【TensorRT】TensorRT的INT8校准原理
INT8校准就是原来用32bit(float32)表示的tensor现在用8bit来表示,并且要求精度不能下降太多。
将FP32转换为 INT8的操作需要针对每一层的输入tensor和网络学习到的参数进行。
但是不同网络结构的不同layer的激活值分布很不一样,因此合理的量化方式。应该适用于不同的激活值分布,并且减小信息损失。
使用相对熵(也叫KL散度)来衡量不同的INT8分布与原来的FP3F2分布之间的差异程度。
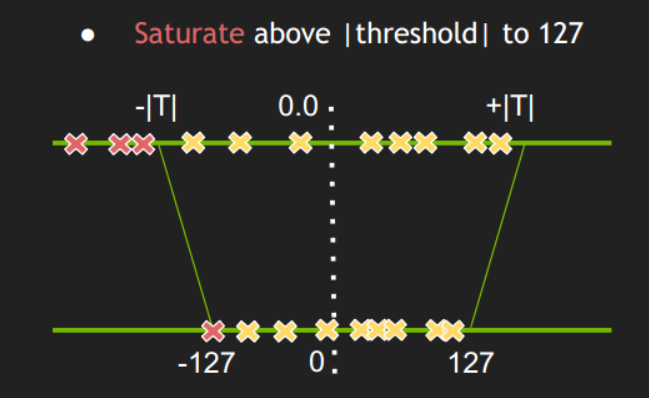
确定每一层的|T|值的过程称为校准。方法是从验证集选取一个子集作为校准集,校准集应该具有代表性,多样性,最好是验证集的一个子集,不应该只是分类类别的一小部分。激活值分布就是从校准集中得到的。比如NVIDIA官方介绍ImageNet数据集,校准集有500张图片就够了。
有了校准集之后:
1. 在校准集上进行FP32推理;
2. 遍历网络的每一层:
2.1 收集该层的激活值,做直方图,并分成若干bins(官方介绍使用2048个bins);
2.2 |T|的值肯定在第128-2047 bins之间,遍历不同的|T|值,这里可以取每个bin的中值,最后选取使得KL散度最小时的|T|值。
3. 最后每一层都得到一个|T|值,据此创建CalibrationTable。
官方伪代码:
Input: FP32 histogram H with 2048 bins: bin[ 0 ], …, bin[ 2047 ]
For i in range( 128 , 2048 ):
reference_distribution_P = [ bin[ 0 ] , ..., bin[ i-1 ] ]
outliers_count = sum( bin[ i ] , bin[ i+1 ] , … , bin[ 2047 ] )
reference_distribution_P[ i-1 ] += outliers_count
P /= sum(P) // 归一化
candidate_distribution_Q = quantize [ bin[ 0 ], …, bin[ i-1 ] ] into 128 levels
expand candidate_distribution_Q to ‘ i ’ bins
Q /= sum(Q)
divergence[ i ] = KL_divergence( reference_distribution_P, candidate_distribution_Q)
End For
Find index ‘m’ for which divergence[ m ] is minimal
threshold = ( m + 0.5 ) * ( width of a bin )
下面是我使用TensorRT生成CalibrationTable输出的一些log。

作者:heiheiya