统计学在测试结果分析中的应用(3)
番外篇:沙堆倾斜
Never recreate places from your memory. Always imagine new places! 不要根据记忆重塑梦境。统统想像出全新的场景。
—— Inception/盗梦空间
前文描述了一个优美的标准沙堆,沙堆拥有完美的对称,美妙的正态曲线恰好在对称中心汇聚在一起。但是对于我们这个注定不存在完美的世界来说,正态曲线也恰似盗梦空间里的梦境——要么大部分情况下不存在,要么稍有外力便山崩瓦解。好比沙漏放在了不够水平的桌面上,我们翻转沙漏,一个小时后,看到沙漏的下半部分形成了一座倾斜的沙堆。此时,正态分布的一切性质、公式以及检验还对这堆站歪了的沙堆有效吗?
先从已知的一些事实来看看倾斜的沙堆吧,例如统计基本状态下氢原子的电子出现位置,我们知道电子大部分情况下会出现在第一能级上,但也有可能会跃迁至第二能级甚至更高的能级,此时统计电子与原子间的距离,便会出现一条拖着长尾的偏态分布图像。长尾部分当然也包含了重要信息,但当我们仅对大多数情况做统计学判定的时候,偏态分布无疑要比标准正态分布更让人迷惑些。
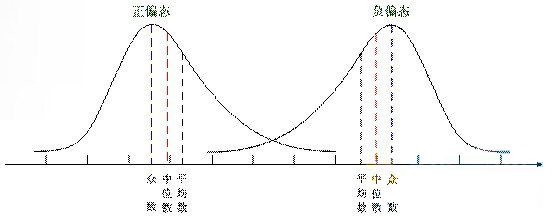
上图列举了偏态分布中几个重要统计学数据的位置。对于标准正态分布来说,计算平均数无疑是该分布的数学期望。但对于偏态分布来说,平均数则只剩下了参考意义——通过平均数与中位数和众数之间的比较来判断偏态分布是正偏态还是负偏态。此时众数成了偏态分布的数学期望,但是仅仅如此武断的说偏态分布的数学期望直接取其众数并不严谨,因为众数所在位置可能不止一个,并且并不能排除出现小概率的众数位置偏移。
这种情况下,比较好的做法是增加样本容量,这样偏度才能被精确的确定下来,偏度系数(Coefficient of skewness)Q的估算公式:
从上面公式可以看出,由于是三次方,数据的正负符号将会被保留下来,当Q<0为负偏,当Q>0为正偏,当Q=0为标准正态分布。
对于有下限或者上限的数据样本来说,形成偏态分布的可能性是相当大的。例如前文提到的测试Linux系统中磁盘的写入速度,物理设备的大写入速度正是可以通过测试获得的写入速度的上限,而由于受到其他因素,如系统调度之类的干扰造成的写入速度下限则会偏离真实写入速度很多。长尾一端必然会落在限制的反方向上。
在软件测试中,为了能够尽量贴近标准正态分布以便于对数据进行分析,我觉得比较方便的做法是测试尽量多的样本,然后通过一些统计学数据来去偏,这里的统计学数据主要是指确定众数所在位置。在找到众数的真实位置之后,其数学期望便也可以确定了。
对于偏态分布,还有一个重要的决定因素是样本容量大小对分布的影响。举例说明:测试10次样本获得一组数据,其中个别数据偏差正常值太多,以至于计算得到的方差过大,样本分布不能满足置信度和极限样本误差的需要。这种情况下,我们有可能的一种做法是人为剔除那些我们看来觉得不可能出现的样本数据。这种做法正确吗?回答是,显然不对。有没有考虑过,我们剔除的数据很可能才是真正的大量数据集中所在?此时通过增加样本容量,不断缩小样本方差才是正确的做法。有可能10次测试中8次数据的集中地,到了100次测试中成了少数派了。
莱昂纳多教导我们“不要根据记忆重塑梦境”,当然也“不要根据直觉重塑数据”,真正的偏态或正态分布恰恰隐藏在茂密的丛林中。
统计学在测试结果分析中的应用(2)