使用facebook的fbprophet模型预测湖北新冠肺炎确诊人数(包含源码和具体分析过程)
就在最近,一次偶然的机会学习了以下fbprophet时序预测模型,就决定使用这个框架来进行未来20天人数的预测。但是传染病模型通常比较复杂,此次使用此模型来预测,仅仅是用来练习,结果仅供参考。
fbprophet模型简介 这个模型(算法)是由facebook公司在2017年正式开源的,主要用于对时间序列进行预测。 这个模型上手非常容易,即便是很一般的数据分析师也能够做一个比较精准的预测。 该模型只需要设置基本配置,并传入指定格式的数据,就可以完成数据的预测。 整体框架分为Modeling、Forecast Evaluation、Surface Problems以及Visually Inspect Forecasts这四个部分。 模型有三部分组成,增长趋势,季节趋势,节假日影响。更多关于这个模型的介绍,腾讯技术写过一篇我见过最详细的介绍,我就不做重复工作了,大家自行查看把
腾讯技术工程 | 基于Prophet的时间序列预测
首先强调一下安装fbprophet我遇到的坑:
需要首先安装pystan,这个包使用pip安装很难成功,建议使用anaconda安装。 成功安装pystan后,使用pip安装fbprophet。怪吧,因为我使用anaconda安装不上fbprophet。 二、使用的数据我所使用的数据是湖北省从2019年12月1日到2020年2月29日的确诊人数数据【数据下载】(提取码:vmnv):
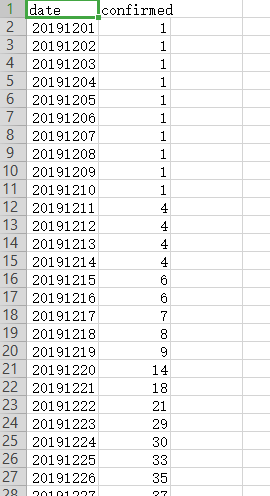
根据官网的描述,只要用 csv 文件存储两列即可,第一列的名字是 ‘ds’, 第二列的名称是 ‘y’。第一列表示时间序列的时间戳,第二列表示时间序列的取值。所以这里我们可以手动在文件中更改列名,也可以在程序中改。这里我们使用后者方法。
import pandas as pd
import pystan
from fbprophet import Prophet
import matplotlib.pyplot as plt
pdata = pd.read_csv("data/20200301-nCoV-hb.csv")
pdata.rename(columns={'date':'ds','confirmed':'y'},inplace=True)
pdata['ds'] = pd.to_datetime(pdata['ds'],format='%Y%m%d')
首先我们将列名修改成了官方要求的’ds’和’y’,其次我们将’ds‘的格式修改成了datatime时间格式。
四、初步预测 #创建一个模型
m = Prophet()
# pdata['cap']=69000
m.fit(pdata)#传入模型需要预测的数据
#创建一个包含预测时间的dataframe,这里period时预测时,单位默认是天
future = m.make_future_dataframe(periods=20)
# future['cap']=69000
#进行预测,返回预测值及其其他相关值,格式是dataframe。
forecast = m.predict(future)
#绘画出图形
m.plot(forecast)
plt.show()#显示图片
test = forecast[['ds','yhat']].tail(20)#输出预测的20天的值
print(forecast[-20:])
结果图:
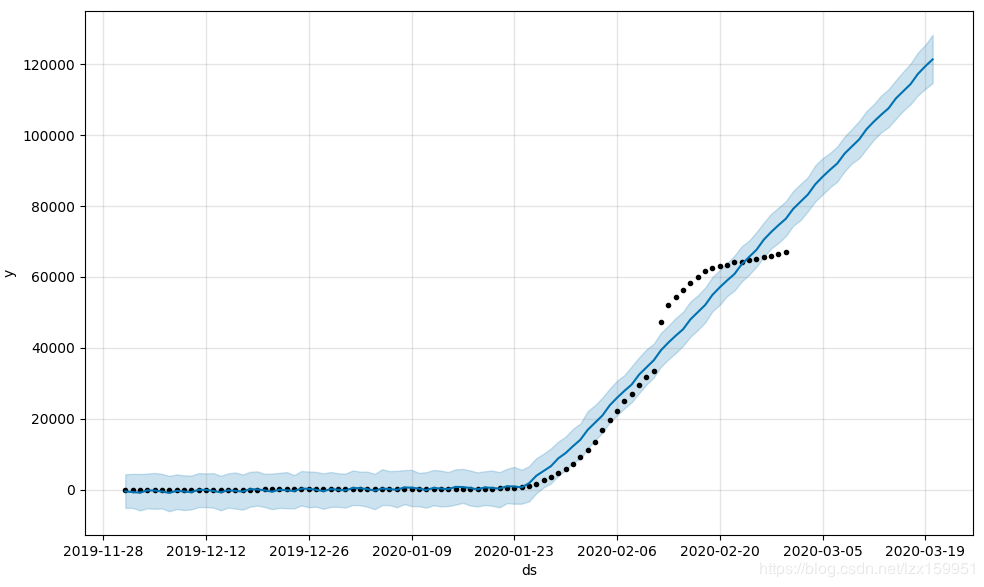
图中,黑色的点是我们文件中的数据,也就是确诊人数,中间深蓝色的线就是我们预测的曲线,曲线轮廓的上下边界有浅蓝色区域,它表示模型预测值的上、下边界。
这个结果肯定不能让我们满意,好了,我们来调整一下模型。
五、调整模型模型可以调整的参数(prophet()中的参数):
prophet()有两种模式,第一种是线性’linear‘,第二种是逻辑回归(非线性)‘logistic’。默认是线性的。注意 若使用后者,需要添加cap 进行容量值设置。 changepoints( prophet()模型中的):改变点。使用者可以自主填写已知时刻的标示着增长率发生改变的”改变点。默认是0.05 changepoint_prior_scale( prophet()模型中的):增长趋势模型的灵活度。值越大,曲线拟合就越灵活,过大也会出现过拟合的情况 holidays 节假日定义,holidays_prior_scale节假日对模型的影响,值越大,影响程度越大,默认值是10。holidays格式第一个参数是节假日名字,这个一般都自己写; 第二个是你指定哪些日子为假期;第三个lower_window 是前面你设定的节假期前几天;第四个upper_window是节假日后几天。下图中我设置的是2月20日为一个节日,这个节日时长为之后的14天。 seasonality_prior_scale 调节季节的影响程度默认值是10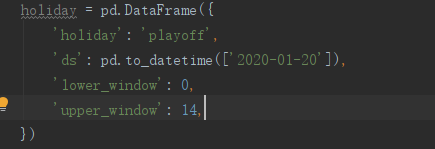
好了,我们首先将模式改为逻辑回归(非线性),注意容量值的设置。
m = Prophet(growth='logistic')
pdata['cap']=69000#容量值设置
m.fit(pdata)
#创建一个包含预测时间的dataframe
future = m.make_future_dataframe(periods=20)
future['cap']=69000#容量值设置
看一下这次的结果吧
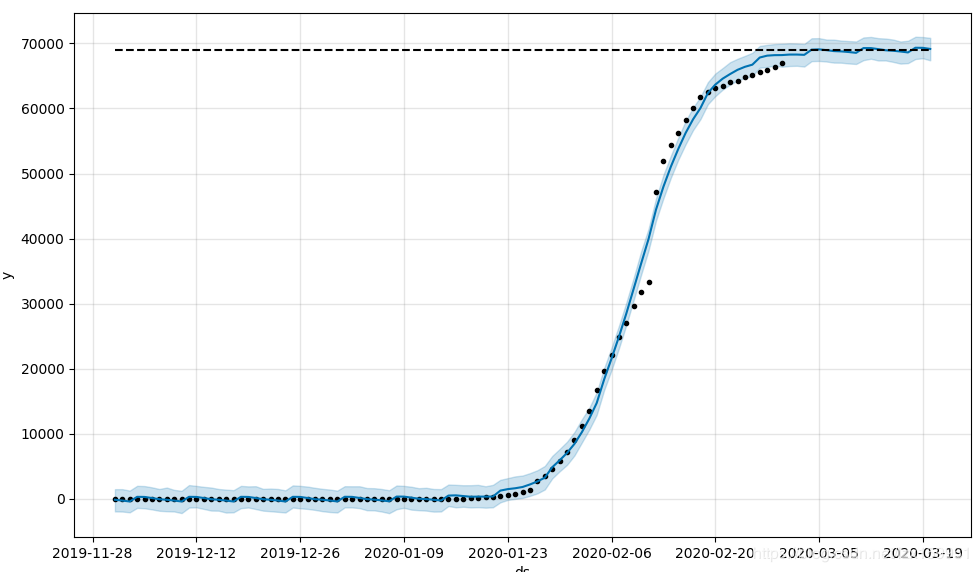
这次比上次好了很多,已经非常拟合了,接下来咱们再修改一下增长趋势拟合度,这个值默认是0.05,咱们修改为2
m = Prophet(growth='logistic',changepoint_prior_scale=2)
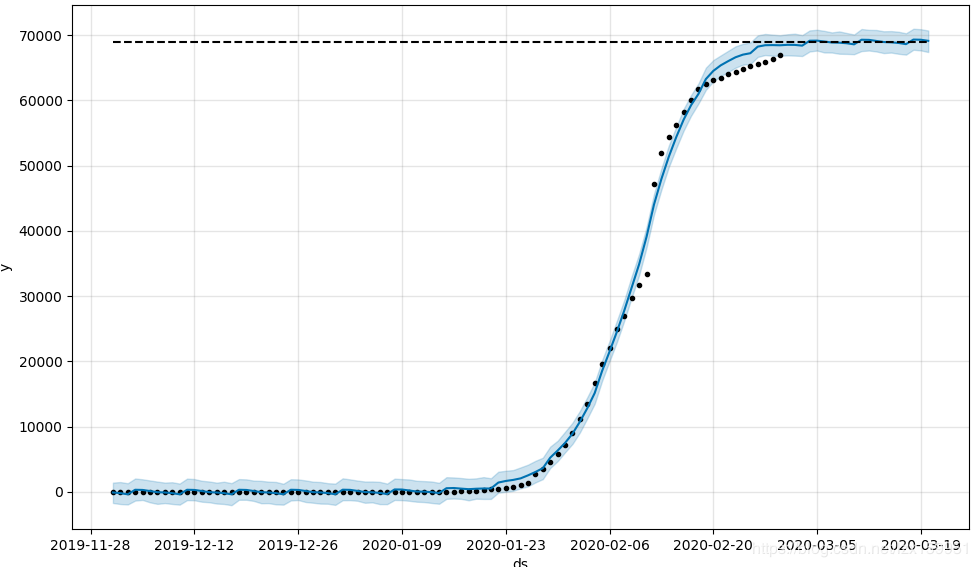
对比起来没有什么变化,我们得去找找问题。
看上面咱们说得调整模型参数,changepoints,会不会是因为我们没有设置固定得改变点,使得图片拟合没有发生什么变化,试一试。
m = Prophet(growth='logistic',changepoint_prior_scale=2,changepoints=['2020-01-24','2020-02-14','2020-02-20'])
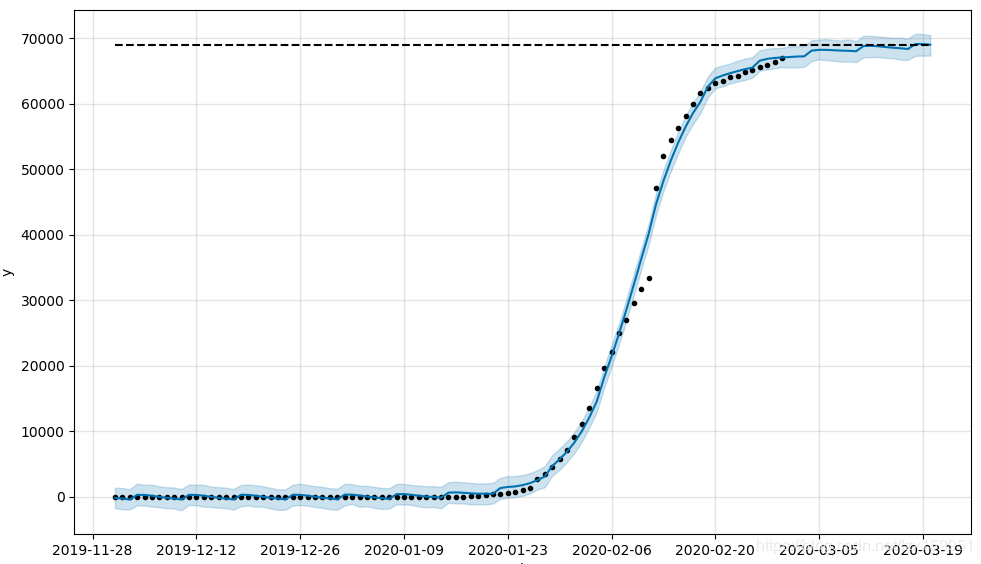
好了,这个模型趋势看起来已经相当拟合,但是这里需要注意,changepoint_prior_scale值过大会出现过拟合的情况,所以需要你多去尝试,寻找合适的值。
咱们把最终调整完模型预测的值写一下,看看未来几天跟我们的预测有多大差距,想想还是很激动的:
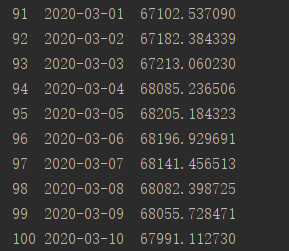
源码:
import numpy as np
import pandas as pd
import pystan
from fbprophet import Prophet
import matplotlib.pyplot as plt
pdata = pd.read_csv("data/20200301-nCoV-hb.csv")
pdata.rename(columns={'date':'ds','confirmed':'y'},inplace=True)
pdata['ds'] = pd.to_datetime(pdata['ds'],format='%Y%m%d')
m = Prophet(growth='logistic',changepoint_prior_scale=2,changepoints=['2020-01-24','2020-02-14','2020-02-20'])
pdata['cap']=69000
m.fit(pdata)
#创建一个包含预测时间的dataframe
future = m.make_future_dataframe(periods=20)
future['cap']=69000
forecast = m.predict(future)
m.plot(forecast)
plt.show()
test = forecast[['ds','yhat']].tail(20)
print(test[-20:])
不足与思考:
新型冠状病毒传染模型比较复杂,涉及到多种模型,这里只是使用这个模型做一下简单的预测。目的是学习此模型。
上文我只是添加了几个改变点,大家在地下尝试的时候可以添加假期和假期影响程度。
这里我只是输出了forecast[[‘ds’,‘yhat’]] 一个是时间信息,一个是与测试,forecast还包含yhat_lower,yhat_upper。分别是预测值的下限,预测值的上限。
以后有机会学习到传染病传播相关模型,会于此模型进行结合。
参考文章:
Facebook 时间序列预测算法 Prophet的研究 腾讯技术工程 | 基于Prophet的时间序列预测 fbprophet-github作者:梁先森-python数据分析师进阶之路