小结4:机器翻译相关技术、注意力机制
文章目录机器翻译(MT):1 定义2 Encoder-Decoder3 Seq2Seq4 Beam search注意力机制Transformer
机器翻译(MT):
1 定义
作者:夜猫子科黎
将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
步骤:
encoder:输入到隐藏状态
decoder:隐藏状态到输出
1)encoder:可以是CNN或者RNN,这里我们选用RNN实现,讲信息不断的保存在hidden节点中,进行信息的不断传递;
2)语义编码c:提取汇总信息,一般选用encoder中的最后一个隐藏节点的信息作为语义编码;
3)decoder:一般选用RNN或LSTM等神经网络实现,利用以往的信息c和前一个节点的输出预测当前节点的输出,进而实现seq2seq模型的实现:
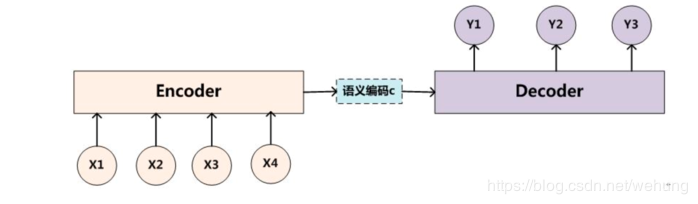
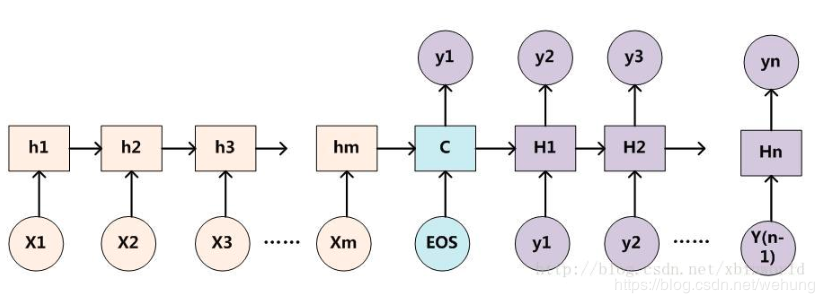
https://blog.csdn.net/xbinworld/article/details/54605408
大致代码结构:
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
3 Seq2Seq
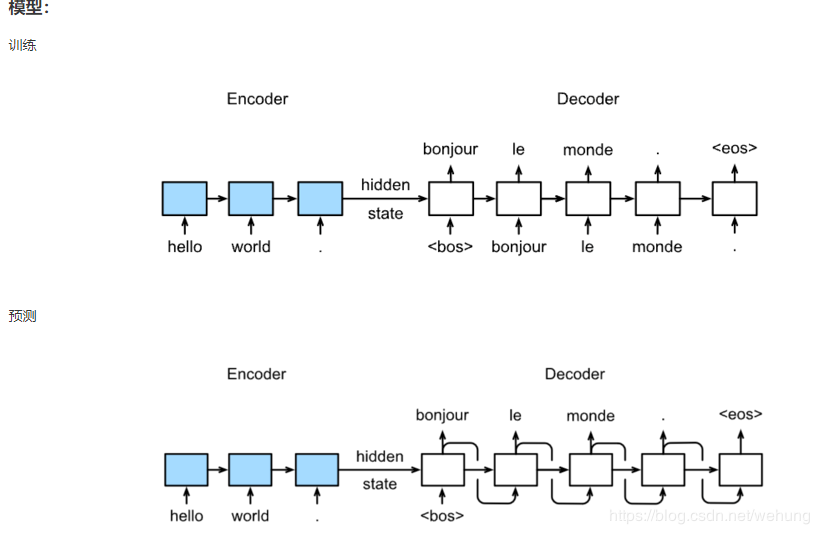
其中利用Embedding技术,将单词进行嵌入
同时使用LSTM网络进行训练与预测
1首先说下贪婪搜索
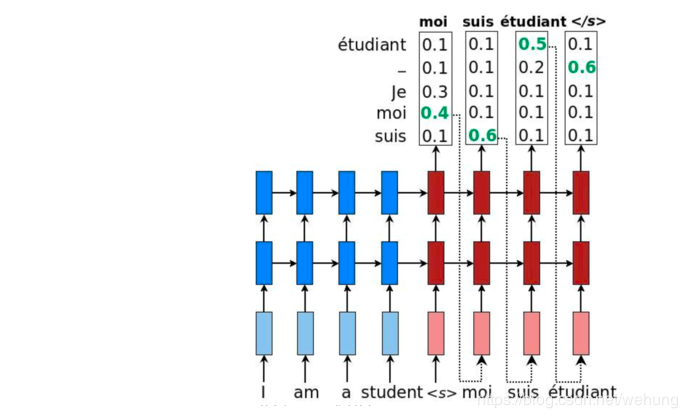
每次选择预测概率最大的词,作为输入
2 束搜索
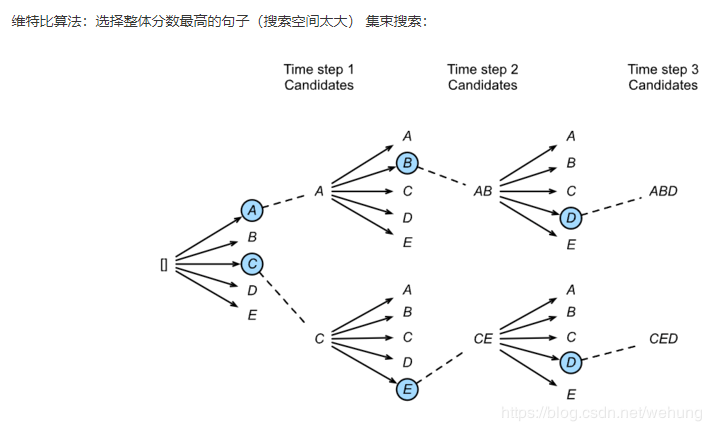 每次选择多个
每次选择多个
https://daiwk.github.io/posts/nlp-self-attention-models.html

点积计算方法,还有MLP等、以及自注意力
待续
作者:夜猫子科黎
相关文章
Coral
2021-01-26
Belle
2020-06-06
Madeleine
2021-06-10
Serafina
2023-05-17
Tertia
2023-05-17
Kefira
2023-05-18
Pandora
2023-05-21
Lillian
2023-07-17
Victoria
2023-07-19
Oria
2023-07-20
Elsa
2023-07-20
Gilana
2023-07-20
Gamila
2023-07-20
Mora
2023-07-20
Pelagia
2023-07-20
Glory
2023-07-20
Galatea
2023-07-20
Penny
2023-07-20