用云存储实现对云计算的监控
引言
大凡集群系统的性能、压力测试,都要通过监控系统进行收集整理。其中ganglia是集群监控常用的工具之一。它与Hadoop生态圈结合的非常好,且性能优良,不会对系统本身性能造成影响。
Ganglia是UC Berkeley发起的一个开源集群监视项目,包含gmond、gmetad两个服务,以及一个web展示前端。本身部署后立即可以对cpu、memory、network、disk等情况进行监控汇总。gmond负责收集系统的这些监控指标数据,一般若干个节点会有一个master,负责从子节点上通过tcp协议抓取这些节点的xml格式的监控数据。若干master再向更上一层的master汇总,直到gmetad这一层会将所有数据保存到rrd数据库中。这样层层抓取进而汇总的模式,保证了节点性能不至于受到gmond监控的影响,且各级master也不会产生过多的网络IO压力。
RRDTool负责保存这些监控数据到RRD(Round RobinDatabase)文件中,RRD数据库顾名思义是一个环装的数据库。越久远的数据在这个数据库中会被不断规整合并,点与点之间的时间差距越来越大,越来越稀疏,当时的细节也跟着逐渐丢失。这样的数据库对于存储大规模集群的监控数据是非常有好处的。它保证了RRD文件的大小可以限制在一定范围内,而且对于集群运维来说,我们往往只关心近期的数据细节,至于过去很久的监控数据看不到细节也没多大妨碍。RRDTool还可以负责绘图,ganglia的web展示上的图正是由此而来。

ganglia和RRD虽然占用系统资源极少,但当集群规模超过5K之后,gmetad对监控数据的收集越来越显得力不从心,而RRD文件即使是高效且压缩的,也同样面临机器IO能力不足的问题。这些都是ganglia这套体系的短板,对于大多数公司团体来说,集群规模远没有达到触发ganglia瓶颈的程度,但是对于云梯来说,这个天花板却是触手可及。
同时RRD数据库的远期数据细节丢失问题,对于集群运维来说毫无影响,但是对于测试人员来说却是一个灾难。因为细节的丢失将导致刚做的性能测试无法与一个月前甚至一年前的同样的测试用例得到的结果进行对比。如果不解决这个问题,那么集群的性能监控对于测试人员的帮助将非常有限。
破解难题
上面提到的问题,在云梯这种大规模集群的测试中都遇到了。早期云梯测试人员试图将监控数据从RRD数据库中提取出来保存到mysql中,这样方便查询、对比、展示。但是对于上百个节点的测试集群来说,mysql数据库往往只需一周时间会被撑爆。一个简单的指标数据的查询往往要等上半个多小时才能从mysql中提取出来。而监控数据保存到RRD文件,再使用RRDTool导出监控数据到mysql中,整个过程也是及其低效的。在我接手云梯1项目的集成测试之后,深深的被这个问题所困扰,整理测试数据让每一次的集成测试结果汇总都苦不堪言。
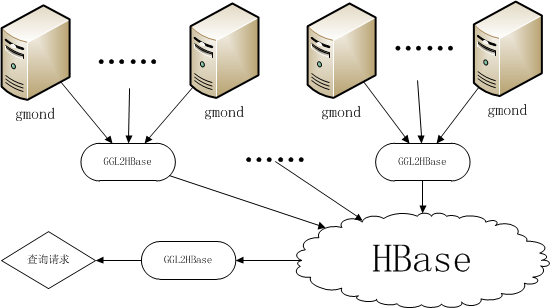
2012年上半年,测试这边开始主导设计DST(分布式测试工具)测试框架,随着云梯项目的进行,DST也在不断迭代中向前发展。其中集群监控数据的收集整理展示被我标记为首要必须完成的功能。经过深思熟虑,终采用了“替代gmetad,并直接存储监控数据至HBase”这个解决方案,设计的工具被我命名为“GGL2HBase”。
这个方案是做成一个与gmetad类似的服务,直接去所有节点的gmond master上抓取监控数据,从网络拿到后,直接从内存中存储到一个HBase集群中。利用HBase的高效解决了查询慢的问题,同时RRD文件远期数据细节丢失的问题也迎刃而解。
设计细节
HBase是一个典型的key/value结构的nosql数据库,利用其RowKey自动排序的功能,我按机器编号(4字节int型)、指标编号(4字节int型)、时间戳(8字节long型)这样的顺序组合成了RowKey,Value中保存的则是这台机器这个指标当前时间戳的监控数据(16个字节的double型数值)。这样在查询的时候,我可以根据机器名+指标名,快速的scan出一段时间内的监控数据。而存储的时候,我在创建该表时,主动根据开始字节做了split,切分成1024个region(原本设想会有不到1000台机器的监控数据导入HBase,后来随着DST的推广发展,导入的机器数量并发高峰期达到了3000多台的规模,历史上共有6000多台机器正在或曾经导入过监控数据),这样保证了写入的监控数据不会集中分布在某台regionserver上,提高了写入性能。
GGL2HBase工具被我部署在多台机器上,通过并发方式提高抓取监控数据的性能,同时每个工具还启动了一个web服务,查询操作被我封装成了RESTful方式提供给web端实时展示。加入监控的gmond master列表则做成了动态监测,这样保证在增加新机器的监控数据时,导入服务也不会停止,防止了丢数据的可能性。整个过程经过整合优化后,原先需要半个小时以上的简单查询,被我压缩到了毫秒级别。而即使是复杂的运算查询,也控制在了半秒之内(这在初那个模式中,由于多次查询耗时太长,根本不可能去做)。这个系统持续不断的已经运行超过一年,而我们即使是刚做的测试也可以与一年前的数据进行对比,方便历次多条基线的参照,以及快速出测试报告。这套系统完成后,加上DST的自动化功能,促使之前需要至少耗时一个多月的集成测试周期被压缩到了一周之内。
如下图所示,展现十多个指标的数据图(只是作为一个例子),这些数据从10多TB的数据中捞出来只需要不到半秒的时间。
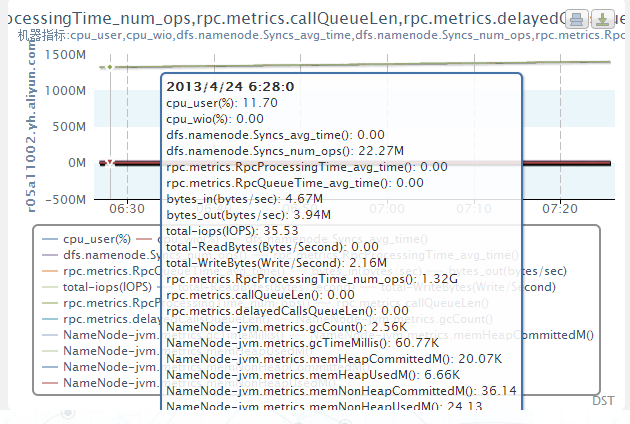
该工具除了速度快之外,还充分利用了gmond汇报数据的特点,完整记录了所有指标的单位、分组、描述等信息,以及所有机器的机器名、IP地址、包含的指标等信息,与前端mysql数据库搭配后,完成了DST对集群信息的整体掌控。
此外,由于是收集了所有被监控节点的所有监控指标数据,因此当我们想查看以前被忽略的某个指标的历史数据时,也完全不用担心找不到这些数据。HBase的海量存储能力保证了再多的数据也能放得下,当前20台规模的HBase集群已经存储了10多个TB的监控数据,而对于整个HBase系统来说,即使存放10年的数据量也是绰绰有余的。
发展计划
当前GGL2HBase的发展方向是有能力兼容接入更多种类的监控数据,完成监控体系的一体化。同时,配合DST前端,更好的展示这些监控数据。并利用HBase集群的能力,将更多的计算过程放到后端集群中去做,减少前端的计算压力。这些都是任重而道远的工作,但是做这些事情本身也是对个人技术能力的考验和提升,而解决问题的过程,更是难得的乐趣。