论文解读:DTMT: A Novel Deep Transition Architecture for Neural Machine Translation
本文为一篇神经机器翻译的文章,发表在2019AAAI会议上,主要提出一种深度转移网络(Deep Transition),结合多头注意力解决循环神经网络中同一层不同时刻之间shallow的问题。
一、简要信息| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | DTMT |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 神经机器翻译 |
| 4 | 核心内容 | Deep Transition RNMT, GRU, Multi-Head Attention |
| 5 | GitHub源码 | https://github.com/fandongmeng/StackedDTMT |
| 6 | 论文PDF | https://arxiv.org/pdf/1812.07807 |
Encoder-Decoder为主的神经网络结构在机器翻译任务中有重大的突破,先前诸多工作都是以Encoder-Decoder为主,一般地Encoder是用于对原始句子source sentence进行特征表示,将句子映射为一定长度的向量;Decoder则是根据对应的向量以及当前已经预测的单词来生成下一个单词,即所谓的自回归模型。Decoder部分的主要目标则是:
p(y∣x)=∏t=1mp(yt∣y<t,x;θ)p(\mathbf{y}|\mathbf{x}) = \prod_{t=1}^{m}p(y_t|\mathbf{y}_{<t},\mathbf{x};\theta)p(y∣x)=t=1∏mp(yt∣y<t,x;θ)
通常Encoder和Decoder可以选择CNN、RNN、Transformer等模型。本文作者认为以RNN为代表的递归神经机器翻译(RNMT)具有更大的潜力。不过在很多RNN为主的表征过程中,通常通过堆叠多层RNN来挖掘句子信息,换句话说,整个递归过程中,每一个时刻的深度可以通过多层RNN实现,但是对于时刻之间的转移却非常浅。这一问题在许多其他先前工作中也被提出。例如LAU( Linear Associative Unit)提出降低递归单元内部的梯度路径。
本文提出一种以GRU为主的深度转移递归神经网络模型,Encoder和Decoder均采用该网络模型分别用于编码和解码,Encoder和Decoder通过多头注意力模型相连。
2.1 GRU & T-GRU & L-GRUGRU是一种带有门控机制的RNN网络。其输入包括当前时刻 ttt 的单词input embedding以及上一时刻 t−1t-1t−1 的隐状态,输出则是当前时刻 ttt 的隐状态。没个时刻的隐状态则通过重置门(Reset Gate)和更新门(Update Gate)来控制。公式如下:
ht=(1−zt)⊙ht−1+zt⊙h^th_t=(1-z_t)\odot h_{t-1}+z_t\odot \hat{h}_tht=(1−zt)⊙ht−1+zt⊙h^t
h^t=tanh(Wxhxt+rt⊙(Whhht−1))\hat{h}_t = tanh(W_{xh}x_t+r_t\odot (W_{hh}h_{t-1}))h^t=tanh(Wxhxt+rt⊙(Whhht−1))
rt=σ(Wxrxt+Whrht−1)r_t = \sigma(W_{xr}x_t + W_{hr}h_{t-1})rt=σ(Wxrxt+Whrht−1)
zt=σ(Wxzxt+Whzht−1)z_t = \sigma(W_{xz}x_t + W_{hz}h_{t-1})zt=σ(Wxzxt+Whzht−1)
其中 ht−1h_{t-1}ht−1 表示上一时刻的隐状态,h^t\hat{h}_th^t 表示当前时刻更新的信息,其取决于当前的input embedding 和隐状态 ht−1h_{t-1}ht−1 。rt,ztr_t,z_trt,zt 分别表示重置门和更新门,σ\sigmaσ 表示softmax函数。
T-GRU是一种特殊的GRU,其不同于GRU的是其只有一个输入,且为隐状态,因此更新信息 h^t\hat{h}_th^t 以及两个门只与隐状态 ht−1h_{t-1}ht−1 有关。公式如下:
ht=(1−zt)⊙ht−1+zt⊙h^th_t=(1-z_t)\odot h_{t-1}+z_t\odot \hat{h}_tht=(1−zt)⊙ht−1+zt⊙h^t
h^t=tanh(rt⊙(Whhht−1))\hat{h}_t = tanh(r_t\odot (W_{hh}h_{t-1}))h^t=tanh(rt⊙(Whhht−1))
rt=σ(Whrht−1)r_t = \sigma(W_{hr}h_{t-1})rt=σ(Whrht−1)
zt=σ(Whzht−1)z_t = \sigma(W_{hz}h_{t-1})zt=σ(Whzht−1)
L-GRU是带有对输入单词input embedding线性变换的“增强版”GRU,L即代表linear。其不同于GRU的在于其输入部分包括三个,前两个与GRU相同,第三个则为input embedding的线性变换 H(xt)H(x_t)H(xt),门控单元也增加了一个线性变换门 ltl_tlt。公式如下:
ht=(1−zt)⊙ht−1+zt⊙h^th_t=(1-z_t)\odot h_{t-1}+z_t\odot \hat{h}_tht=(1−zt)⊙ht−1+zt⊙h^t
h^t=tanh(Wxhxt+rt⊙(Whhht−1)+lt⊙H(xt))\hat{h}_t = tanh(W_{xh}x_t+r_t\odot (W_{hh}h_{t-1}) + l_t\odot H(x_t))h^t=tanh(Wxhxt+rt⊙(Whhht−1)+lt⊙H(xt))
rt=σ(Wxrxt+Whrht−1)r_t = \sigma(W_{xr}x_t + W_{hr}h_{t-1})rt=σ(Wxrxt+Whrht−1)
zt=σ(Wxzxt+Whzht−1)z_t = \sigma(W_{xz}x_t + W_{hz}h_{t-1})zt=σ(Wxzxt+Whzht−1)
lt=σ(Wxlxt+Whlht−1)l_t = \sigma(W_{xl}x_t + W_{hl}h_{t-1})lt=σ(Wxlxt+Whlht−1)
2.2 Deep Transition RNNDTRNN主要在不同时刻之间添加深度的网络,相比stack RNN是在纵向加深,DTRNN则是横向加深。如图所示:
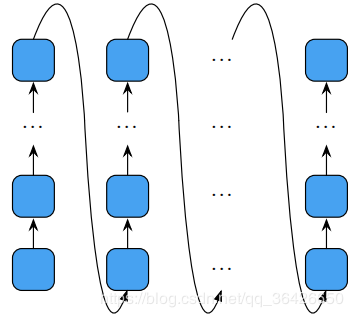
参考文献【1】率先将深度转移网路引入到机器翻译任务中,其通过在不同时刻的隐状态之间使用一个前馈网路来试图提高相邻状态结点之间的深度。现如今诸多工作也受到DTRNN的启发,例如BiDeep RNN。
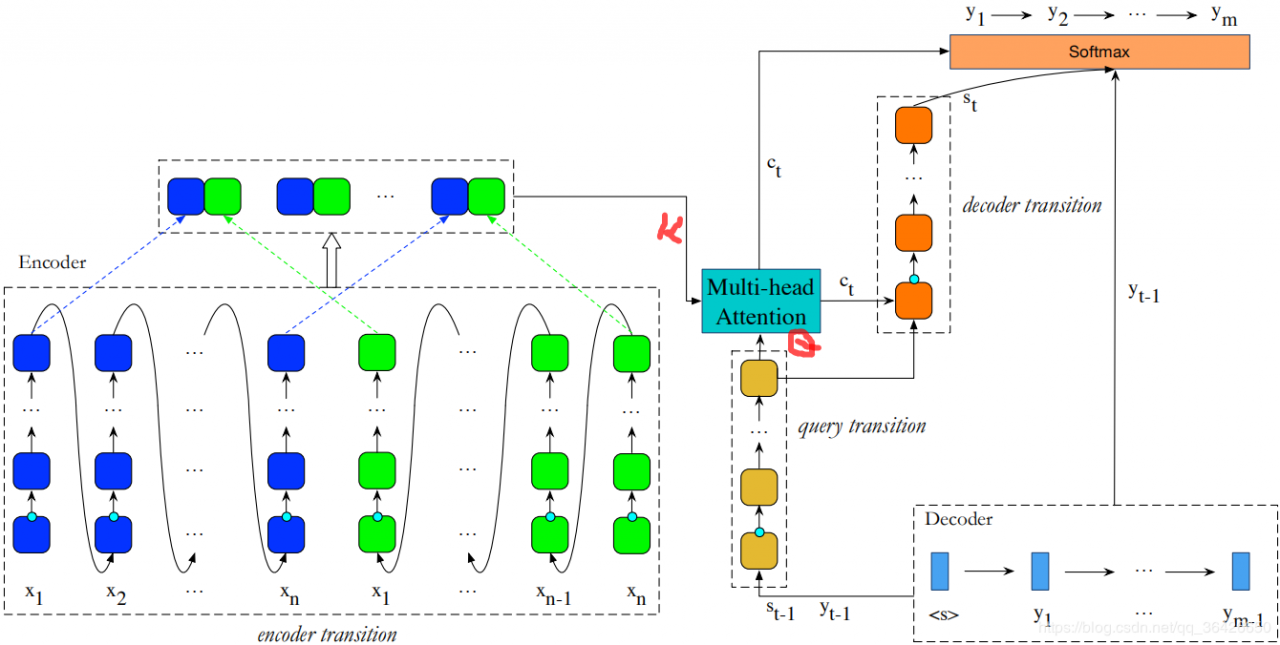
模型分为编码器和解码器,其中编码器为encoder transition,解码器为query transition和decoder transition。编码器和解码器之间通过multi-head attention相连。
如上图左,编码器为一个双向DTRNN,对于每一个时刻,先由L-GRU将上一时刻状态以及当前的input embedding和线性变换作为输入,其次逐个由T-GRU进行循环,假设DTRNN的深度为 LsL_sLs,前向传播公式为:
h→j,0=L−GRU(xj,h→j−1,Ls)\overrightarrow{h}_{j,0} = L-GRU(\mathbf{x}_j,\overrightarrow{h}_{j-1,L_s})hj,0=L−GRU(xj,hj−1,Ls)
h→j,k=T−GRUk(h→j,k−1)\overrightarrow{h}_{j,k} = T-GRU_k(\overrightarrow{h}_{j,k-1})hj,k=T−GRUk(hj,k−1)
其中k∈[1,Ls]k\in [1,L_s]k∈[1,Ls],反向传播公式仅改变箭头即可 。在实验过程中,L-GRU和T-GRU中的参数是共享的。每一个时刻的输出为 C={[h→j,Ls,h←j,Ls]}C=\{[\overrightarrow{h}_{j,L_s},\overleftarrow{h}_{j,L_s}]\}C={[hj,Ls,hj,Ls]}
3.2 L-GRU+T-GRU for decoder解码器部分包含query transition和decoder transition。假设两个部分的DTRNN深度分别为LqL_qLq和LdL_dLd,
st,0=L−GRU(yt−1,st−1,Lq+Ld+1)s_{t,0} = L-GRU(\mathbf{y}_{t-1}, \mathbf{s}_{t-1, L_q+L_d+1})st,0=L−GRU(yt−1,st−1,Lq+Ld+1)
st,k=T−GRU(st,k−1)s_{t,k} = T-GRU(\mathbf{s}_{t, k-1})st,k=T−GRU(st,k−1)
其中k∈[a,Lq]k\in [a,L_q]k∈[a,Lq]。这部分是将decoder部分t−1t-1t−1时刻的输出作为输入,以及上一时刻预测的单词 yt\mathbf{y}_tyt作为输入,输出则是L-GRU,再由query transition中的T-GRU进行循环编码。输出部分则与编码器的输出一起喂入一个多头注意力中:
ct=Multi−HeadAttention(C,st,Lq)c_t=Multi-HeadAttention(C,s_{t,L_q})ct=Multi−HeadAttention(C,st,Lq)
多头注意力模型与Transformer的一致,这里不细提。其输出部分则作为decoder transition的输入,另外decoder transition的输入还包括query transition最后一层的T-GRU的输出:
st,Lq+1=L−GRU(ct,st,Lq)s_{t,L_q+1} = L-GRU(c_t, s_{t,L_q})st,Lq+1=L−GRU(ct,st,Lq)
st,Lq+p=T−GRU(st,LLq+p−1)s_{t,L_q+p} = T-GRU(s_t, L_{L_q+p-1})st,Lq+p=T−GRU(st,LLq+p−1)
其中 p∈[2,Lq+1]p\in [2,L_q+1]p∈[2,Lq+1] 。
因此总的来说,在解码过程中,query transition是为了将上一时刻的预测词进行一次深度编码为查询器,用这个查询器从编码器中查询下一个可能的词的隐特征,查询的过程则是使用多头注意力实现alignment对齐,然后通过decoder transition将这个词的隐特征解码并通过full connection映射到标签分布上。
作者在(中文-英文),(英文-德文),(英文-法文)三个任务上进行了实验,同时实施消融实验(Ablation)验证L-GRU和T-GRU以及结合使用的效果。作者在实验中还使用了dropout用于防止过拟合,label smoothing做标签平滑处理(不采用0-1独热编码,对于其他类都有非0的很小的概率),层级正则化以及位置表征。
【1】 Deep architectures for neural machine translation
作者:华师数据学院·王嘉宁