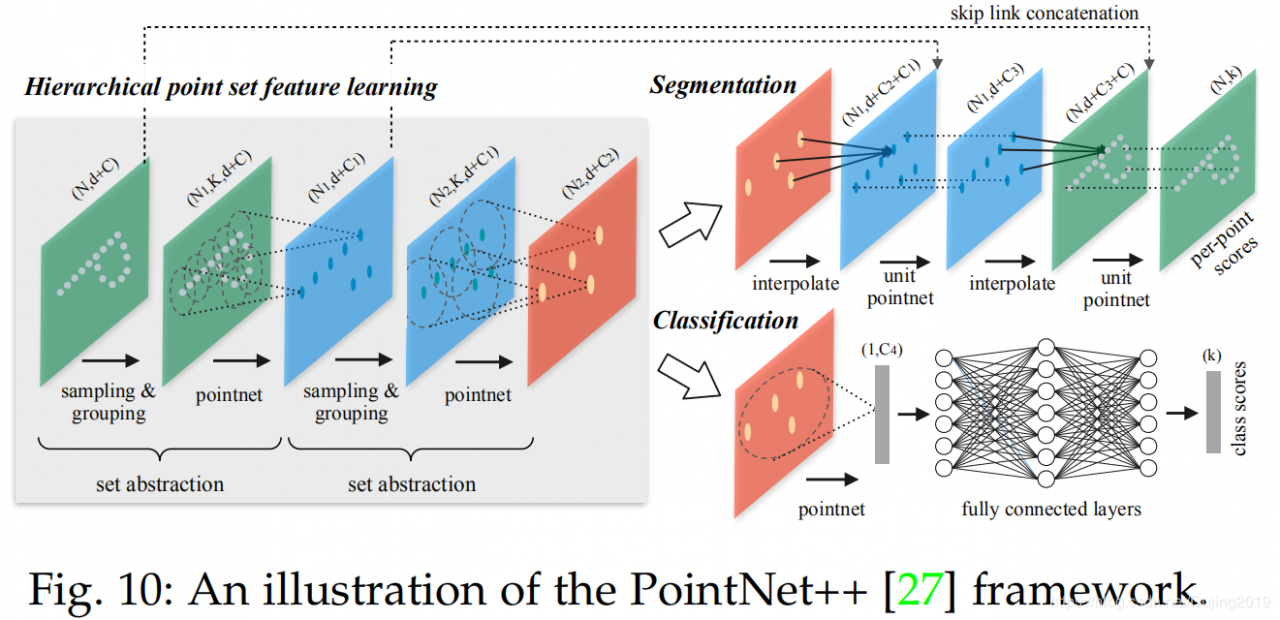
Neighboring feature pooling: 为了捕获局部几何图案,这些方法通过聚集来自局部相邻点的信息来学习每个点的特征。特别是,PointNet ++ [27]将点从更大的局部区域中分层并逐步学习,如图10所示。还提出了多尺度分组和多分辨率分组,以克服由不均匀和密度变化引起的问题。点云。后来,江等。 [114]提出了一个PointSIFT模块来实现定向编码和尺度感知。该模块通过三阶段有序卷积操作对来自八个空间方向的信息进行堆叠和编码。提取并连接多尺度特征,以实现对不同尺度的适应性。与PointNet ++中使用的分组技术(即球查询)不同,Francis等人。 [169]利用K-means聚类和KNN分别定义了世界空间和学习特征空间中的两个邻域。基于预期来自同一类的点在特征空间中更近的假设,引入成对的距离损失和质心损失以进一步规范化特征学习。为了模拟不同点之间的相互作用,Zhao等[31]提出了PointWeb来通过密集构建本地完全链接的网络来探索本地区域中所有点对之间的关系。提出了一种自适应特征调整(AFA)模块来实现信息交换和特征细化。此聚合操作有助于网络学习具有区别性的特征表示。张等[170]基于同心球壳的统计数据,提出了一个称为Shellconv的置换不变卷积。该方法首先查询一组多尺度的同心球,然后在不同的壳内使用最大池化操作汇总统计信息,使用MLP和一维卷积获得最终的卷积输出。 Hu等。 [95]提出了一种高效且轻量级的网络,称为RandLA-Net,用于大规模点云处理。该网络利用随机点采样在存储和计算方面实现了显着的效率。进一步提出了局部特征聚集模块以捕获和保留几何特征。
Attention-based aggregation: 为了进一步提高分割精度,引入了注意力机制[90]进行点云分割。杨等。 [29]提出了一个group shuffle attention以建模点之间的关系的方法,并提出了一种排列不变,任务不可知且可区分的Gumbel子集采样(GSS)来代替广泛使用的最远点采样(FPS)方法。该模块对异常值不那么敏感,可以选择一个有代表性的点集。为了更好地捕获点云的空间分布,Chen等[171]提出了一个局部空间感知(LSA)层来学习基于点云的空间布局和局部结构的空间感知权重。与CRF类似,Zhao等。 [172]提出了一个基于注意力的分数细化(ASR)模块,对网络产生的分割结果进行后处理。通过将相邻点的分数与学习的注意力权重合并在一起,可以细化初始分割结果。该模块可以轻松集成到现有的深度网络中,以提高最终的细分效果。
Local-global concatenation: 赵等 [85]提出了一种排列不变的PS2-Net,以结合点云中的局部结构和全局上下文。 Edgeconv [60]和NetVLAD [173]反复堆叠以捕获局部信息和场景级全局特征。
Point Convolution Methods. 这些方法倾向于为点云提出有效的卷积运算。华等。 [49]提出了一种点式卷积算子,其中将相邻点合并到核单元中,然后与核权重进行卷积。 Wang等。 [174]提出了一种基于参数连续卷积层的称为PCCN的网络。该层的内核功能由MLP参数化,并跨越连续向量空间。休斯等。 [42]提出了一种基于核点卷积(KPConv)的核点全卷积网络(KP-FCNN)。具体地,KPConv的卷积权重由到核点的欧几里得距离确定,并且核点的数量不是固定的。核心点的位置被公式化为球空间中最佳覆盖率的优化问题。请注意,半径邻域用于保持一致的接收场,而网格二次采样用于每一层,以在变化的点云密度下实现高鲁棒性。在[175]中,弗朗西斯等人。提供了丰富的消融实验和可视化结果,以显示接受场对基于聚集的方法性能的影响。他们还提出了扩散点卷积(DPC)运算以汇总膨胀相邻特征,而不是最近的K个邻居。事实证明,该操作在增加接收域方面非常有效,并且可以轻松地集成到现有的基于聚集的网络中。
RNN-based Methods. 为了从点云中捕获固有的上下文特征,递归神经网络(RNN)也已用于点云的语义分割。基于PointNet [5],Francis等人。 [180]首先将点的块转换为多尺度块和网格块,以获得输入级上下文。然后,将PointNet提取的逐块特征依次输入到合并单元(CU)或循环合并单元(RCU)中,以获得输出级别的上下文。实验结果表明,合并空间上下文对于提高分割效果非常重要。黄等[179]提出了一种轻量级的局部依赖建模模块,并利用切片池层将无序点特征集转换为特征向量的有序序列。 Ye等[181]首先提出了点向金字塔合并(3P)模块来捕获从粗到细的局部结构,然后利用双向分层RNN进一步获得远程空间依赖性。然后应用RNN来实现端到端学习。但是,这些方法在将局部邻域特征与全局结构特征聚合在一起时会失去点云的丰富几何特征和密度分布[189]。为了减轻刚性和静态合并操作引起的问题,Zhao等[189]提出了一个动态聚合网络(DAR-Net)来考虑全局场景复杂性和局部几何特征。使用自适应的接收字段和节点权重来动态聚合中间特征。刘等[190]提出了3DCNN-DQN-RNN用于大规模点云的有效语义解析。该网络首先使用3D CNN网络学习空间分布和颜色特征,DQN进一步用于定位类对象。将最终的级联特征向量馈入残差RNN,以获得最终的分割结果。
Graph-based Methods. 为了捕获3D点云的基本形状和几何结构,有几种方法可以求助于图形网络。 Loic等。 [182]将点云表示为一组互连的简单形状和超点,并使用属性有向图(即超点图)捕获结构和上下文信息。然后,大规模点云分割问题被溅入三个子问题,即几何上均一的分割,超点嵌入和上下文分割。为了进一步改善分割步骤,Loic和Mohamed [183]提出了一种有监督的框架,将点云过度分割为纯超点。该问题被表述为由邻接图构成的深度度量学习问题。此外,还提出了一种图结构的对比损失,以帮助识别对象之间的边界。
为了更好地捕捉高维空间中的局部几何关系,Kang等[191]提出了一种基于图嵌入模块(GEM)和金字塔注意网络(PAN)的PyramNet。 GEM模块将点云公式化为有向无环图,并使用协方差矩阵替换欧几里得距离来构造相邻相似矩阵。PAN模块中使用四种大小不同的内核卷积提取具有不同语义强度的特征。在[184]中,提出了图注意力卷积(GAC)来从局部相邻集合中选择性地学习相关特征。通过基于它们的空间位置和特征差异,将注意力权重动态分配给不同的相邻点和特征通道,可以实现此操作。 GAC可以学习捕获区分特征以进行细分,并且具有与常用CRF模型相似的特征。
Instance Segmentation与语义分割相比,实例分割更具挑战性,因为它需要更准确,更细粒度的点推理。特别是,它不仅需要区分具有不同语义含义的点,而且还需要分离具有相同语义含义的实例。总体而言,现有方法可以分为两类:基于提议的方法和不提议的方法。图11中说明了几种里程碑方法。
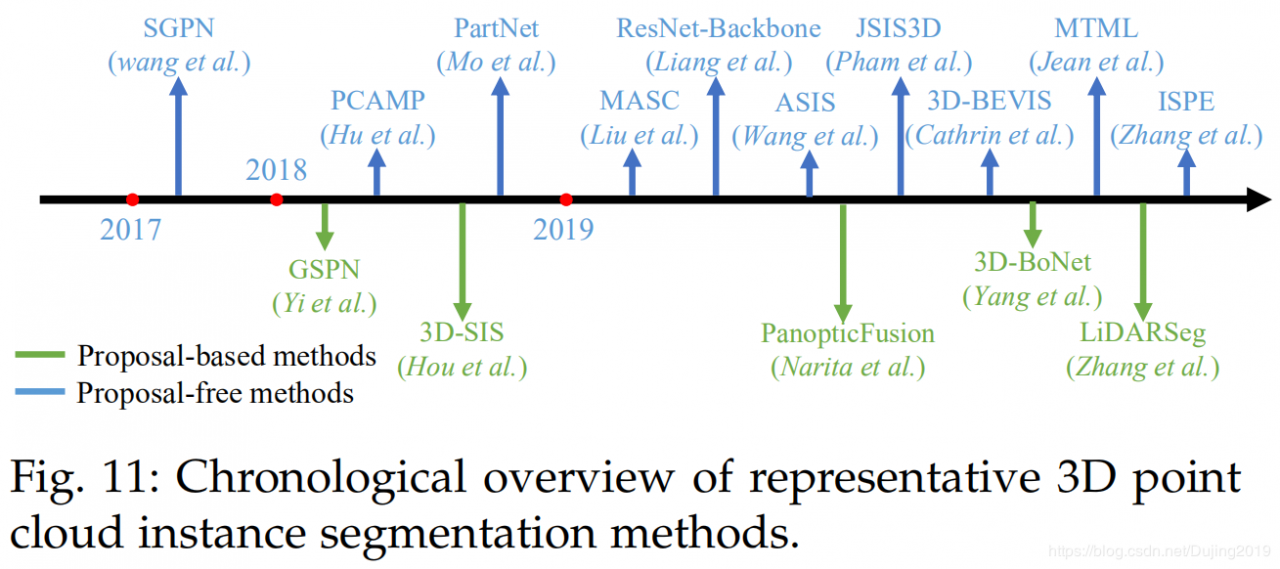
这些方法将实例分割问题转换为两个子任务:3D对象检测和实例掩码预测。侯等人。 [192]提出了一种3D全卷积语义实例分割(3D-SIS)网络,以在RGBD扫描上实现语义实例分割。该网络从颜色和几何特征中学习。与3D对象检测类似,3D区域提议网络(3D-RPN)和3D区域之间的有趣的(3D-RoI)层用于预测边界框位置,对象类标签和实例蒙版。按照综合分析策略,Yi等[193]提出了一种可生成形状的提案网络(GSPN),以生成高对象的3D提案。这些建议由基于区域的PointNet(R-PointNet)进一步完善。最终标签是通过预测每个类标签的每个点的二进制掩码获得的。与直接从点云中回归3D边界框不同,此方法通过增强几何理解来消除大量无意义的建议。通过将2D全景分割扩展到3D映射,Gaku等人。 [194]提出了一种单行立体3D映射系统,以共同实现大规模3D重建,语义标记和实例分割。他们首先利用2D语义和实例分割网络来获得按像素分类的全景标签,然后将这些标签集成到体积图上。完全连接的CRF进一步用于实现精确的分割。该语义映射系统可以实现高质量的语义映射和区分对象识别。杨等[195]提出了一种称为3D-BoNet的单阶段,无锚定且端到端的可训练网络,以在点云上实现实例分割。该方法直接为所有潜在实例回归粗糙的3D边界框,然后利用点级二进制分类器获取实例标签。特别地,将边界框生成任务表述为最佳分配问题。此外。还提出了多准则损失函数来规范生成的边界框。该方法不需要任何后处理,并且计算效率高。张等[196]提出了一个网络,例如分割大型室外LiDAR点云。该方法使用自我关注块在点云的鸟瞰图中学习特征表示。根据预测的水平中心和高度限制获得最终实例标签。
总体而言,基于提议的方法直观而直接,并且实例分割结果通常具有良好的客观性。但是,这些方法需要多阶段的培训和修剪多余的建议。因此,它们通常很耗时且计算量大。
Proposal-free MethodsProposal-free方法[197],[198],[199],[200],[201],[202]没有对象检测模块。相反,他们通常将实例分割视为语义分割之后的后续聚类步骤。特别是,大多数现有方法都是基于这样的假设,即属于同一实例的点应具有非常相似的特征。因此,这些方法主要集中于判别特征学习和点分组。
在一项开创性的工作中,Wang等[197]首先引入了一个相似性团体提案网络(SGPN)。该方法首先学习每个点的特征和语义图,然后引入一个相似度矩阵来表示每个配对特征之间的相似度。为了学习更多区分特征,他们使用双铰损失来相互调整相似度矩阵和语义分割结果。最后,采用启发式和非最大抑制方法将相似点合并为实例。自从相似矩阵的构造需要大量的内存消耗,这种方法的可扩展性受到限制。同样,刘等[201]首先利用子流形稀疏卷积[155]来预测每个体素的语义分数和相邻体素之间的亲和力。然后,他们引入了一种聚类算法,根据预测的亲和力和网格拓扑将点分组为实例。此外,梁等[202]提出了一种结构可识别的损失,用于判别性嵌入的学习。这种损失既考虑了特征的相似性,又考虑了点之间的几何关系。基于注意力的图CNN进一步用于通过汇总来自邻居的不同信息来自适应地精炼所学习的特征。
由于点的语义类别和实例标签通常相互依赖,因此提出了几种方法来将这两个任务耦合为一个任务。 Wang等。 [198]通过引入端到端且可学习的关联分段实例和语义(ASIS)模块,将这两个任务集成在一起。实验表明,通过此ASIS模块,语义特征和实例特征可以相互支持,从而提高性能。同样,Pham等[199]首先引入了多任务逐点网络(MT-PNet)来为每个点分配标签,并通过引入判别性损失来对嵌入特征空间进行正则化[203]。然后,他们将预测的语义标签和嵌入融合到多值条件随机字段(MV-CRF)模型中,以进行联合优化。最后,利用均值场变分推理产生语义标签和实例标签。 Hu等[204]首先提出了一种动态区域增长(DRG)方法,将点云动态分离为一组不相交的补丁,然后使用无监督的K-means ++算法对所有这些补丁进行分组。然后在补丁之间的上下文信息的指导下执行多尺度补丁分段。最后,将这些带标签的补丁合并到对象级别,以获得最终的语义和实例标签。
为了在完整的3D场景上实现实例分割,Cathrin等[200]提出了一种混合的2D-3D网络,可以从BEV表示和点云的局部几何特征共同学习全局一致的实例特征。然后将学习到的特征进行组合以实现语义和实例分割。注意,不是启发式GroupMerging算法[197],而是更灵活的Meanshift [205]算法用于将这些点分组为实例。替代地,还引入了多任务学习来进行实例分割。 Jean等[206]学习了每个实例的独特功能嵌入和指向对象中心的方向信息。提出了特征嵌入损失和方向损失来调整潜在特征空间中学习的特征嵌入。采用均值漂移聚类和非最大抑制将体素分组为实例。这种方法可以达到ScanNet [8]基准的最新性能。此外,预测的方向信息对于确定实例的边界特别有用。张等[207]将概率嵌入引入到点云的实例分割中。该方法还结合了不确定性估计,并为聚类步骤提出了新的损失函数。
总之,proposal-free methods 不需要计算上昂贵的region-proposal组件。但是,由于这些方法未明确检测对象边界,因此由这些方法分组的实例分割的客观性通常较低。
Part Segmentation3D形状的零件分割难度是双重的。首先,具有相同语义标签的形状零件具有较大的几何变化和模糊性。其次,该方法应对噪声和采样具有鲁棒性。
[208]提出了VoxSegNet 以在有限解决方案下对3D体素化数据实现细粒度的零件分割。提出了一种空间密集提取(SDE)模块(由堆叠的残差残差块组成),以从稀疏体积数据中提取多尺度判别特征。通过逐步应用注意力特征聚合(AFA)模块,可以对学习的特征进行进一步的加权和融合。 Evangelos等[209]结合FCN和基于表面的CRF来实现端到端3D零件分割。他们首先从多个视图生成图像以获得最佳的表面覆盖率,然后将这些图像输入2D网络以生成置信度图。然后,这些置信度图由基于表面的CRF聚合,后者负责对整个场景进行一致的标记。 Yi等[210]引入了一种同步频谱CNN(SyncSpecCNN)来对不规则形状和非同构形状图进行卷积。为了解决零件的多尺度分析和形状间的信息共享问题,引入了卷积核和频谱变换器网络的频谱参数化。
Wang等[211]首先通过引入形状完全卷积网络(SFCN)并采用三个低级几何特征作为其输入,在3D网格上执行形状分割。然后,他们利用基于投票的多标签图割来进一步细化细分结果。朱等[212]提出了一种用于3D形状共分割的弱监督CoSegNet。该网络将未分割的3D点云形状的集合作为输入,并通过迭代地最小化组一致性损失来生成形状零件标签。类似于CRF,提出了一个预训练的零件细化网络,以进一步细化和去除零件提案的噪声。 Chen等[213]提出了一种分支自动编码器网络(BAE-NET),用于无监督,单发和弱监督的3D形状共分割。该方法将形状共分割任务公式化为表示学习问题,旨在通过最大程度地减少形状重构损失来找到最简单的零件表示。基于编码器-解码器体系结构,该网络的每个分支都可以学习特定零件形状的紧凑表示。然后将从每个分支学习的特征和点坐标馈送到解码器以生成二进制值(指示该点是否属于此部分)。该方法具有良好的泛化能力,可以处理大型3D形状集合(多达5000多种形状)。但是,它对初始参数敏感,并且没有将形状语义合并到网络中,这阻碍了该方法在每次迭代中获得可靠且稳定的估计。
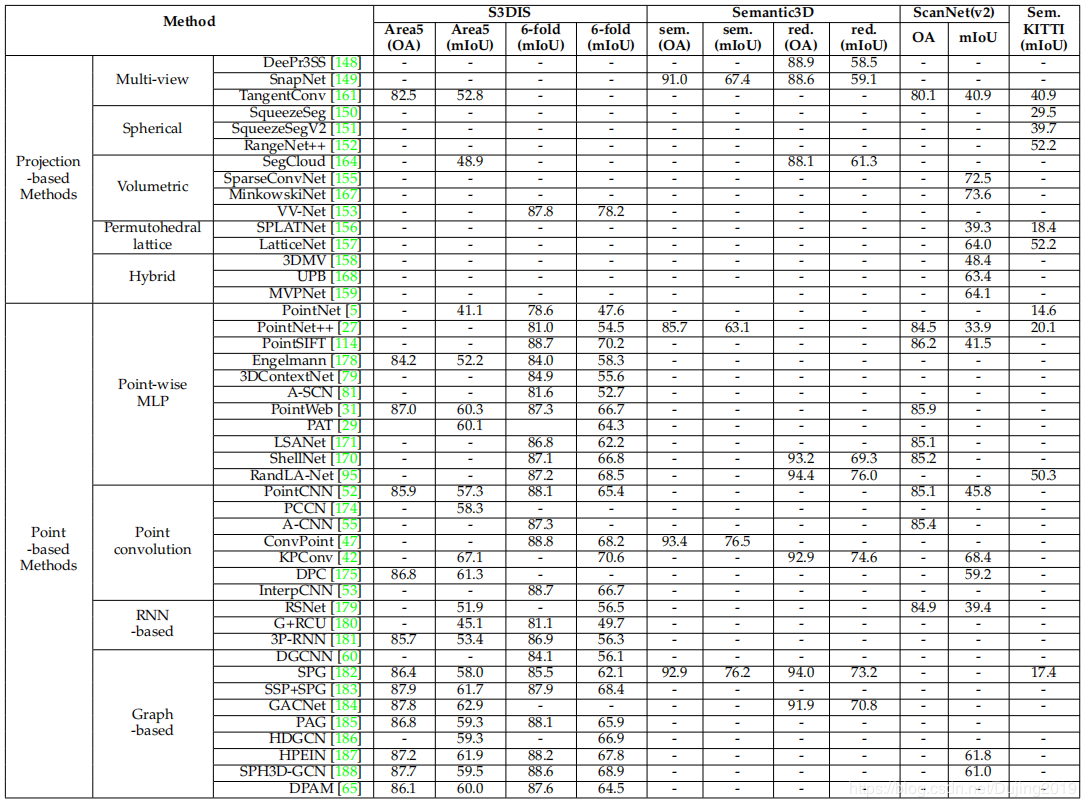
Summary表4显示了通过现有标准(包括S3DIS [176],Semantic3D [9],ScanNet [102]和SemanticKITTI [177])获得的结果。以下问题需要进一步调查:
基于点的网络是研究最频繁的方法。但是,点表示自然不具有显式的相邻信息,大多数现有的基于点的方法都必须诉诸昂贵的邻居搜索机制(例如KNN [52]或Ball查询[27])。这会固有地限制这些方法的效率,因为邻居搜索机制既需要很高的计算成本,又需要不规则的内存访问[214]。 从不平衡数据中学习仍然是点云分割中一个具有挑战性的问题。尽管有几种方法[42],[170],[182]取得了显着的总体表现,但它们在少数群体中的表现仍然有限。例如,RandLA-Net [95]在Semantic3D的reduced8子集上实现了76.0%的总体IoU,但在Hardscape类上却达到了41.1%的非常低的IOU。 现有的大多数方法[5],[27],[52],[170],[171]都适用于小点云(例如,具有4096个点的1m×1m)。实际上,由深度传感器获取的点云通常是巨大且大规模的。因此,期望进一步研究大规模点云的有效分割问题。 少数著作[145],[146],[167]已开始从动态点云中学习时空信息。预期时空信息可以帮助提高后续任务的性能,例如3D对象识别,分割和完成。
[148] F. J. Lawin, M. Danelljan, P . Tosteberg, G. Bhat, F. S. Khan, and M. Felsberg, “Deep projective 3D semantic segmentation,” in Proceedings of International Conference on Computer Analysis of Images and Patterns, 2017, pp. 95–107. 13, 17
[149] A. Boulch, B. Le Saux, and N. Audebert, “Unstructured point cloud semantic labeling using deep segmentation networks.” in Proceedings of the Eurographics Workshop on 3D Object Retrieval, 2017. 13, 17 [150] B. Wu, A. Wan, X. Yue, and K. Keutzer, “SqueezeSeg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3D lidar point cloud,” in ICRA, 2018, pp. 1887–1893. 13, 14, 17
[151] B. Wu, X. Zhou, S. Zhao, X. Yue, and K. Keutzer, “SqueezeSegV2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud,” in ICRA, 2019, pp. 4376–4382. 13, 14, 17
[152] A. Milioto, I. Vizzo, J. Behley , and C. Stachniss, “Rangenet++: Fast and accurate lidar semantic segmentation,” in IROS, 2019. 13, 14, 17
[153] H.-Y . Meng, L. Gao, Y . Lai, and D. Manocha, “VV-Net: V oxel vae net with group convolutions for point cloud segmentation,” arXiv preprint arXiv:1811.04337, 2018. 13, 14, 17
[154] D. Rethage, J. Wald, J. Sturm, N. Navab, and F. Tombari, “Fullyconvolutional point networks for large-scale point clouds,” in ECCV, 2018, pp. 596–611. 13, 14
[155] B. Graham, M. Engelcke, and L. van der Maaten, “3D semantic segmentation with submanifold sparse convolutional networks,” in CVPR, 2018, pp. 9224–9232. 13, 15, 17, 18
[156] H. Su, V . Jampani, D. Sun, S. Maji, E. Kalogerakis, M.-H. Yang, and J. Kautz, “Splatnet: Sparse lattice networks for point cloud processing,” in CVPR, 2018, pp. 2530–2539. 13, 15, 17
[157] R. A. Rosu, P . Schütt, J. Quenzel, and S. Behnke, “Latticenet: Fast point cloud segmentation using permutohedral lattices,” arXiv preprint arXiv:1912.05905, 2019. 13, 15, 17
[158] A. Dai and M. Nießner, “3DMV: Joint 3d-multi-view prediction for 3D semantic scene segmentation,” in ECCV, 2018, pp. 452– 468. 13, 15, 17
[159] M. Jaritz, J. Gu, and H. Su, “Multi-view pointnet for 3D scene understanding,” in ICCVW, 2019. 13, 15, 17 [160] N. Audebert, B. Le Saux, and S. Lefèvre, “Semantic segmentation of earth observation data using multimodal and multi-scale deep networks,” in ACCV, 2016, pp. 180–196. 13
[161] M. Tatarchenko, J. Park, V . Koltun, and Q.-Y . Zhou, “Tangent convolutions for dense prediction in 3d,” in CVPR, 2018, pp. 3887–3896. 14, 17
[162] F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally , and K. Keutzer, “SqueezeNet: Alexnet-level accuracy with 50x fewer parameters and < 0.5 MB model size,” arXiv preprint arXiv:1602.07360, 2016. 14 [163] J. Huang and S. You, “Point cloud labeling using 3D convolutional neural network,” in ICPR, 2016, pp. 2670–2675. 14
[164] L. T chapmi, C. Choy , I. Armeni, J. Gwak, and S. Savarese, “SEGCloud: Semantic segmentation of 3D point clouds,” in 3DV, 2017, pp. 537–547. 14, 17
[165] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in CVPR, 2015, pp. 3431–3440. 14
[166] A. Dai, D. Ritchie, M. Bokeloh, S. Reed, J. Sturm, and M. Nießner, “ScanComplete: Large-scale scene completion and semantic segmentation for 3D scans,” in CVPR, 2018, pp. 4578–4587. 14
[167] C. Choy , J. Gwak, and S. Savarese, “4D spatio-temporal convnets: Minkowski convolutional neural networks,” arXiv preprint arXiv:1904.08755, 2019. 15, 17, 19
[168] H. Chiang, Y . Lin, Y . Liu, and W. H. Hsu, “A unified point-based framework for 3D segmentation,” arXiv preprint arXiv:1908.00478, 2019. 15, 17
[169] F. Engelmann, T. Kontogianni, J. Schult, and B. Leibe, “Know what your neighbors do: 3D semantic segmentation of point clouds,” in ECCVW, 2018. 15
[170] Z. Zhang, B.-S. Hua, and S.-K. Yeung, “ShellNet: Efficient point cloud convolutional neural networks using concentric shells statistics,” arXiv preprint arXiv:1908.06295, 2019. 15, 17, 19
[171] L.-Z. Chen, X.-Y . Li, D.-P . Fan, M.-M. Cheng, K. Wang, and S.P . Lu, “LSANet: Feature learning on point sets by local spatial attention,” arXiv preprint arXiv:1905.05442, 2019. 16, 17, 19
[172] C. Zhao, W. Zhou, L. Lu, and Q. Zhao, “Pooling scores of neighboring points for improved 3D point cloud segmentation,” in ICIP, 2019, pp. 1475–1479. 16
[173] R. Arandjelovic, P . Gronat, A. Torii, T. Pajdla, and J. Sivic, “NetVLAD: CNN architecture for weakly supervised place recognition,” in CVPR, 2016, pp. 5297–5307. 16
[174] S. Wang, S. Suo, W.-C. Ma, A. Pokrovsky , and R. Urtasun, “Deep parametric continuous convolutional neural networks,” in CVPR, 2018, pp. 2589–2597. 16, 17
[175] F. Engelmann, T. Kontogianni, and B. Leibe, “Dilated point convolutions: On the receptive field of point convolutions,” arXiv preprint arXiv:1907.12046, 2019. 16, 17
[176] I. Armeni, O. Sener, A. R. Zamir, H. Jiang, I. Brilakis, M. Fischer, and S. Savarese, “3D semantic parsing of large-scale indoor spaces,” in CVPR, 2016, pp. 1534–1543. 17, 19
[177] J. Behley , M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, and J. Gall, “SemanticKITTI: A dataset for semantic scene understanding of lidar sequences,” in ICCV, 2019. 17, 19
[178] F. Engelmann, T. Kontogianni, J. Schult, and B. Leibe, “Know what your neighbors do: 3d semantic segmentation of point clouds,” in ECCV, 2018, pp. 0–0. 17
[179] Q. Huang, W. Wang, and U. Neumann, “Recurrent slice networks for 3D segmentation of point clouds,” in CVPR, 2018, pp. 2626– 2635. 16, 17
[180] F. Engelmann, T. Kontogianni, A. Hermans, and B. Leibe, “Exploring spatial context for 3D semantic segmentation of point clouds,” in ICCV, 2017, pp. 716–724. 16, 17
[181] X. Ye, J. Li, H. Huang, L. Du, and X. Zhang, “3D recurrent neural networks with context fusion for point cloud semantic segmentation,” in ECCV, 2018, pp. 403–417. 16, 17
[182] L. Landrieu and M. Simonovsky , “Large-scale point cloud semantic segmentation with superpoint graphs,” in CVPR, 2018, pp. 4558–4567. 16, 17, 19
[183] L. Landrieu and M. Boussaha, “Point cloud oversegmentation with graph-structured deep metric learning,” arXiv preprint arXiv:1904.02113, 2019. 16, 17 [184] L. Wang, Y . Huang, Y . Hou, S. Zhang, and J. Shan, “Graph attention convolution for point cloud semantic segmentation,” in CVPR, 2019, pp. 10 296–10 305. 16, 17
[185] L. Pan, C.-M. Chew, and G. H. Lee, “Pointatrousgraph: Deep hierarchical encoder-decoder with atrous convolution for point clouds,” arXiv preprint arXiv:1907.09798, 2019. 17
[186] Z. Liang, M. Yang, L. Deng, C. Wang, and B. Wang, “Hierarchical depthwise graph convolutional neural network for 3d semantic segmentation of point clouds,” in ICRA. IEEE, 2019, pp. 8152– 8158. 17 [187] L. Jiang, H. Zhao, S. Liu, X. Shen, C.-W. Fu, and J. Jia, “Hierarchical point-edge interaction network for point cloud semantic segmentation,” in ICCV, 2019, pp. 10 433–10 441. 17
[188] H. Lei, N. Akhtar, and A. Mian, “Spherical convolutional neural network for 3d point clouds,” 2018. 17 [189] Z. Zhao, M. Liu, and K. Ramani, “DAR-Net: Dynamic aggregation network for semantic scene segmentation,” arXiv preprint arXiv:1907.12022, 2019. 16
[190] F. Liu, S. Li, L. Zhang, C. Zhou, R. Ye, Y . Wang, and J. Lu, “3DCNN-DQN-RNN: A deep reinforcement learning framework for semantic parsing of large-scale 3D point clouds,” in ICCV, 2017, pp. 5678–5687. 16
[191] K. Zhiheng and L. Ning, “PyramNet: Point cloud pyramid attention network and graph embedding module for classification and segmentation,” arXiv preprint arXiv:1906.03299, 2019. 16
[192] J. Hou, A. Dai, and M. Nießner, “3D-SIS: 3D semantic instance segmentation of RGB-D scans,” in CVPR, 2019, pp. 4421–4430. 17
[193] L. Yi, W. Zhao, H. Wang, M. Sung, and L. J. Guibas, “GSPN: Generative shape proposal network for 3D instance segmentation in point cloud,” in CVPR, 2019, pp. 3947–3956. 17 [194] G. Narita, T. Seno, T. Ishikawa, and Y . Kaji, “PanopticFusion: Online volumetric semantic mapping at the level of stuff and things,” arXiv preprint arXiv:1903.01177, 2019. 18
[195] B. Yang, J. Wang, R. Clark, Q. Hu, S. Wang, A. Markham, and N. Trigoni, “Learning object bounding boxes for 3D instance segmentation on point clouds,” arXiv preprint arXiv:1906.01140, 2019. 18 [196] F. Zhang, C. Guan, J. Fang, S. Bai, R. Yang, P . Torr, and V . Prisacariu, “Instance segmentation of lidar point clouds,” in ICRA, 2020. 18
[197] W. Wang, R. Yu, Q. Huang, and U. Neumann, “SGPN: Similarity group proposal network for 3D point cloud instance segmentation,” in CVPR, 2018, pp. 2569–2578. 18
[198] X. Wang, S. Liu, X. Shen, C. Shen, and J. Jia, “Associatively segmenting instances and semantics in point clouds,” in CVPR, 2019, pp. 4096–4105. 18
[199] Q.-H. Pham, T. Nguyen, B.-S. Hua, G. Roig, and S.-K. Yeung, “JSIS3D: Joint semantic-instance segmentation of 3D point clouds with multi-task pointwise networks and multi-value conditional random fields,” in CVPR, 2019, pp. 8827–8836. 18
[200] C. Elich, F. Engelmann, J. Schult, T. Kontogianni, and B. Leibe, “3D-BEVIS: Birds-eye-view instance segmentation,” arXiv preprint arXiv:1904.02199, 2019. 18
[201] C. Liu and Y . Furukawa, “MASC: Multi-scale affinity with sparse convolution for 3D instance segmentation,” arXiv preprint arXiv:1902.04478, 2019. 18
[202] Z. Liang, M. Yang, and C. Wang, “3D graph embedding learning with a structure-aware loss function for point cloud semantic instance segmentation,” arXiv preprint arXiv:1902.05247, 2019. 18
[203] B. De Brabandere, D. Neven, and L. Van Gool, “Semantic instance segmentation with a discriminative loss function,” arXiv preprint arXiv:1708.02551, 2017. 18
[204] S.-M. Hu, J.-X. Cai, and Y .-K. Lai, “Semantic labeling and instance segmentation of 3D point clouds using patch context analysisand multiscale processing,” IEEE transactions on visualization and computer graphics, 2018. 18
[205] D. Comaniciu and P . Meer, “Mean shift: A robust approach toward feature space analysis,” IEEE TP AMI, no. 5, pp. 603–619, 2002. 18 [206] J. Lahoud, B. Ghanem, M. Pollefeys, and M. R. Oswald, “3D instance segmentation via multi-task metric learning,” arXiv preprint arXiv:1906.08650, 2019. 18
[207] B. Zhang and P . Wonka, “Point cloud instance segmentation using probabilistic embeddings,” arXiv preprint arXiv:1912.00145, 2019. 18 [208] Z. Wang and F. Lu, “V oxSegNet: V olumetric CNNs for semantic part segmentation of 3D shapes,” IEEE transactions on visualization and computer graphics, 2019. 19
[209] E. Kalogerakis, M. Averkiou, S. Maji, and S. Chaudhuri, “3D shape segmentation with projective convolutional networks,” in CVPR, 2017, pp. 3779–3788. 19
[210] L. Yi, H. Su, X. Guo, and L. J. Guibas, “SyncSpecCNN: Synchronized spectral CNN for 3D shape segmentation,” in CVPR, 2017, pp. 2282–2290. 19 [211] P . Wang, Y . Gan, P . Shui, F. Yu, Y . Zhang, S. Chen, and Z. Sun, “3D shape segmentation via shape fully convolutional networks,” Computers & Graphics, vol. 70, pp. 128–139, 2018. 19
[212] C. Zhu, K. Xu, S. Chaudhuri, L. Yi, L. Guibas, and H. Zhang, “CoSegNet: Deep co-segmentation of 3D shapes with group consistency loss,” arXiv preprint arXiv:1903.10297, 2019. 19
[213] Z. Chen, K. Yin, M. Fisher, S. Chaudhuri, and H. Zhang, “BAENET: Branched autoencoder for shape co-segmentation,” arXiv preprint arXiv:1903.11228, 2019. 19
[214] Z. Liu, H. Tang, Y . Lin, and S. Han, “Point-Voxel CNN for efficient 3D deep learning,” in NeurIPS, 2019, pp. 963–973. 19
作者:Dujing2019