FRN+TLU,小batch size训练的福音
1、解决的问题:BN(Batch Normalization)在mini-batch尺寸太小的时候会降低训练效果,GN(Group Normalization),Batch Renormalization都在解决这些问题,但是达不到BN在大batch上的表现,或在小batch上表现不佳
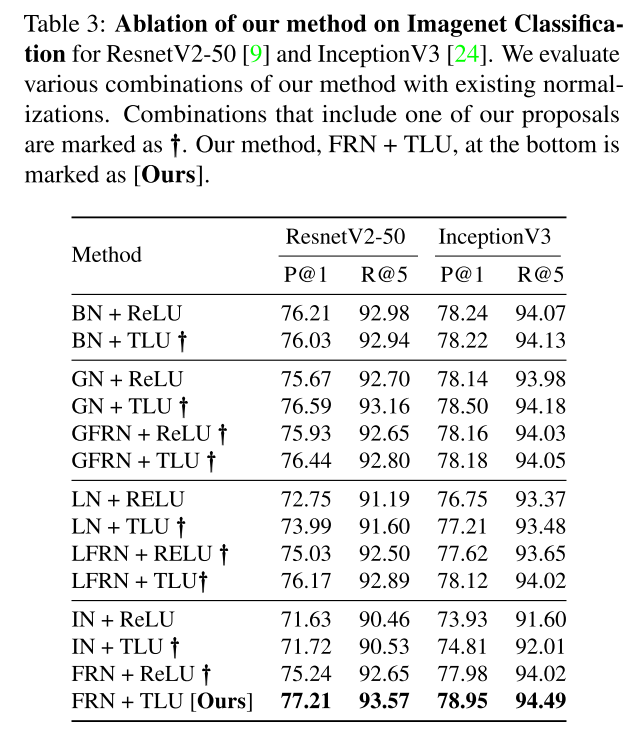
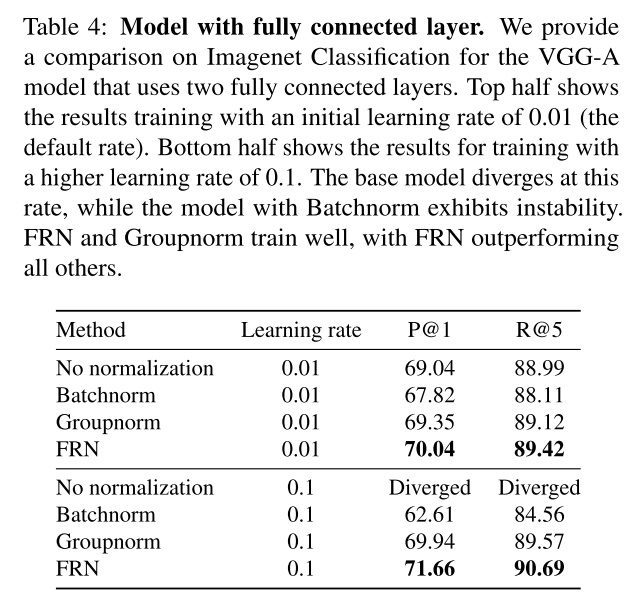
2、FRN表现:FRN结合归一化和激活函数的方式,替代其他的归一化与激活函数的结合,在各个batch size上的表现都更好
3、改进的方向:FRN未来会在NLP领域继续探索
论文图表与内容: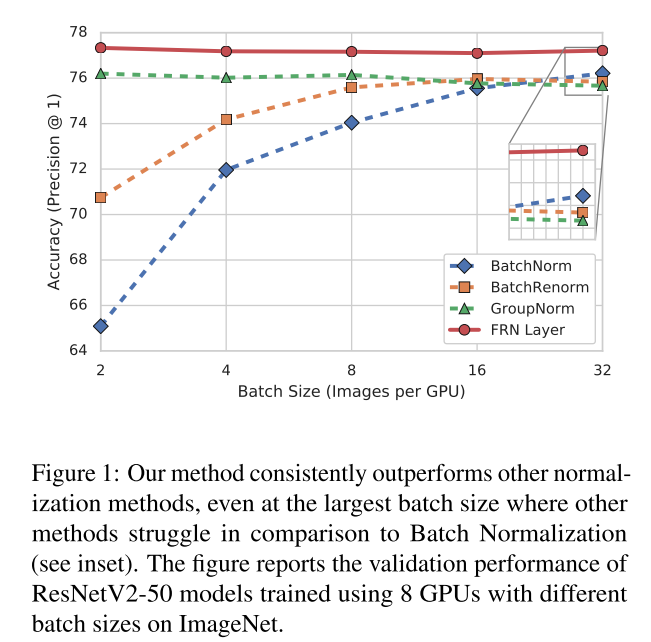
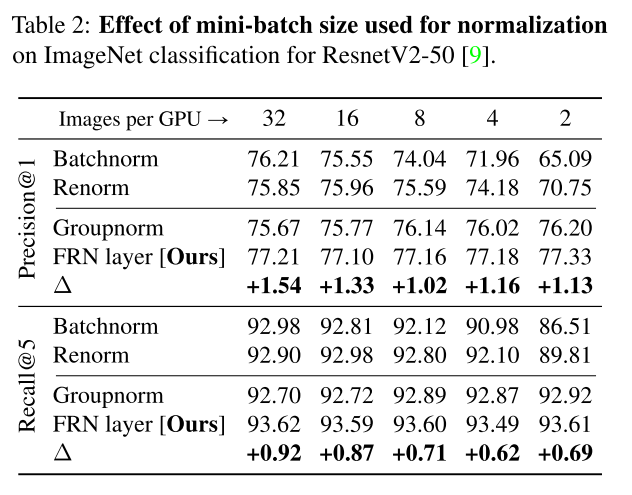
FRN不依赖于batch的设置,在small batch size 和large batch size上表现都很好
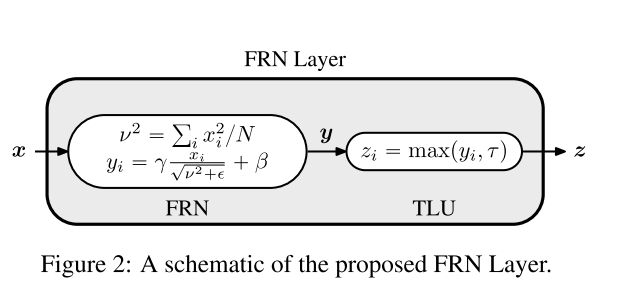
(1)FRN和其他归一化方法一样,消除了在FRN filter的权重和预激活的尺度效应
(2)FRN主要的不同在于没有减去均值(均值在batch上不独立)
(3)FRN是基于每个channel上做的,使得所有的滤波器在最后的模型上有相等重要性
(4)FRN是在空间范围上的全局归一化

v^2是第b个batch point上的第c个channel上w*h个点的均方差,FRN对每个样例的每个channel单独进行归一化,消除了对batch的依赖


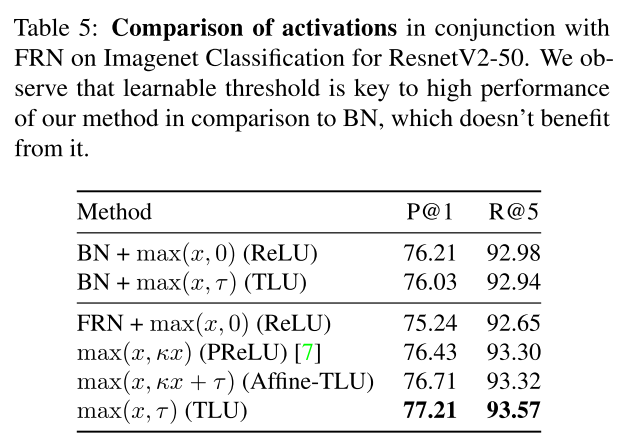
TLU是为了解决FRN没有均值中心而出现的任意偏差,t是可学习的阈值
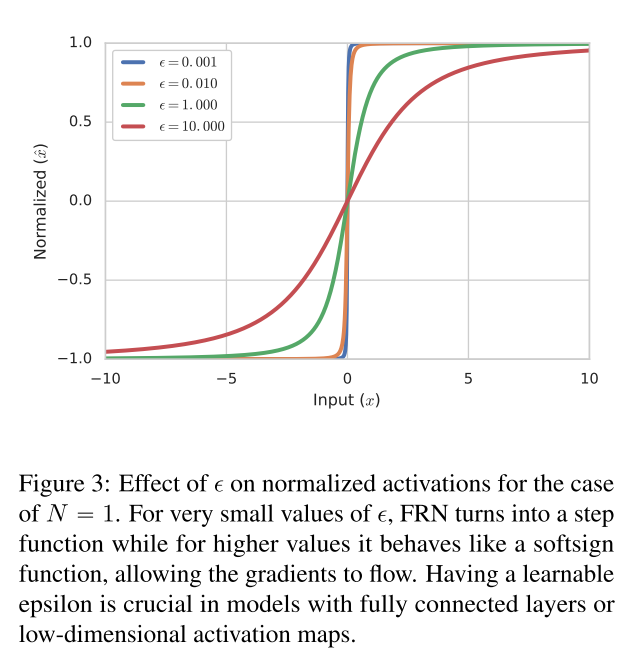
在全连接层或N=1的激活层,FRN会变为图中的情况,当epsilon值较小时,归一化相当于一个符号函数(sign function),这时候梯度几乎为0,严重影响模型训练;当值较大时,曲线变得更圆滑,此时的梯度利于模型学习,此时epsilon变为可学习参数是很重要的

FRN的tf实现
FRN的表现:
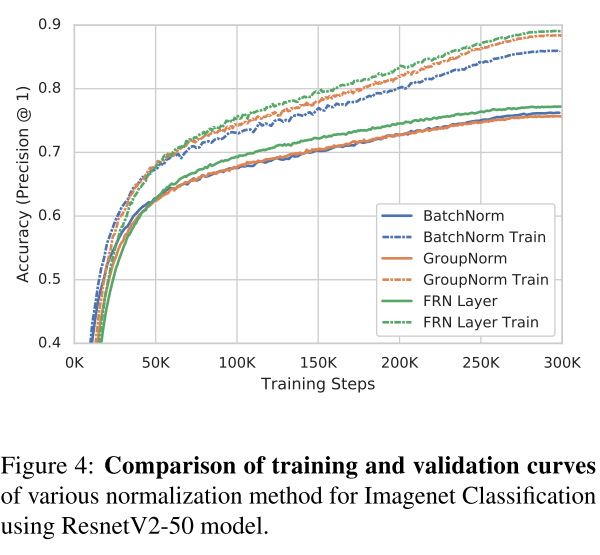

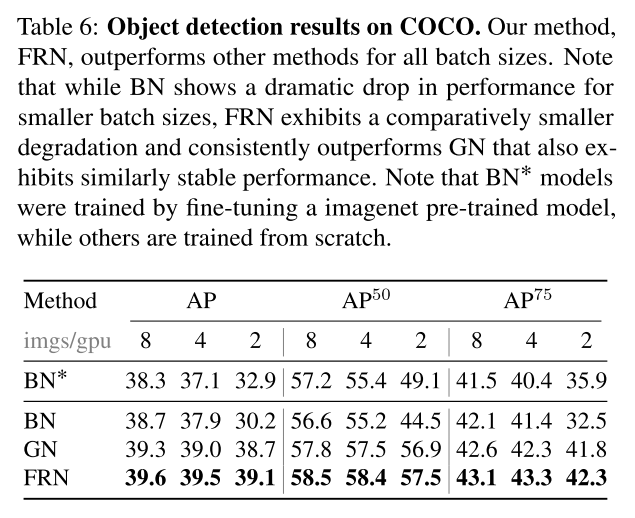
参考文章:https://zhuanlan.zhihu.com/p/69659844
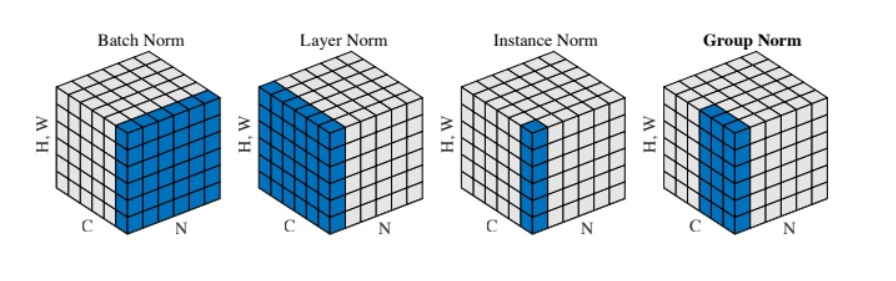

BN:
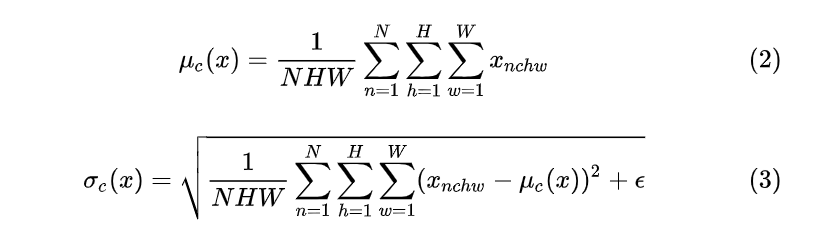
把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。具体公式为:
LN:

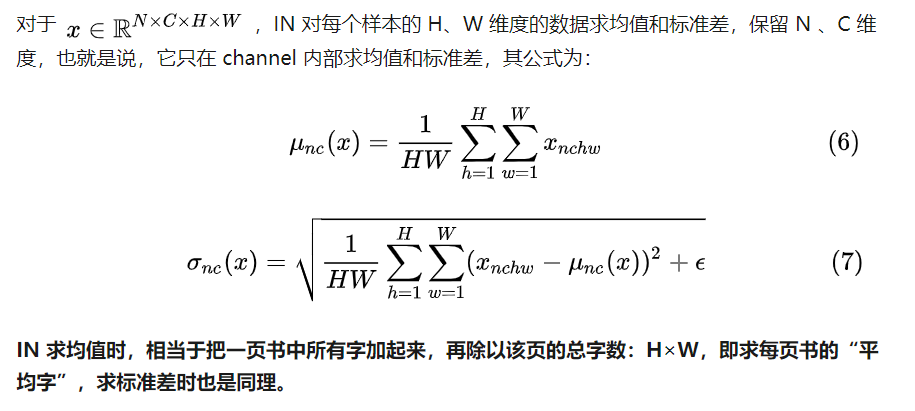
IN:
GN:


作者:Dreamer_Du