keras学习率余弦退火CosineAnnealing
当我们使用梯度下降算法来优化目标函数的时候,当越来越接近Loss值的全局最小值时,学习率应该变得更小来使得模型不会超调且尽可能接近这一点,而余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
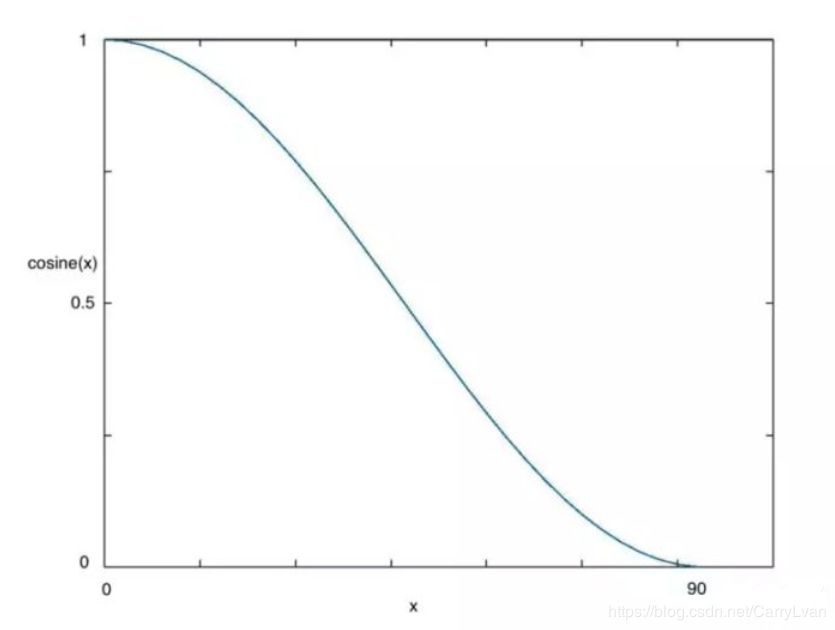
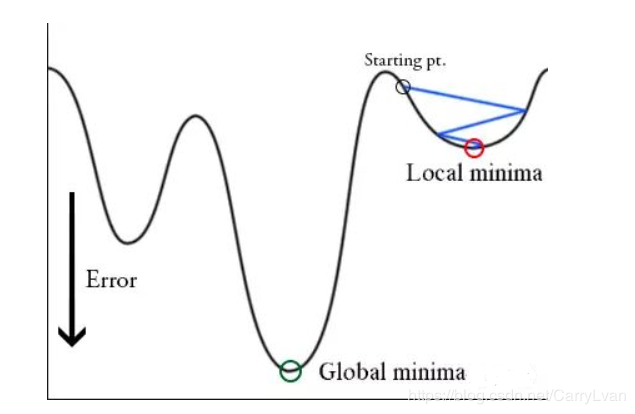
在论文Stochastic Gradient Descent with Warm Restarts中介绍主要介绍了带重启的随机梯度下降算法(SGDR),其中就引入了余弦退火的学习率下降方式,本文主要介绍余弦退火的原理以及实现。并且因为我们的目标优化函数可能是多峰的(如下图所示),除了全局最优解之外还有多个局部最优解,在训练时梯度下降算法可能陷入局部最小值,此时可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。这种方式称为带重启的随机梯度下降方法。
论文介绍最简单的热重启的方法。当执行完TiT_iTi个epoch之后就会开始热重启(warm restart),而下标iii就是指的第几次restart,其中重启并不是重头开始,而是通过增加学习率来模拟,并且重启之后使用旧的xtx_txt作为初始解,这里的xtx_txt就是通过梯度下降求解loss函数的解,也就是神经网络中的权重,因为重启就是为了通过增大学习率来跳过局部最优,所以需要将xtx_txt置为旧值。
本文并不涉及重启部分的内容,所以只考虑在每一次run(包含重启就是restart)中,学习率是如何减小的。余弦退火( cosine annealing )的原理如下:
ηt=ηmini+12(ηmaxi−ηmini)(1+cos(TcurTiπ))\eta_t=\eta_{min}^{i}+\frac{1}{2}(\eta_{max}^{i}-\eta_{min}^{i})(1+cos(\frac{T_{cur}}{T_i}\pi))ηt=ηmini+21(ηmaxi−ηmini)(1+cos(TiTcurπ))
表达式中的字符含义:
为了简单,这里稍微修改一下TcurT_{cur}Tcur和TiT_{i}Ti的定义,原本表示的是epoch的数量,但是因为TcurT_{cur}Tcur是在每个batch之后都会更新,所以将TiT_{i}Ti定义为总的batch需要执行的步数,而TcurT_{cur}Tcur定义为当前对当前已经执行的batch的计数,即每执行一个batch,TcurT_{cur}Tcur就加一。举个例子,样本总数为80,每个batch的大小为16,那么一共有5个batch,再令训练模型总的epoch为30,假设当前执行到第二个epoch的第二个batch结束,那么此时Tcur/Ti=(1∗5+2)/(30∗5)T_{cur}/T_i=(1*5+2)/(30*5)Tcur/Ti=(1∗5+2)/(30∗5),按照之前的定义Tcur/Ti=(1+2/5)/30T_{cur}/T_i=(1+2/5)/30Tcur/Ti=(1+2/5)/30,两者是等价的,但是因为之前的定义存在小数,如果1除以batch的总数除不尽,就会存在精度损失的情况。
这里除了实现余弦退火之外,还加入了warm up预热阶段,在warm up阶段学习率线性增长,当达到我们设置的学习率之后,再通过余弦退火的方式降低学习率。
为什么使用Warmup?
由于刚开始训练时,模型的权重(weights)是随机初始化的,此时若选择一个较大的学习率,可能带来模型的不稳定(振荡),选择Warmup预热学习率的方式,可以使得开始训练的几个epoches或者一些steps内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得更快,模型效果更佳。
keras通过继承Callback实现余弦退火。通过继承Callback,当我们训练的时候传入我们的就函数,就可以在每个batch开始训练前以及结束后回调我们重写的on_batch_end和on_batch_begin函数。
完整代码(源自github):
import numpy as np
from tensorflow import keras
from keras import backend as K
def cosine_decay_with_warmup(global_step,
learning_rate_base,
total_steps,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0):
"""
参数:
global_step: 上面定义的Tcur,记录当前执行的步数。
learning_rate_base:预先设置的学习率,当warm_up阶段学习率增加到learning_rate_base,就开始学习率下降。
total_steps: 是总的训练的步数,等于epoch*sample_count/batch_size,(sample_count是样本总数,epoch是总的循环次数)
warmup_learning_rate: 这是warm up阶段线性增长的初始值
warmup_steps: warm_up总的需要持续的步数
hold_base_rate_steps: 这是可选的参数,即当warm up阶段结束后保持学习率不变,知道hold_base_rate_steps结束后才开始学习率下降
"""
if total_steps 0:
learning_rate = np.where(global_step > warmup_steps + hold_base_rate_steps,
learning_rate, learning_rate_base)
if warmup_steps > 0:
if learning_rate_base < warmup_learning_rate:
raise ValueError('learning_rate_base must be larger or equal to '
'warmup_learning_rate.')
#线性增长的实现
slope = (learning_rate_base - warmup_learning_rate) / warmup_steps
warmup_rate = slope * global_step + warmup_learning_rate
#只有当global_step 仍然处于warm up阶段才会使用线性增长的学习率warmup_rate,否则使用余弦退火的学习率learning_rate
learning_rate = np.where(global_step total_steps, 0.0, learning_rate)
class WarmUpCosineDecayScheduler(keras.callbacks.Callback):
"""
继承Callback,实现对学习率的调度
"""
def __init__(self,
learning_rate_base,
total_steps,
global_step_init=0,
warmup_learning_rate=0.0,
warmup_steps=0,
hold_base_rate_steps=0,
verbose=0):
super(WarmUpCosineDecayScheduler, self).__init__()
self.learning_rate_base = learning_rate_base
self.total_steps = total_steps
self.global_step = global_step_init
self.warmup_learning_rate = warmup_learning_rate
self.warmup_steps = warmup_steps
self.hold_base_rate_steps = hold_base_rate_steps
self.verbose = verbose
#learning_rates用于记录每次更新后的学习率,方便图形化观察
self.learning_rates = []
#更新global_step,并记录当前学习率
def on_batch_end(self, batch, logs=None):
self.global_step = self.global_step + 1
lr = K.get_value(self.model.optimizer.lr)
self.learning_rates.append(lr)
#更新学习率
def on_batch_begin(self, batch, logs=None):
lr = cosine_decay_with_warmup(global_step=self.global_step,
learning_rate_base=self.learning_rate_base,
total_steps=self.total_steps,
warmup_learning_rate=self.warmup_learning_rate,
warmup_steps=self.warmup_steps,
hold_base_rate_steps=self.hold_base_rate_steps)
K.set_value(self.model.optimizer.lr, lr)
if self.verbose > 0:
print('\nBatch %05d: setting learning '
'rate to %s.' % (self.global_step + 1, lr))
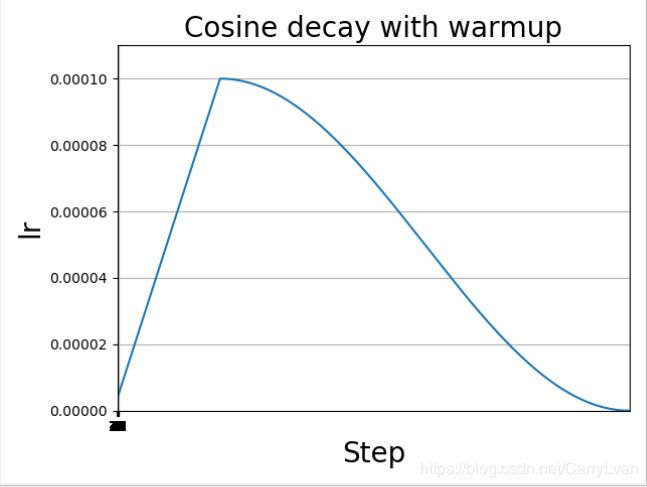
下面的代码构建了一个简单的模型,并使用了warm up和余弦退火的方式来规划学习率。
from keras.models import Sequential
from keras.layers import Dense
# Create a model.
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#样本总数
sample_count = 12608
# Total epochs to train.
epochs = 50
# Number of warmup epochs.
warmup_epoch = 10
# Training batch size, set small value here for demonstration purpose.
batch_size = 16
# Base learning rate after warmup.
learning_rate_base = 0.0001
total_steps = int(epochs * sample_count / batch_size)
# Compute the number of warmup batches.
warmup_steps = int(warmup_epoch * sample_count / batch_size)
# Generate dummy data.
data = np.random.random((sample_count, 100))
labels = np.random.randint(10, size=(sample_count, 1))
# Convert labels to categorical one-hot encoding.
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# Compute the number of warmup batches.
warmup_batches = warmup_epoch * sample_count / batch_size
# Create the Learning rate scheduler.
warm_up_lr = WarmUpCosineDecayScheduler(learning_rate_base=learning_rate_base,
total_steps=total_steps,
warmup_learning_rate=4e-06,
warmup_steps=warmup_steps,
hold_base_rate_steps=5,
)
# Train the model, iterating on the data in batches of 32 samples
model.fit(data, one_hot_labels, epochs=epochs, batch_size=batch_size,
verbose=0, callbacks=[warm_up_lr])
import matplotlib.pyplot as plt
plt.plot(warm_up_lr.learning_rates)
plt.xlabel('Step', fontsize=20)
plt.ylabel('lr', fontsize=20)
plt.axis([0, total_steps, 0, learning_rate_base*1.1])
plt.xticks(np.arange(0, epochs, 1))
plt.grid()
plt.title('Cosine decay with warmup', fontsize=20)
plt.show()
运行结果:
参考博客:
称霸Kaggle的十大深度学习技巧
学习率规划-余弦退火CosineAnnealing和WarmRestart原理及实现
Warmup预热学习率
参考论文:
https://arxiv.org/abs/1608.03983
作者:Donreen