pandas常用函数学习,从文件读取输出过程中学会处理数据
关注微信公众号:Excel办公小技巧
上一篇文章通过一些简单的例子了解了pandas,今天将重点介绍下pandas读取数据常用的函数:read_csv,并通过to_csv函数输出数据到文件辅助理解。read_csv可用来读取url和带有分隔符csv格式文件等,参数如下:
pandas.read_csv(filepath_or_buffer:Union[str,pathlib.Path,IO[~AnyStr]],sep=',',delimiter=None,header='infer',names=None,index_col=None,usecols=None,squeeze=False,prefix=None,mangle_dupe_cols=True,dtype=None,engine=None,converters=None,true_values=None,false_values=None,skipinitialspace=False,skiprows=None,skipfooter=0,nrows=None,na_values=None,keep_default_na=True,na_filter=True,verbose=False,skip_blank_lines=True,parse_dates=False,infer_datetime_format=False,keep_date_col=False,date_parser=None,dayfirst=False,cache_dates=True,iterator=False,chunksize=None,compression='infer',thousands=None,decimal:str='.',lineterminator=None,quotechar='"',quoting=0,doublequote=True,escapechar=None,comment=None,encoding=None,dialect=None,error_bad_lines=True,warn_bad_lines=True,delim_whitespace=False,low_memory=True,memory_map=False, float_precision=None)
充分理解读取函数的参数,有助于我们在第一步读取阶段,就可以将数据问题处理一大半。
一、数据读取看一下结构
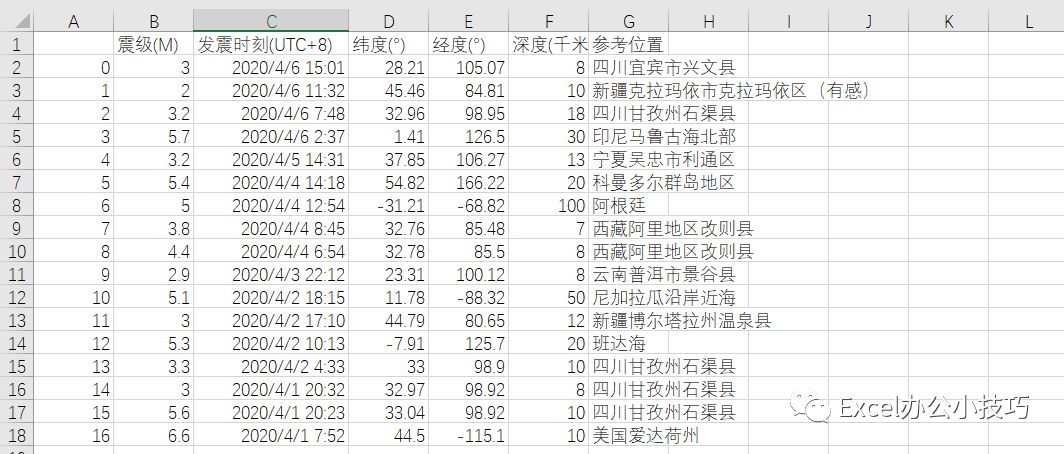
参数先默认,直接使用read_csv函数读取全部数据,如下图(用截图excel文件内容展示):
data=pd.read_csv(r'C:\Users\king\Desktop\示例数据.csv')
print (data)
 看上去还是编码问题~解决它!
看上去还是编码问题~解决它!
UnicodeEncodeError: 'gbk' codec can't encode character '\ufffd' in position 23: illegal multibyte sequence
2.4 使用skipfooter报错解决
我们在读取时encoding='utf-8'再次尝试,没问题,不过出现了警告,根据警告提示,我们读取时限定下engine='python'即可。
ParserWarning: Falling back to the 'python' engine because the 'c' engine does not support skipfooter; you can avoid this warning by specifying engine='python'.
data=pd.read_csv(r'C:\Users\king\Desktop\示例数据.csv',skiprows=6,skipfooter=7,encoding='utf-8',engine='python')
data.to_csv(r'C:\Users\king\Desktop\kingskiprows_2.csv',encoding='gbk')
结果如下:
三 修改表结构
3.1 修改表头名
我们看到,表头还包含括号,不便于后续调用列,所以我们在读取时就处理好。
3.1.1 跳过原有标题行,自定义列名
因为之前输出文件名skiprows_2的文件时,编码是gbk,所以读取skiprows_2文件的时候,encoding=‘gbk'。
data=pd.read_csv(r'C:\Users\king\Desktop\skiprows_2.csv',skiprows=1,encoding='gbk',engine='python',names=['震级','时刻','纬度','经度','深度','位置'])
data.to_csv(r'C:\Users\king\Desktop\skiprows_3.csv',encoding='gbk'
3.2 避免每次读取增加索引列
如上图前两列重复,我们最多需要一列这种索引列,如何去除多余列?
此次读取skiprows_2文件里,设置索引列为空,参数index_col=False即可。
data=pd.read_csv(r'C:\Users\king\Desktop\skiprows_2.csv',skiprows=1,encoding='gbk',engine='python',names=['震级','时刻','纬度','经度','深度','位置'])
data.index_col=False
data.to_csv(r'C:\Users\king\Desktop\skiprows_3.csv',encoding='gbk')
四、数据处理
4.1 空值处理
如果源文件里空值存成了NULL,想显示空即可,参数na_values
data=pd.read_csv(r'C:\Users\king\Desktop\skiprows_3.csv',encoding='gbk',engine='python',na_values='')data.to_csv(r'C:\Users\king\Desktop\skiprows_4.csv',encoding='gbk')

4.2 大文件处理
当数据过大,导致读取过慢,可通过参数chunksize限制数据块大小。
data=pd.read_csv(r'C:\Users\king\Desktop\skiprows_3.csv',chunksize=10000)
作者:TheLittlePython