游戏个性化数值因果推断的应用实践
一、背景
二、常见模型介绍
2.1 Meta-learner
2.2 Double machine learning
2.3 Generalized Random Forests
三、评估方式
3.1 Uplift bins
3.2 Qini curve
四、业务应用
4.1 样本准备
4.2 样本构造
4.3 模型训练
4.4 人群分配
4.5 实验效果
五、总结及后续展望
一、背景在游戏场景内,通常有着各种各样的玩法数值设计。由于不同用户在偏好、游戏经验等方面存在差异,因此同一数值并不适用于所有用户。例如一个闯关游戏,对于新手来说,设置关卡的难度系数可以比有丰富经验的老玩家低一些。为了让用户能够有更好的游戏体验,我们可以基于算法对用户进行个性化的数值调控,从而提升用户在游戏内的时长、留存等。
传统的监督学习方式聚焦于响应结果 Y 的预估,而我们场景更关注于变量的变化对于结果 Y 的影响。在业界,这类问题通常会放在因果推断(Causal Inference)的框架下进行讨论,我们通常将变量称为 T(treatment),变量变化带来结果 Y 的变化称为 TE(treatment effect),用来预估 TE 的模型称为因果模型(Uplift Model)。
目前业界中比较常用的因果模型有 meta-learner、dml、因果森林等,但是不同因果模型的优劣势及实际表现还没有做过很全面的对比。因此在我们场景中,我们对上述这些问题进行了详细的探索。
本文将从理论及实践两方面,对比及分析不同因果模型的优缺点及适用场景,希望能够为大家在后续处理相似问题时,提供启发及帮助。
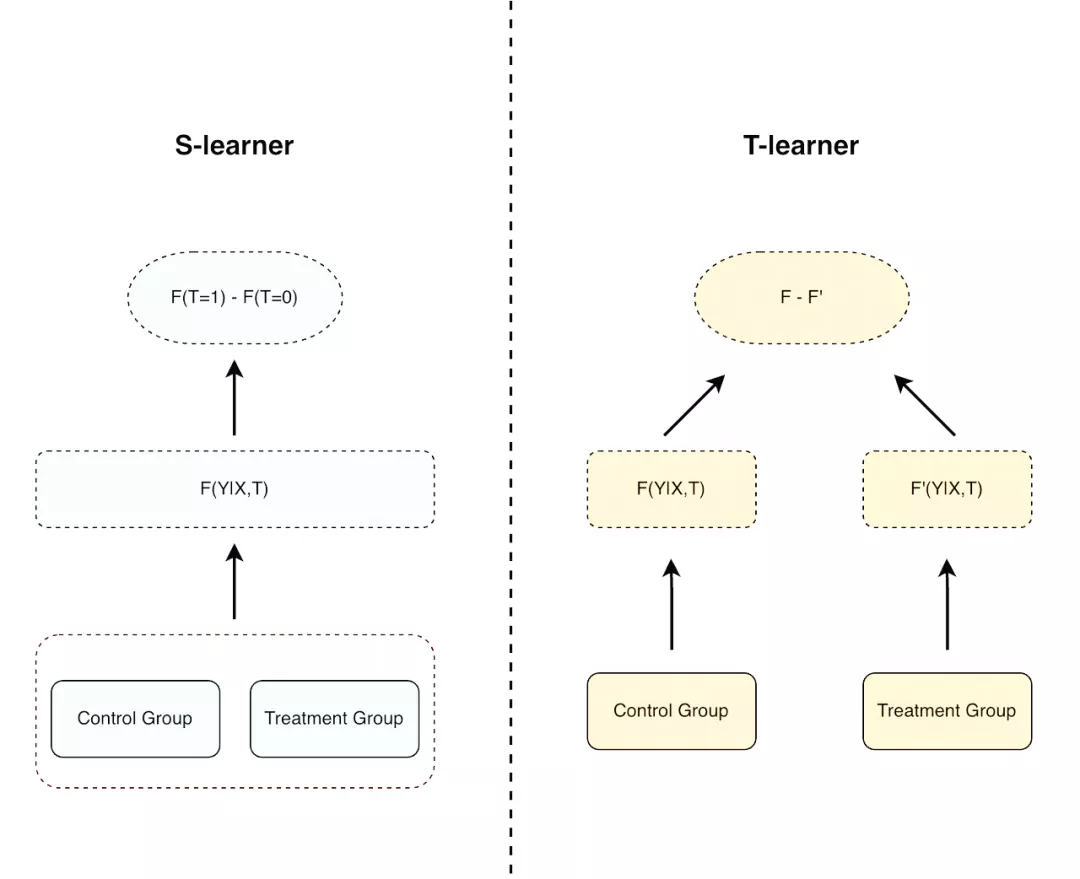
二、常见模型介绍 2.1 Meta-learnermeta-learner 是目前主流的因果建模方式之一,其做法是使用基础的机器学习模型去预估不同 treatment 的 conditional average treatment effect(CATE),
常见的方法有:s-learner、t-learner。
meta-learner 的思路比较简单,本质上都是使用 base-learner 去学习用户在不同 treatment 组中的 Y,再相减得到 te。区别在于在 s-learner 中,所有 treatment 的数据都是在一个模型中训练,treatment 通常会作为模型的一个输入特征。
而 t-learner 会针对每个 treatment 组都训练一个模型。
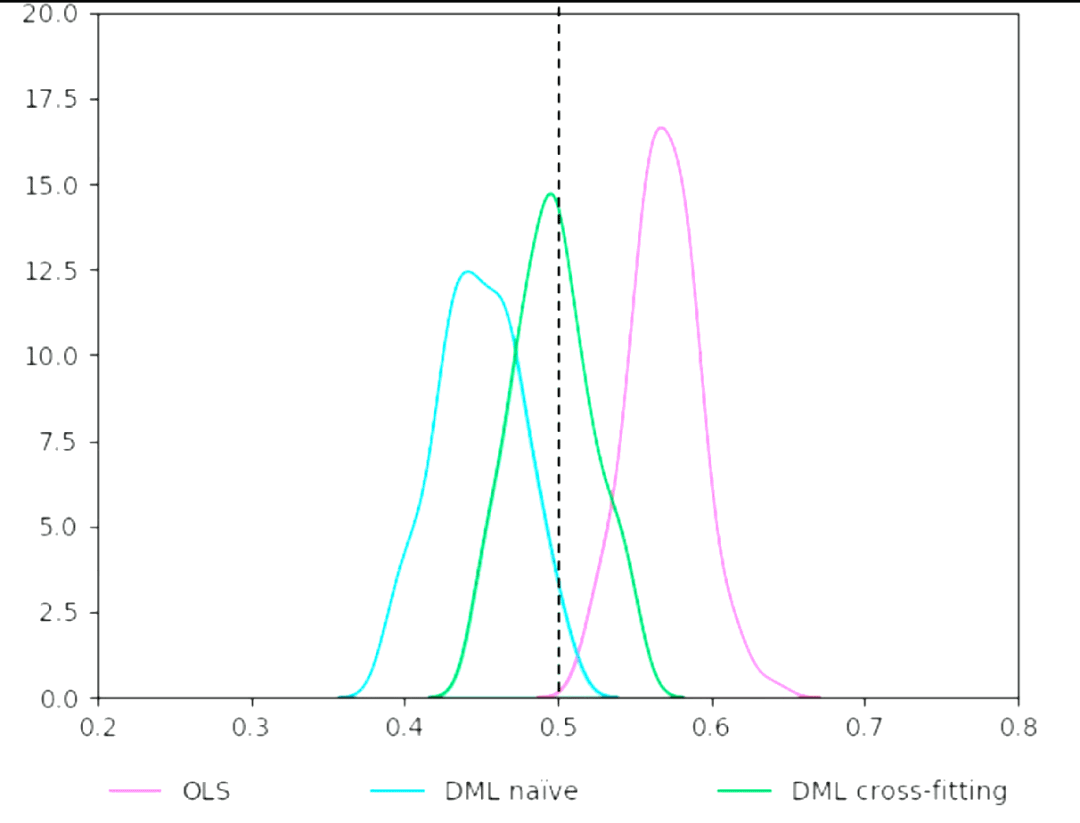
在 meta-learner 中,中间变量的预测误差导致我们在进行 uplift 预估时天生存在 bias。为了解决该问题,DML 引入了残差拟合、cross fitting 等方式进行消偏处理,最终得到了无偏估计。

DML 的核心思想就是通过拟合残差,来消除中间变量的 bias 的影响。论文中证实了误差的收敛速度快于 n^(-1/4),确保了最终预估结果的收敛性。
下图展示了论文中不使用 DML、使用 DML 但不使用 cross fitting、使用 DML-cross fitting 的效果对比:
GRF 是一种广义的随机森林算法,和传统的随机森林算法的不同点在于,传统的随机森林算法在做 split 时,是找 loss 下降最大的方向进行划分,而 GRF 的思想是找到一种划分方式,能够最大化两个子节点对于干预效果之间的差异。和随机森林相同,GRF 也需要构建多棵树。在每次建树时,也需要随机无放回的进行抽样,抽取出来的样本一半用来建树、一半用来评估。
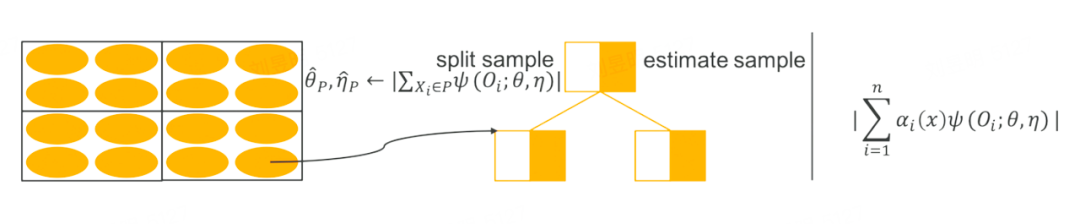
GRF 算法延续了 DML 的思想,在第一阶段时,使用任意的机器模型去拟合残差。第二阶段时,GRF 算法引入了得分函数 Ψ(Oi)、目标函数 θ(x)和辅助函数 v(x),其中得分函数的计算公式为:
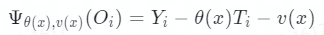
很容易看出,得分函数 Ψ(Oi)其实就是残差,由公式 Y = θ(x)T + v(x)得到的。算法寻求满足局部估计等式的 θ(x):对于所有 x,满足:
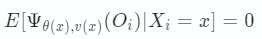
其实本质上也是学习 θ(x),使得实验组和对照组数据的预估结果与真实值之差最小。
三、评估方式目前因果模型常见的评估方式有两种:uplift bins 及 uplift curve
3.1 Uplift bins将训练好的模型分别预测实验组和对照组的测试集数据,可以分别得到两组人群的 uplift score。按照 uplift score 的降序进行排列,分别截取 top10%、top20% .... top100%的用户,计算每一分位下两组人群分值的差异,这个差异可以近似认为是该分位下对应人群的真实 uplift 值。uplift bins 的缺陷在于,只能做一个定性的分析,无法比较不同模型效果好坏。
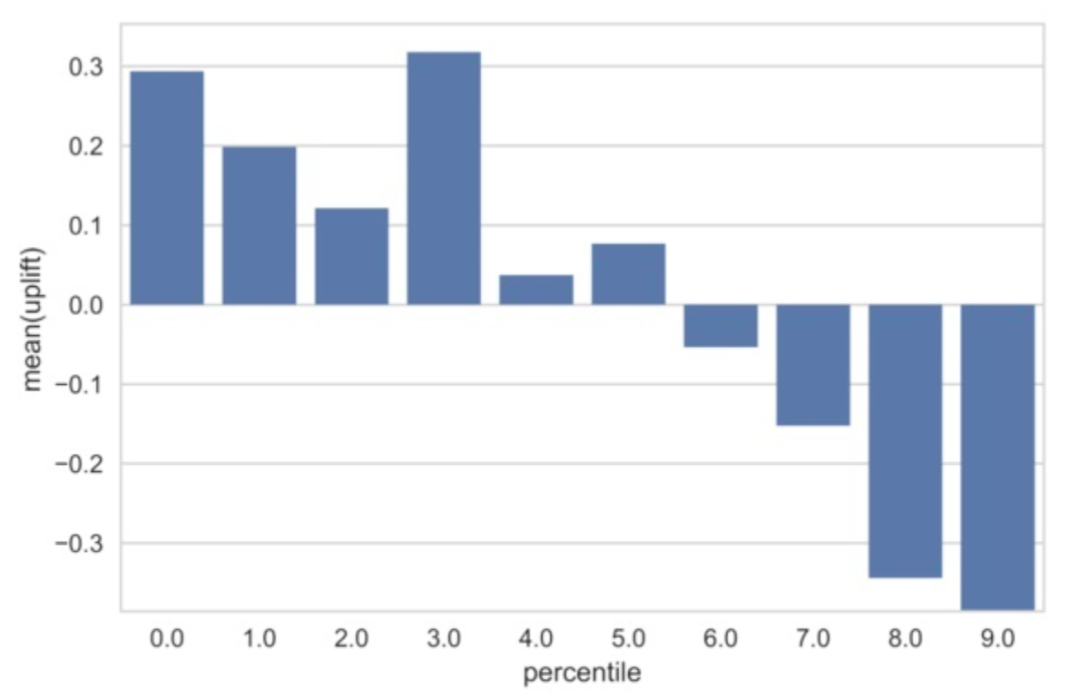
在 uplift bins 的基础上,我们可以绘制一条曲线,用类似于 AUC 的方式来评价模型的表现,这条曲线称为 uplift curve;我们将数据组的数据不断细分,精确到样本维度时,每次计算截止前 t 个样本的增量时,得到对应的 uplift curve。
计算公式为:
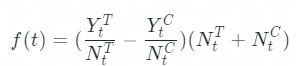
其中 Y_t^T 代表前 t 个样本增量时,实验组样本转化量,N_t^T 代表实验组的累计到 t 时,实验组样本总量,对照组同理。
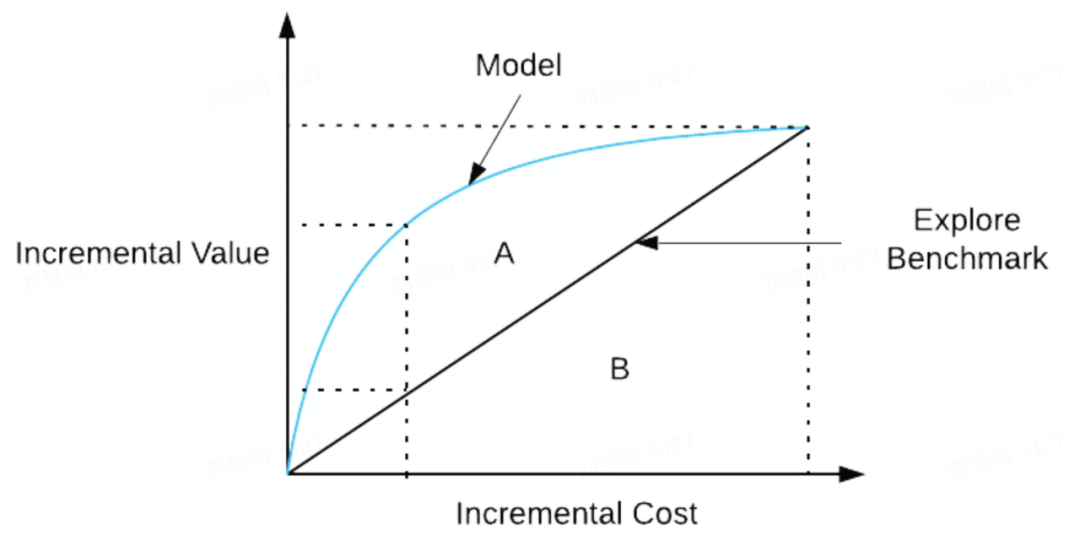
如上图,蓝线代表的 uplift curve,实黑线代表 random 的效果,两者之间的面积作为模型的评价指标,其面积越大越好,表示模型的效果比随机选择的结果好的更多。与 AUC 类似,这个指标我们称为 AUUC(Area Under Uplift Curve)。
四、业务应用 4.1 样本准备因果建模对于样本的要求比较高,需要样本服从 CIA(conditional independence assumption)条件独立假设,即样本特征 X 与 T 相互独立。因此在进行因果建模前,需要进行随机实验进行样本收集,通常是通过 A/B 的方式将用户随机的分配至不同的 treatment 中,观测用户在不同 treatment 下的表现。
4.2 样本构造样本构造与常规机器学习的样本构造步骤基本一致,但是需要特别关注以下方面:
特征关联:用户特征 X 必须严格使用进入随机实验组前的特征,例如:用户 T 日进入实验组,那么用户的特征必须使用 T-1 日及以前的特征。这样做的原因是用户进入 treatment 后,部分特征可能已经受到 treatment 的影响发生了改变,使用受影响后的特征进行模型训练有几率造成信息泄露,对模型的效果造成比较大的影响甚至起反向的作用。
目标选择:在某些场景中,treatment 的影响需要一段时间才能够产生作用,例如道具数量的调整对用户留存的影响可能需要过一段时间才能体现。因此在选择目标时,可以选择更长周期的目标,例如相比于次日留存,选择 7 日留存或 14 日留存会更优。不过也不是越长周期越好,因为越长周期的目标有可能导致模型的学习成本增加从而效果下降,这种情形在小样本的场景更为突出。选择一个合适的目标能够很大程度上提升模型的线上表现。
4.3 模型训练在我们的场景中,用户每次完成任务发放的道具数量为 treatment,用户留存以及用户活跃时长变化为我们关注的 uplift。实验过程中,我们先后对比了 s-learner、t-learner 以及 dml 的效果,三种模型选择的 base-learner 都为 lightgbm。
在实验的过程中,我们发现,当使用 s-learner 对活跃时长进行建模时,无论如何调试模型,得到的 treatment effect 都为 0,即用户在不同 treatment 下的活跃时长预测结果相同。但是当我们将模型换成 t-learner 或 dml 时,treatment effect 数据恢复正常。输出 s-learner 的特征重要度,我们发现 treatment 特征的重要度为 0。我们对用户在不同 treatment 下活跃数据进行分析,发现不同组的活跃数据弹性很小,即用户在不同 treatment 下的活跃改变很小。

而 s-learner 对于这种微弱的改动敏感度很低,因此效果不佳。而 t-learner 在进行训练时,会针对每个 treatment 都训练一个模型,相当于显性的将 treatment 的特征重要度加大,而 dml 在训练过程中主要关注训练的残差,因此这两类模型的效果都要好于 s-learner。这也反映了 s-learner 在数据弹性不足时的效果缺陷,因此在后续的训练中,我们放弃了 s-learner,主要关注在 t-learner 以及 dml 上。
后续在不同指标的离线评估上,dml 模型的效果都要显著优于 t-learner。这也与理论相互印证:t-learner 由于引入中间变量,中间变量的误差使得对于最终 uplift 的预估有偏,而 dml 通过拟合残差,最终实现了无偏估计。
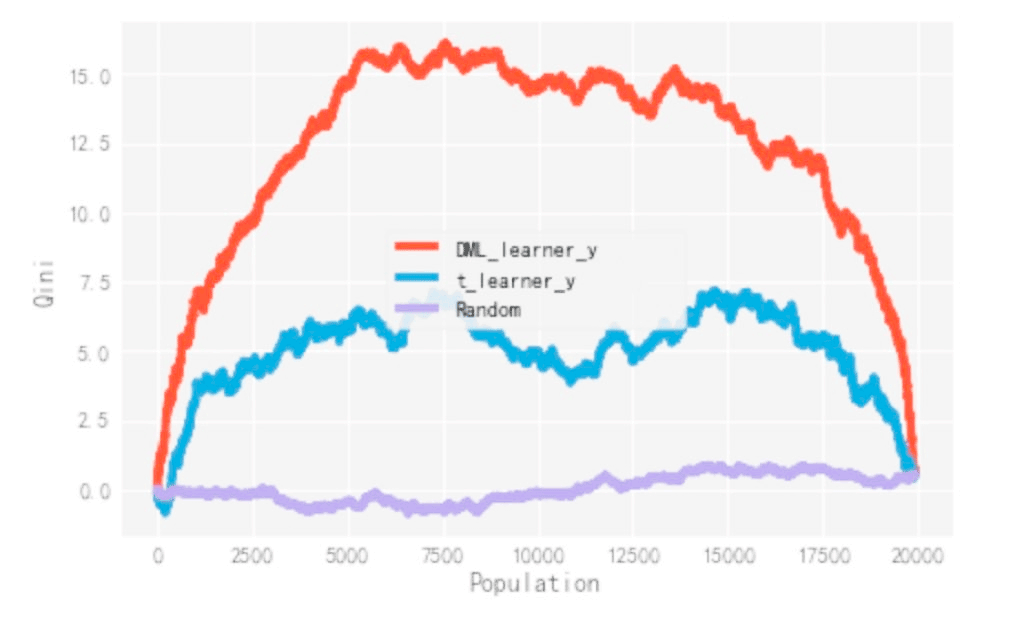
根据训练效果,我们选择 dml 作为最终的预估模型,并得到了用户在不同 treatment 下的 uplift 值。我们会根据用户在不同 treatment 下的 uplift 值,对用户做人群分配。分配方案基于实际情况主要分为两种:有无约束条件下的人群分配及有约束条件下的人群分配。
无约束条件下的人群分配:只关心优化指标,不关心其他指标的变化。那么我们可以基于贪心的思想,选择每个用户 uplift 值最高的策略进行人群分配。
有约束条件下的人群分配:关注优化指标的同时,对于其他指标的变化也有一定的约束。我们可以通过约束求解的方式对该类问题进行求解。
在我们的业务场景下,我们同时对用户留存、活跃时长、流水等目标都有限制,因此进行了有约束条件下的人群分配方案。
4.5 实验效果基于训练好的 dml 模型及约束分配后的结果,我们开启了线上 A/B 实验。在经过多周的测试后,相较于基准策略,我们的策略在流水、活跃等指标不降的情况,取得了置信的 10%+留存收益。目前我们基于因果模型的策略已经全量上线。
五、总结及后续展望因果模型目前在互联网各大场景都得到了实践及应用,并取得了不错的收益。随着营销活动越来越多,营销手段越来越复杂,treatment 的维度也由常见的多 treatment 逐渐变为连续 treatment,这对于样本、模型学习能力等方面的要求也越来越严格。在后续工作开展,可以考虑从多目标建模、场景联动、无偏估计、强化学习等方面继续进行优化,为各个业务场景产生更大价值。
以上就是游戏个性化数值因果推断的应用实践的详细内容,更多关于游戏个性化数值因果推断的资料请关注软件开发网其它相关文章!