初步调查——视频实例分割(VIS)
这个任务的目标就是,把视频帧的每一个实例分割出来。融合了检测、分割、跟踪这些最常见的计算机视觉任务。
可以结合2019年ICCV的文章《Video instance segmentation》中的定义:
“Different from image instance segmentation,the new problem aims at simultaneous detection, segmentation and tracking of object instances in videos.”
VIS:Video instance segmentation
VOS :Video object segmentation
VOD :Video object detection
MOTS :Multi - object tracking and segmentation
| 是否分割 | 是否检测 | |
|---|---|---|
| VIS | Y | Y |
| VOS | Y | N |
| VOD | N | Y |
| MOTS | Y | Y |
以目前的研究现状,VIS[2]与MOTS[3]十分相近,目前可以直观的总结如下区别:MOTS的目标类别较少,跟踪时间短;VIS目标类别多,跟踪时间长。
现有的VIS算法现有的方法主要以Mask R-CNN+Track为主,主要思想就是以Mask R-CNN为基本框架,加入跟踪模块,完成VIS。我们可以分析几篇经典文章,寻找一般性结论。
《Video instance segmentation》
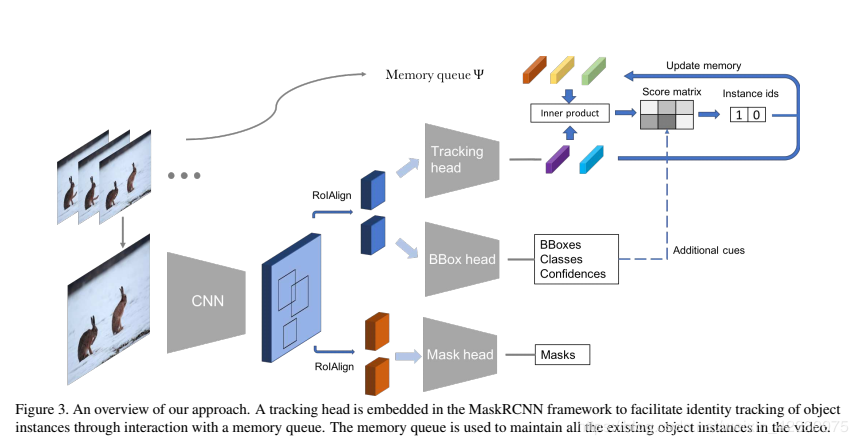
该文章以Mask R-CNN为基础,在原有网络的三个功能(定位,识别,分割)的基础上增加一个跟踪(Track)模块,完成VIS任务。具体的内容这里不做详谈,可以参照Rlin_by这位博主的论文讲解。这里主要说一点,就是跟踪模块,是由两个全连接层组成的。
《MOTS: Multi-Object Tracking and Segmentation》
该文章应该早于上一篇文章,文章扩展了多目标跟踪的任务,变成了多目标跟踪与分割(MOTS),该任务在上文中进行了简单的对比,但本质上属于同一task。该文章中也是采用了Mask R-CNN与关联模块的结合。具体算法流程如下:
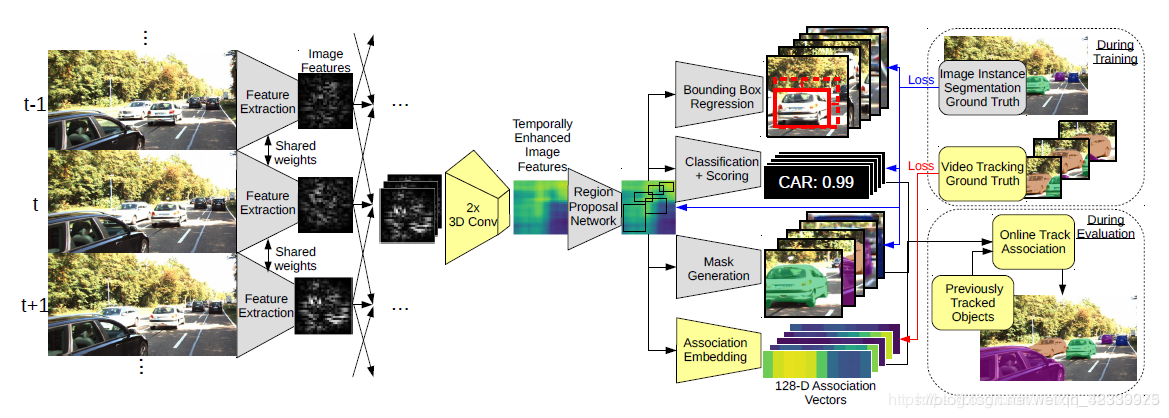
看图说话,这里的黄色部分是作者的创新点,一个是3D卷积,为了利用输入的连续帧的时间维度的信息,另一个就是“关联嵌入”,即我们的跟踪模块,这里的功能是将每个region proposal转换为特征列向量,每个向量为128维。很巧,该模块也是全连接层。追究根本,就是将每个proposal的深度图像特征转换为特征向量,然后进行相似度计算,无论你是向量内积也好,还是计算向量差的二范数,还是有更花哨的计算distance的方法,都是为了比较两个目标的相似度,进而完成数据关联,得到online的跟踪结果。
《Unovost: Unsupervised offline video object segmentation and tracking for the 2019 unsupervised davis challenge》[4]
这篇文章是来自2019年Davis挑战赛的一个比赛论文,无监督offline的VOS领域,只关注online算法的朋友可以绕行。该文章用Mask R-CNN生成像素级的proposal,然后生成小段的局部跟踪轨迹,再生成全局跟踪。其中没有什么太多的创新,可以多学习tricks。
总结我们本篇主要针对VIS话题进行了盘点,由于这是2019年新出的计算机视觉task,一切都没有定论,该方向将多个任务结合,在未来当这些子方向做到瓶颈的时候,很有可能会成为主流方向。
就算法方面,我们发现,大家都不约而同的采用了"Mask R-CNN + 跟踪模块"的形式,跟踪模块也多以全连接层实现,以一种最简单的逻辑实现了跟踪。未来的方向应该会有更多样式的方法提出,期待后续的成果出现。
Unsupervised :任务是查找和分割视频中的主要目标,因为没有监督,算法自行决定主分割是什么。
Semi-supervised:只给出视频第一帧的正确分割掩膜,然后在之后的每一连续帧中像素级分割标注的目标,实际就是像素级的目标追踪问题。Semi-supervised又可以细分为单目标分割和多目标分割。
评价指标、竞赛、数据集1.评价指标
VOS的评价指标
分割的准确率主要有两个标准:
区域相似度(Region Similarity):区域相似度是掩膜 M 和真值 G 之间的 Intersection over Union 函数
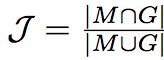
轮廓精确度(Contour Accuracy):将掩膜看成一系列闭合轮廓的集合,并计算基于轮廓的 F 度量,即准确率和召回率的函数。即轮廓精确度是对基于轮廓的准确率和召回率的 F 度量。
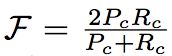
直观上,区域相似度度量标注错误像素的数量,而轮廓精确度度量分割边界的准确率。
VIS的评价指标
以像素的AP(平均精准率)和AR(平均召回率)为评价依据。(来源于《Video instance segmentation》)
这里视频的IOU与图像的IOU略有不同,定义为如下
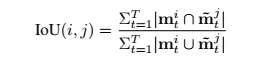
MOTS的评价指标
以MOT的评价指标MOTA为原型,进行改进,得到——sMOTSA,
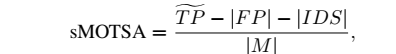
具体参看《MOTS: Multi-Object Tracking and Segmentation》。
2.数据集和挑战
VOS数据集
1、DAVIS-2016和DAVIS-2017,链接 http://davischallenge.org/code.html
2、DAVIS挑战赛官网链接 http://davischallenge.org/
3、GyGO: E-commerce Video Object Segmentation by Visualead,电商视频目标分割数据集,链接 https://github.com/ilchemla/gyg
VIS数据集
YouTube - VIS
MOTS数据集
基于KITTI MOTS改造的数据集 。
基于MOTSChallenge Datasets改造的数据集。
(具体可参见《MOTS: Multi-Object Tracking and Segmentation》)
1.《深度学习从入门到放弃之CV-video segmentation综述》https://zhuanlan.zhihu.com/p/32247505
2.《Video Instance Segmentation》-2019-ICCV
3.《MOTS: Multi-Object Tracking and Segmentation》 -2019-CVPR
4.《UnOVOST: Unsupervised Offline Video Object Segmentation and Tracking forthe 2019 Unsupervised DAVIS Challenge》 -2019-DAVIS Challenge
作者:一个假的日更博主