CKA真题:题目和解析-5
所有命令都验证过,有更好的方式,欢迎留言~~~
CKA 习题和真题汇总
CKA考试经验:报考和考纲
CKA :2019年12月英文原题和分值
CKA考试习题:K8S基础概念--API 对象 CKA考试习题:调度管理- nodeAffinity、podAffinity、Taints CKA考试习题:K8S日志、监控与应用管理 CKA考试习题:网络管理-Pod网络、Ingress、DNS CKA考试习题:存储管理-普通卷、PV、PVC CKA考试习题:安全管理--Network Policy、serviceaccount、clusterrole CKA考试习题:k8s故障排查 CKA真题:题目和解析-1 CKA真题:题目和解析-2 CKA真题:题目和解析-3 CKA真题:题目和解析-4 CKA真题:题目和解析-5 CKA真题:题目和解析-6CKA真题:手动配置TLS BootStrap
更多CKA资料或交流:可加 wei xin :wyf19910905
17、nslookup查找service和pod的DNS记录Set configuration context $ kubectl config use-context k8s
Create a deployment as follows
Name: nginx-dns
Exposed via a service: nginx-dns
Ensure that the service & pod are accessible via their respective DNS records
The container(s) within any pod(s) running as a part of this deployment should use the nginx image
Next,use the utiliity nslookup to look up the DNS records of the service & pod and write the output to /opt/service.dns and /opt/pod.dns respectively
Ensure you use the busybox:1.28 image (or earliser) for any testing, an the latest release has an unpstream bug which impacts the use of nslookup
创建一个deployment 名:nginx-dns ,发 布一个服务,名为: nginx-dns
确保service 和pod可以通过各自的DNS记录访问
作为deployment的一部分运行的任何pod中的容器都应该使用nginx镜像
接下来,使用实用程序nslookup查找service和pod的DNS记录,并将输出分别写入/opt/service.dns和/opt/pod.dns
确保您使用busybox:1.28 image(或更早版本)进行任何测试,最新版本有一个unpstream bug,影响nslookup的使用。
答:
#第一步:创建deployment kubectl run nginx-dns --image=nginx #第二步:发布服务 kubectl expose deployment nginx-dns --port=80 #第三步:查询podIP kubectl get pods -o wide (获取pod的ip) 比如Ip是:10.244.1.37 #第四步:使用busybox1.28版本进行测试 #创建一个指定版本的busybox,用于执行nslookup kubectl create -f https://k8s.io/examples/admin/dns/busybox.yaml #将svc的dns记录写入文件中 kubectl exec -ti busybox -- nslookup nginx-dns > 指定文件 #将获取的pod ip地址使用nslookup查找dns记录 kubectl exec -ti busybox -- nslookup > 指定文件18、etcd快照No configuration context change requried for this item
Create a snapshot of the etcd instance running at http://127.0.0.1:2379 saving the snapshot to the file path /data/backup/etcd-snapshot.db
The etcd instance is running etcd version 3.2.18
The following TLS certificates/key are supplied for connnecting to the server with etcdctl
CA certificate:/opt/KUCM00302/ca.crt
Client certificate:/opt/KUCM00302/etcd-client.crt
Client key: /opt/KUCM00302/etcd-client.key
这题是需要用以下的证书和密钥之类的,创建一个snapshot(快照),快照生成完的保存路径为:/data/backup/etcd-snapshot.db
答:
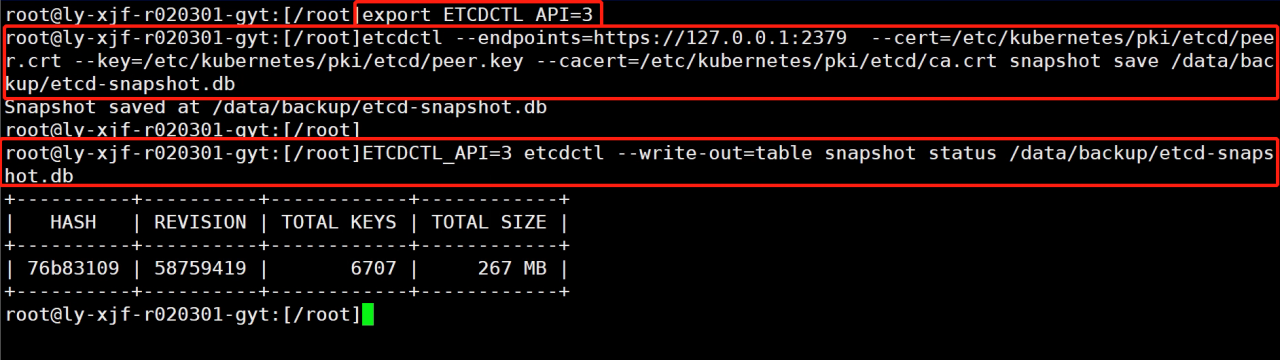
注意:etcd API 又有 v3 和 v2 之分,使用方法不同,如果使用v3请先执行export ETCDCTL_API=3
首先,进入到具体的节点上面去
这一步可以根据题目中的ssh的操作来进行
创建自己的snapshot
# etcdctl --help 再etcdctl snapshot save --help # ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb etcdctl --endpoints=http://127.0.0.1:2379 \ --ca-file=/opt/KUCM00302/ca.crt \ --certfile=/opt/KUCM00302/etcd-client.crt \ --key=/opt/KUCM00302/etcd-client.key snapshot save /data/backup/etcd-snapshot.db将创建好的snapshot输出,如果题目中没有要求输出,则不需要做这一步,但是为了保证解题正确,可以自己输出一下来进行检验。
# verify the snapshot ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshotdb# 输出到指定文件夹 ETCDCTL_API=3 etcdctl --write-out=table snapshot status 上一步保存的文件名 >aim.txtETCD备份 官网链接:
https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#backing-up-an-etcd-cluster
https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/
19、使用 kubectl drain 从集群中移除节点Set configuration context $ kubectl config use-context ek8s
Set the node labelled with name=ek8s-node-1 as unavailable and reschedule all the pods running on it
把标签为name=ek8s-node-1的node 设置为unavailable和重新安排所有运行在上面的pods
答:
使用
kubectl drain优雅的结束节点上的所有 pod 并同时标记节点为不可调度:kubectl drain $NODENAME在您正试图使节点离线时,这将阻止新的 pod 落到它们上面。
对于有 replica set 的 pod 来说,它们将会被新的 pod 替换并且将被调度到一个新的节点。此外,如果 pod 是一个 service 的一部分,则客户端将被自动重定向到新的 pod。
对于没有 replica set 的 pod,您需要手动启动 pod 的新副本,并且如果它不是 service 的一部分,您需要手动将客户端重定向到这个 pod。
在节点上执行维护工作。
重新使节点可调度:
kubectl uncordon $NODENAME方式1kubectl drain nodex
kubectl uncordon nodex
官网链接 https://kubernetes.io/docs/concepts/architecture/nodes/kubectl get nodes -l name=ek8s-node-1 # #直接drain会出错,需要添加--ignore-daemonsets --delete-local-data参数 kubectl drain wk8s-node-1 --ignore-daemonsets=true --delete-local-data=true --force=true方式2:使用taint将node设置成unscheduler,在官网上面搜索taint,点进去第一个链接即可。 https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/#concepts
kubectl taint nodes node1 key=value:NoExecute kubectl taint nodes node1 key:NoExecute-NoSchedule 与 NoExecute 的区别:NoSchedule 只会保证后面部署的pod不会部署当前节点,而不能驱除之前已经部署在该节点的pod。而 NoExecute 可以。
20、修复notready状态 的节点Set configuration context $ kubectl config use-context wk8s
A Kubernetes worker node,labelled with name=wk8s-node-0 is in state NotReady.
Investigate why this is the case,and perform any appropriate steps to bring the node to a Ready state,ensuring that any chanages are made permanent.
Hints:
You can ssh to the failed node using $ ssh wk8s-node-0
You can assume elevated privileges on the node with the following command $ sudo -i
wk8s集群里面有一个标签为wk8s-node-0的节点是notready状态 ,找到原因,恢复Ready状态,所做的改变要是持久的
答:
kubectl get node # 查看一个node 是NotReady # ssh上去 ssh wk8s-node-0 # 如果不是root用户 用 sudo -I 切换到root用户 sudo -i systemctl status kubelet # 发现没有启动 systemctl start kubelet systemctl enable kubelet
作者:琦彦